

Алгоритм DIC, Dynamic Itemset Counting (S. Brin R. Motwani, J. Ullman and S. Tsur, 1997 год). Алгоритм разбивает базу данных на несколько блоков, каждый из которых отмечается так называемыми "начальными точками" (start point), и затем циклически сканирует базу данных [64].
Пример решения задачи поиска ассоциативных правил
Дана транзакционная база данных, необходимо найти наиболее часто встречающиеся наборы товаров и набор ассоциативных правил с определенными границами значений поддержки и доверия.
Рассмотрим процесс построения ассоциативных правил в аналитическом пакете Deductor.
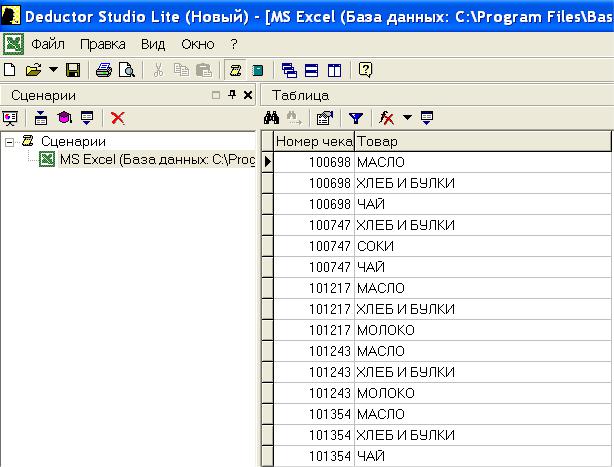
Транзакционная база данных, которая содержит в каждой записи номер чека и товар, приобретенный по этому чеку, имеет формат MS Excel. Для начала импортируем данные из файла MS Excel в среду Deductor, этот процесс аналогичен тому, что был рассмотрен в лекции о нейронных сетях. Единственное отличие - в назначении столбцов. Для номера транзакции (обычно в базе данных - это поле "номер чека") указываем тип "идентификатор транзакции (ID)", а для наименований товара - тип "элемент". Результат импорта базы данных из файла MS Excel в среду Deductor видим на рис. 15.2. На рисунке приведен фрагмент базы данных, которая содержит более 140 записей.
Рис. 15.2. Транзакционная база данных, импортированная в Deductor из файла MS Excel
178
Далее вызываем мастер обработки и выбираем метод "Ассоциативные правила". На втором шаге мастера проверяем назначения исходных столбцов данных, они должны иметь тип "ID" и "элемент".
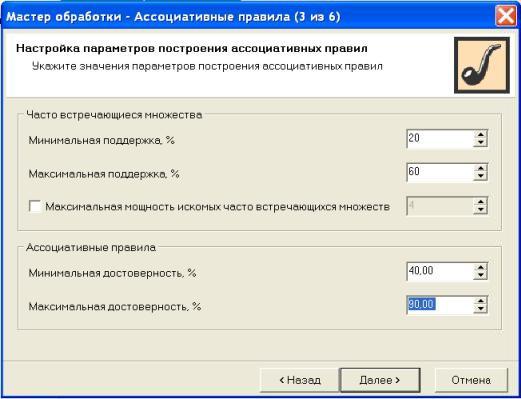
На третьем шаге, проиллюстрированном на рис. 15.3, необходимо настроить параметры поиска правил, т.е. установить минимальные и максимальные характеристики поддержки и достоверности. Это наиболее "ответственный" момент формирования набора правил, о важности выбора границ значений поддержки и достоверности уже говорилось в начале лекции. Выбор можно сделать на основе каких-либо соображений, имеющегося опыта анализа подобных данных, интуиции или же определить в ходе экспериментов.
Рис. 15.3. Настройка параметров построения ассоциативных правил
Мы установим такие границы для параметров поиска: минимальный и максимальный уровень поддержки равны 20% и 60% соответственно, минимальный и максимальный уровень значения достоверности равны 40% и 90% соответственно. Эти значения были выявлены в ходе проведения нескольких экспериментов, и оказалось, что именно при таких значениях формируется требуемый набор правил. При указании некоторых значений, например, уровня поддержки от 30% до 50%, набор правил не формируется, поскольку ни одно правило по параметрам поддержки не входит в этот интервал.
На следующем шаге мастера запускается процесс поиска ассоциативных правил. В результате видим информацию о количестве множеств и найденных правил в виде гистограммы распределения часто встречающихся множеств по их мощности. Данный процесс проиллюстрирован на рис. 15.4.
179
Рис. 15.4. Процесс построения ассоциативных правил
Здесь мы видим, что количество сформированных множеств равно тринадцати - это популярные наборы, количество сформированных правил - пятнадцать.
На следующем шаге для просмотра полученных результатов предлагается выбрать визуализаторы из списка; мы выберем такие: "Популярные наборы", "Правила", "Дерево правил", "Что-если". Рассмотрим, что они из себя представляют.
Визуализатор "Популярные наборы". Популярные наборы или часто встречающиеся наборы - это наборы, состоящие из одного или нескольких товаров, которые в транзакциях наиболее часто встречаются одновременно. Характеристикой, насколько часто набор встречается в анализируемом наборе данных, является поддержка.
Популярные наборы нашего набора данных, найденные при заданных параметрах, приведены в таблице 15.3. Есть возможность отсортировать данную таблицу по разным ее характеристикам. Для определения наиболее популярных товаров и их наборов удобно отсортировать ее по уровню поддержки. Таким образом, мы видим, что наибольшей популярностью пользуются такие товары: хлеб и булки, масло, соки.
N |
Множество |
Поддержка |
|
|
|
||
|
|
% |
Кол-во |
|
|
|
|
6 |
ХЛЕБ И БУЛКИ |
54,55 |
24 |
|
|
|
|
180
3 |
МАСЛО |
52,27 |
23 |
5 |
СОКИ |
50,00 |
22 |
10 |
МАСЛО И ХЛЕБ И БУЛКИ |
45,45 |
20 |
4 |
МОЛОКО |
43,18 |
19 |
2 |
КЕФИР |
31,82 |
14 |
1 |
ЙОГУРТЫ |
31,82 |
14 |
12 |
СОКИ И ХЛЕБ И БУЛКИ |
22,73 |
10 |
11 |
МОЛОКО И ХЛЕБ И БУЛКИ |
22,73 |
10 |
8 |
МАСЛО И МОЛОКО |
22,73 |
10 |
7 |
ЙОГУРТЫ И КЕФИР |
22,73 |
10 |
13 |
МАСЛО И МОЛОКО И ХЛЕБ И БУЛКИ |
20,45 |
9 |
9 |
МАСЛО И СОКИ |
20,45 |
9 |
|
|
|
|
Визуализатор "Правила"
Правила в данном визуализаторе размещены в виде списка. Каждое правило, представленное как "условие-следствие", характеризуется значением поддержки в абсолютном и процентном выражении, а также достоверностью. Таким образом, аналитик видит поведение покупателей, описанное в виде набора правил. Набор правил для решаемой нами задачи приведен в таблице 15.4. Например, первое правило говорит о том, что если покупатель купил йогурт, то с достоверностью или вероятностью 71% он купит также кефир. Эта информация полезна с различных точек зрения. Она, например, помогает решить задачу расположения товаров в магазине.
|
|
|
Поддержка |
|
|
N |
Условие |
Следствие |
|
|
Достоверность, % |
|
|
|
% |
Кол-во |
|
|
|
|
|
|
|
1 |
ЙОГУРТЫ |
КЕФИР |
22,73 |
10 |
71,43 |
2 |
КЕФИР |
ЙОГУРТЫ |
22,73 |
10 |
71,43 |
3 |
МАСЛО |
МОЛОКО |
22,73 |
10 |
43,48 |
4 |
МОЛОКО |
МАСЛО |
22,73 |
10 |
52,63 |
5 |
СОКИ |
МАСЛО |
20,45 |
9 |
40,91 |
|
|
|
|
|
|
181
6 |
МАСЛО |
ХЛЕБ И БУЛКИ |
45,45 |
20 |
86,96 |
7 |
ХЛЕБ И БУЛКИ |
МАСЛО |
45,45 |
20 |
83,33 |
8 |
МОЛОКО |
ХЛЕБ И БУЛКИ |
22,73 |
10 |
52,63 |
9 |
ХЛЕБ И БУЛКИ |
МОЛОКО |
22,73 |
10 |
41,67 |
10 |
СОКИ |
ХЛЕБ И БУЛКИ |
22,73 |
10 |
45,45 |
11 |
ХЛЕБ И БУЛКИ |
СОКИ |
22,73 |
10 |
41,67 |
12 |
МАСЛО И МОЛОКО |
ХЛЕБ И БУЛКИ |
20,45 |
9 |
90,00 |
13 |
МАСЛО И ХЛЕБ И БУЛКИ |
МОЛОКО |
20,45 |
9 |
45,00 |
14 |
МОЛОКО И ХЛЕБ И БУЛКИ |
МАСЛО |
20,45 |
9 |
90,00 |
15 |
МОЛОКО |
МАСЛО И ХЛЕБ И БУЛКИ |
20,45 |
9 |
47,37 |
|
|
|
|
|
|
При большом количестве найденных правил и широком ассортименте товаров анализировать полученные правила достаточно сложно. Для удобства анализа таких наборов правил предлагаются визуализаторы "Дерево правил" и "Что-если".
Визуализатор "Дерево правил" представляет собой двухуровневое дерево, которое может быть построено по двум критериям: по условию и по следствию. Если дерево построено по условию, то вверху списка отображается условие правила, а список, прилагающийся к данному условию, состоит из его следствий. При выборе определенного условия, в правой части визуализатора отображаются следствия условия, уровень поддержки и достоверности.
В случае построения дерева по следствию, вверху списка отображается следствие правила, а список состоит из его условий. При выборе определенного следствия, в правой части визуализатора мы видим условия этого правила с указанием уровня поддержки и достоверности.
Визуализатор "что-если" удобен, если нам необходимо ответить на вопрос, какие следствия могут получиться из данного условия.
Например, выбрав условие "МОЛОКО", в левой части экрана получаем три следствия "МАСЛО", "ХЛЕБ И БУЛКИ", "МАСЛО И ХЛЕБ И БУЛКИ", для которых указаны уровень поддержки и достоверности. Этот визуализатор представлен на рис. 15.5.
182

Рис. 15.5. Визуализатор "Что-если"
Рассмотренный пример поиска ассоциативных правил является типичной иллюстрацией задачи анализа покупательской корзины. В результате ее решения определяются часто встречающиеся наборы товаров, а также наборы товаров, совместно приобретаемые покупателями. Найденные правила могут быть использованы для решения различных задач, в частности для размещения товаров на прилавках магазинов, предоставления скидок на пары товаров для повышения объема продаж и, следовательно, прибыли и других задач.
183