

Пример решения задачи
Программное обеспечение, позволяющее работать с картами Кохонена, сейчас представлено множеством инструментов. Это могут быть как инструменты, включающие только реализацию метода самоорганизующихся карт, так и нейропакеты с целым набором структур нейронных сетей, среди которых - и карты Кохонена; также данный метод реализован в некоторых универсальных инструментах анализа данных.
К инструментарию, включающему реализацию метода карт Кохонена, относятся SoMine, Statistica, NeuroShell, NeuroScalp, Deductor и множество других. Для решения задачи будем использовать аналитический пакет Deductor.
Пусть имеется база данных коммерческих банков с показателями деятельности за текущий период. Необходимо провести их кластеризацию, т.е. выделить однородные группы банков на основе показателей из базы данных, всего показателей - 21.
Исходная таблица находится в файле "banks.xls". Она содержит показатели деятельности коммерческих банков за отчетный период.
Сначала импортируем данные из xls-файла в среду аналитического пакета.
На первом шаге мастера запускаем мастер обработки и выбираем из списка метод обработки "Карта Кохонена". Далее следует настроить назначения столбцов, т.е. для каждого столбца выбрать одно из назначений: входное, выходное, не используется и информационное. Укажем всем столбцам, соответствующим показателям деятельности банков, назначение "Входной". "Выходной" не назначаем.
Следующий шаг предлагает разбить исходное множество на обучающее, тестовое и валидационное. По умолчанию,программа предлагает разбить множество на обучающее - 95% и тестовое - 5%.
Эти шаги аналогичны шагам в мастере обработки для нейронных сетей, описанным в предыдущей Лекции.
На шаге № 5, изображенном на рис. 12.4 предлагается настроить параметры карты: количество ячеек по Х и по Y их форму (шестиугольную или четырехугольную).
141
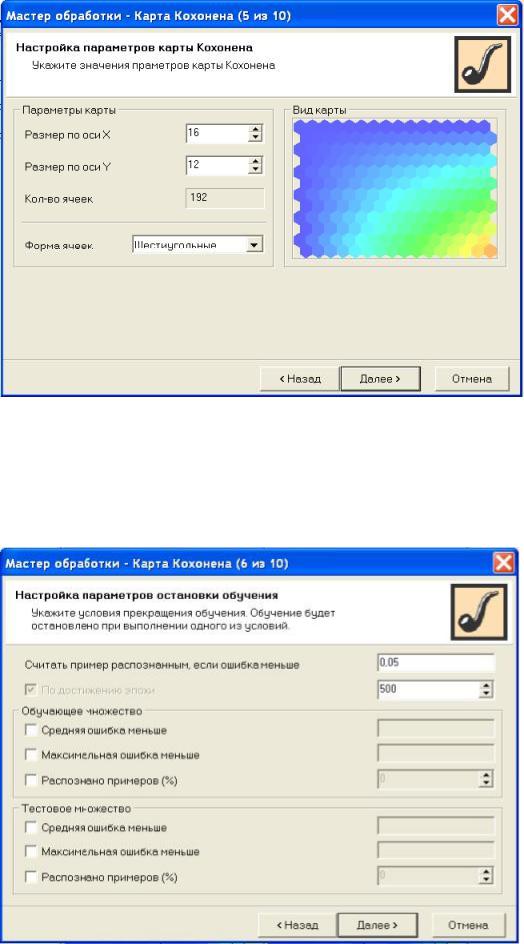
Рис. 12.4. Шаг № 5 "Настройка параметров карты Кохонена"
На шестом шаге "Настройка параметров остановки обучения", проиллюстрированном на рис. 12.5, устанавливаем параметры остановки обучения и устанавливаем эпоху, по достижению которой обучение будет прекращено.
142

Рис. 12.5. Шаг № 6 "Настройка параметров остановки обучения"
На седьмом шаге, представленном на рис. 12.6, настраиваются другие параметры обучения: способ начальной инициализации, тип функции соседства. Возможны два варианта кластеризации: автоматическое определение числа кластеров с соответствующим уровнем значимости и фиксированное количество кластеров (определяется пользователем). Поскольку нам неизвестно количество кластеров, выберем автоматическое определение их количества.
Рис. 12.6. Шаг № 7 "Настройка параметров остановки обучения"
На восьмом шаге запускаем процесс обучения сети - необходимо нажать на кнопку "Пуск" и дождаться окончания процесса обучения. Во время обучения можем наблюдать изменение количества распознанных примеров и текущие значения ошибок. Этот процесс аналогичен тому, что мы рассматривали при обучении нейронных сетей в предыдущей лекции.
По окончании обучения в списке визуализаторов выберем "Карту Кохонена" и визуализатор "Что-если". На последнем шаге настраиваем отображения карты Кохонена, этот шаг проиллюстрирован на рис. 12.7.
143
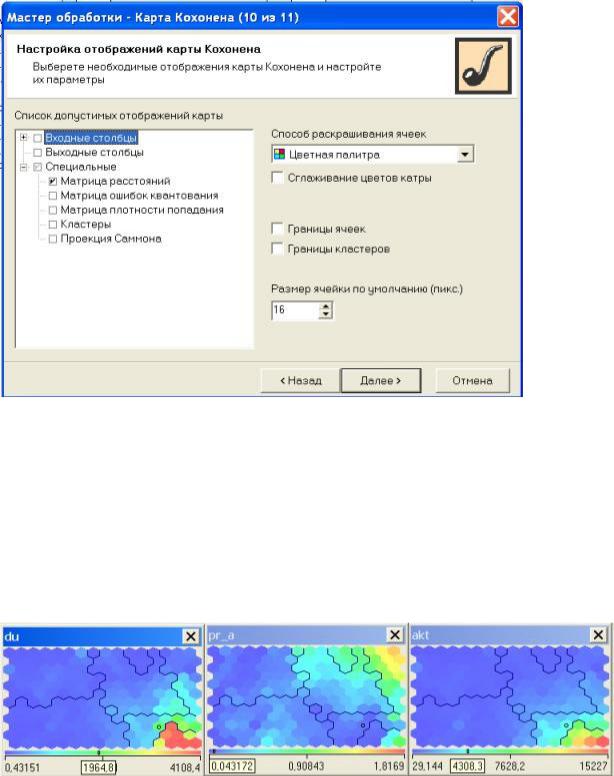
Рис. 12.7. "Шаг № 10 Настройка отображений карты Кохонена"
Укажем отображения всех входных, выходных столбцов, кластеров, а также поставим флажок "Границы кластеров" для четкого отображения границ.
Карты входов
При анализе карт входов рекомендуют использовать сразу несколько карт. Исследуем фрагмент карты, состоящий из карт трех входов, который приведен на рис. 12.8
Рис. 12.8. Карты трех входов
На одной из карт выделяем область с наибольшими значениями показателя. Далее имеет смысл изучить эти же нейроны на других картах.
На первой карте наибольшие значения имеют объекты, расположенные в правом нижнем углу. Рассматривая одновременно три карты, мы можем сказать, что эти же объекты
144
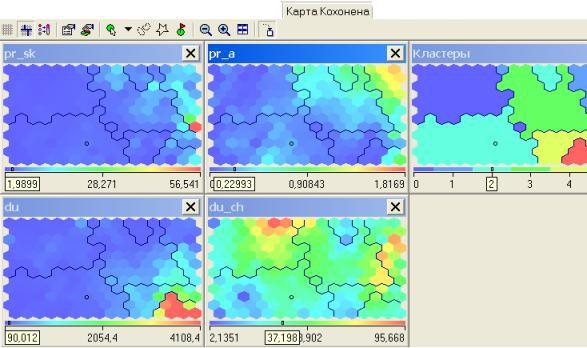
имеют наибольшие значения показателя, изображенного на третьей карте. Также по раскраске первой и третьей карты можно сделать вывод, что существует взаимосвязь между этими показателями.
Также мы можем определить, например, такую характеристику: кластер, расположенный в правом верхнем углу, характеризуется низкими значениями показателей du (депозиты юридических лиц) и akt (активы банка) и высокими значениями показателей pr_a (прибыльность активов).
Эта информация позволяет так охарактеризовать кластер, находящийся в правом верхнем углу: это банки с небольшими активами, небольшими привлеченными депозитными средствами от юридических лиц, но с наиболее прибыльными активами, т.е. это группа небольших, но наиболее прибыльных банков.
Это лишь фрагмент вывода, который можно сделать, исследуя карту.
На следующем рисунке (рис. 12.9) приведена иллюстрация карт входов и выходов, последняя - эта карта кластеров. Здесь мы видим несколько карт входов (показателей деятельности банков) и сформированные кластеры, каждый из которых выделен отдельным цветом.
Рис. 12.9. Карты входов и выходов
Для нахождения конкретного объекта на карте необходимо нажать правой кнопкой мыши на исследуемом объекте и выбрать пункт "Найти ячейку на карте". Выполнение этой процедуры показано на рис. 12.10. В результате мы можем видеть как сам объект, так и значение того измерения, которое мы просматриваем. Таким образом, мы можем оценить положение анализируемого объекта, а также сравнить его с другими объектами.
145