


Методы классификации и прогнозирования. Метод опорных векторов. Метод "ближайшего соседа". Байесовская классификация
В предыдущих лекциях мы рассмотрели такие методы классификации и прогнозирования как линейная регрессия и деревья решений; в этой лекции мы продолжим знакомство с методами этой группы и рассмотрим следующие из них: метод опорных векторов, метод ближайшего соседа (метод рассуждений на основе прецедентов) и байесовскую классификацию.
Метод опорных векторов
Метод опорных векторов (Support Vector Machine - SVM) относится к группе граничных методов. Она определяет классы при помощи границ областей.
При помощи данного метода решаются задачи бинарной классификации.
В основе метода лежит понятие плоскостей решений.
Плоскость (plane) решения разделяет объекты с разной классовой принадлежностью.
На рис.10.1 приведен пример, в котором участвуют объекты двух типов. Разделяющая линия задает границу, справа от которой - все объекты типа brown (коричневый), а слева - типа yellow (желтый). Новый объект, попадающий направо, классифицируется как объект класса brown или - как объект класса yellow, если он расположился по левую сторону от разделяющей прямой. В этом случае каждый объект характеризуется двумя измерениями.
Рис. 10.1. Разделение классов прямой линией
Цель метода опорных векторов - найти плоскость, разделяющую два множества объектов; такая плоскость показана на рис. 10.2. На этом рисунке множество образцов поделено на два класса: желтые объекты принадлежат классу А, коричневые - классу В.
107
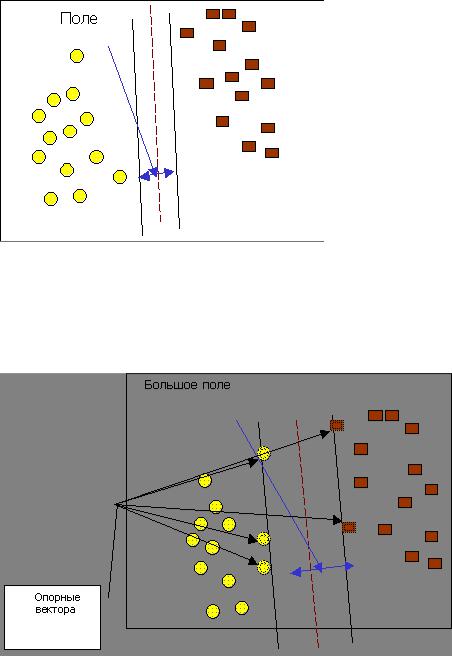
Рис. 10.2. К определению опорных векторов
Метод отыскивает образцы, находящиеся на границах между двумя классами, т.е. опорные вектора; они изображены на рис. 10.3.
Рис. 10.3. Опорные векторы
Опорными векторами называются объекты множества, лежащие на границах областей.
Классификация считается хорошей, если область между границами пуста.
На рис. 10.3.показано пять векторов, которые являются опорными для данного множества.
Линейный SVM
Решение задачи бинарной классификации при помощи метода опорных векторов заключается в поиске некоторой линейной функции, которая правильно разделяет набор данных на два класса. Рассмотрим задачу классификации, где число классов равно двум.
108
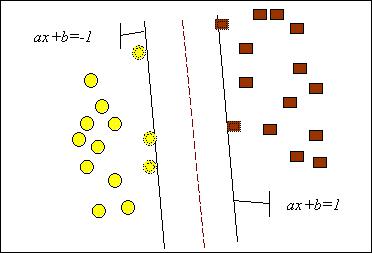
Задачу можно сформулировать как поиск функции f(x), принимающей значения меньше нуля для векторов одного класса и больше нуля - для векторов другого класса. В качестве исходных данных для решения поставленной задачи, т.е. поиска классифицирующей функции f(x), дан тренировочный набор векторов пространства, для которых известна их принадлежность к одному из классов. Семейство классифицирующих функций можно описать через функцию f(x). Гиперплоскость определена вектором а и значением b, т.е. f(x)=ax+b. Решение данной задачи проиллюстрировано на рис. 10.4.
В результате решения задачи, т.е. построения SVM-модели, найдена функция, принимающая значения меньше нуля для векторов одного класса и больше нуля - для векторов другого класса. Для каждого нового объекта отрицательное или положительное значение определяет принадлежность объекта к одному из классов.
Рис. 10.4. Линейный SVM
Наилучшей функцией классификации является функция, для которой ожидаемый риск минимален. Понятие ожидаемого риска в данном случае означает ожидаемый уровень ошибки классификации.
Напрямую оценить ожидаемый уровень ошибки построенной модели невозможно, это можно сделать при помощи понятия эмпирического риска. Однако следует учитывать, что минимизация последнего не всегда приводит к минимизации ожидаемого риска. Это обстоятельство следует помнить при работе с относительно небольшими наборами тренировочных данных.
Эмпирический риск - уровень ошибки классификации на тренировочном наборе.
Таким образом, в результате решения задачи методом опорных векторов для линейно разделяемых данных мы получаем функцию классификации, которая минимизирует верхнюю оценку ожидаемого риска.
Одной из проблем, связанных с решением задач классификации рассматриваемым методом, является то обстоятельство, что не всегда можно легко найти линейную границу между двумя классами.
109