

Data Mining консалтинг
В предыдущей лекции мы рассматривали инструменты Data Mining, которые можно приобрести на рынке готового программного обеспечения. Как мы уже упоминали ранее, существуют и другие варианты: заказ готового решения у фирмы-разработчика или адаптация программного обеспечения под конкретную задачу.
Различные варианты внедрения Data Mining имеют свои сильные и слабые стороны. Так, преимуществами готового программного обеспечения являются готовые алгоритмы, техническая поддержка производителя, полная конфиденциальность информации, а также не требуется дописывать программный код, существует возможность приобретения различных модулей и надстроек к используемому пакету, общение с другими пользователями пакета и др.
Однако, такое решение имеет и слабые стороны. В зависимости от инструмента, это может быть достаточно высокая стоимость лицензий на программное обеспечение, невозможность добавлять свои функции, сложность подготовки данных, практическое отсутствие в интерфейсе терминов предметной области и другие. Такое решение требует наличия высококвалифицированных кадров, которые смогут качественно подготовить данные к анализу, знают, какие алгоритмы следует применять для решения каких задач, сумеют проинтерпретировать полученные результаты в терминах решаемых бизнес-задач. Далеко не каждая компания может содержать штат таких специалистов, а зачастую их содержание даже неэффективно.
Представим ситуацию, когда менеджер сталкивается "один на один" с одним из продуктов, в котором реализованы методы технологии Data Mining (от самых простых, включающих 1-2 алгоритма, до полнофункциональных программных комплексов, предлагающих десятки различных алгоритмов). Перед ним стоит задача - выявить наиболее перспективных потенциальных клиентов, а он видит перед собой всего лишь набор математических алгоритмов: Это и есть "обратная сторона" использования готовых инструментов.
Таким образом, покупке готового инструмента должна предшествовать серьезная подготовка к внедрению Data Mining. Некоторые аспекты этой подготовки (ее организационные факторы) были описаны в предыдущем разделе курса.
Если описанные сложности не учтены при внедрении готового инструмента, компания может столкнуться с трудностями, не всегда преодолимыми, и, как результат - разочароваться в технологии Data Mining.
Далее мы рассмотрим другой вариант внедрения: воспользоваться Data Miningконсалтингом и/или так называемой адаптацией программного обеспечения под конкретную задачу.
Data Mining-услуги
По данным консалтинговой компании Meta Group, в мире не менее 85% рынка Data Mining занимают именно услуги, т.е. консультации по эффективному внедрению этой
318
технологии для решения актуальных бизнес-задач. На сайте KDnuggets можно найти перечень более ста известных компаний, занимающихся консалтингом в сфере Data Mining.
Одна из всемирно известных консалтинговых компаний в сфере Data Mining - компания Two Crows (www.twocrows.com). Она специализируется на публикации отчетности Data Mining, проводит образовательные семинары, консультирует пользователей и разработчиков Data Mining во всем мире. Одна из известных методологий Data Mining - методология, разработанная компанией Two Crows.
К консалтинговым Data Mining-компаниям относят и некоторых производителей готового программного обеспечения, продукцию некоторых мы рассмотрели в этом разделе курса:
∙IBM Global Business Intelligence Solutions, www.ibm.com/bi;
∙SAS Institute, www.sas.com/datamining;
∙SPSS, www.spss.com;
∙StatSoft, www.StatSoft.com.
Некоторые консалтинговые компании предоставляют свои услуги на определенных территориях. Это, например, компания Arvato Business Intelligence, www.arvatobi.fr, обеспечивающая Data Mining консультирование и моделирование во Франции, Германии, Испании и некоторых других европейских странах. Некоторые консалтинговые компании специализируются на предоставлении услуг в определенных предметных областях. Например, компания Blue Hawk LLC, www.bluehawk.biz, осуществляет Data Mining и предоставляет консультационные услуги в сферах Direct Marketing и CRM. Некоторые компании предоставляют услуги с использованием определенных методов Data Mining. Компания Bayesia, (www.bayesia.com), предоставляет консультирование и "настройку решения" под клиента на основе байесовской классификации. Компания Visual Analytics (www.visualanalytics.com) обеспечивает услуги по бизнес-консультированию для нахождения шаблонов с использованием визуального Data Mining.
Рассмотрим преимущества, которые имеет этот вариант внедрения Data Mining по сравнению с готовыми программными продуктами и их самостоятельным использованием.
Высококвалифицированные специалисты. Для эффективного применения технологии Data Mining требуются квалифицированные специалисты, которые сумеют качественно провести весь цикл анализа. Пока что таких грамотных специалистов на просторах СНГ очень немного, и потому они довольно дороги. Обучение же собственных, во-первых, достаточно рискованно (его с удовольствием переманит конкурент), во-вторых, выльется в немалые затраты (такие курсы стоят дорого). Клиенты, воспользовавшись услугами консалтинговой компании, получают доступ к высококлассным профессионалам компании, экономя при этом значительные средства на поиске или обучении собственных специалистов.
Адаптированность. Готовые продукты изначально предназначены для решения хотя и широкого, но все же стандартного и ограниченного круга задач - адаптация продукта к условиям конкретного бизнеса ложится на плечи сотрудников компании. Здесь перед заказчиком опять встанет упомянутая проблема квалифицированных специалистов. Консалтинговая компания предоставляет услуги, полностью адаптированные под бизнес заказчика и его задачи.
319
Гибкость инструмента - его возможность быстро подстроить программное обеспечение под нужды бизнеса:
∙возможность выбора наиболее удобных понятий, в терминах которых должны быть сформулированы знания или термины предметной области; так, анализируя конкурентов, действующих на рынке, их можно поделить на "сильных" и "слабых" или же на "агрессивных", "спокойных" и "пассивных" - в зависимости от того, что интересует аналитика в определенный момент. Соответственно, знания будут сформулированы в выбранных заказчиком терминах, и в итоге он получает решение именно в тех терминах, которые ему интересны и понятны.
∙получение осмысленных и понятных заказчику знаний в естественной форме. Использование адаптированного под конкретный бизнес программного обеспечения избавит пользователя от необходимости изучения формул или зависимостей в математической форме, а предоставит знания в наиболее интуитивном виде.
Итак, услуги по применению Data Mining становятся все более востребованными. Далее мы опишем практический опыт российской компании SnowCactus, предоставляющей услуги по применению Data Mining.
Компания SnowCactus разработала ряд решений на основе Data Mining разнообразных бизнес-задач [118], например:
∙анализ клиентов, выявление наиболее доходных и перспективных покупателей;
∙анализ и прогнозирование продаж продукции;
∙оптимизация работы с поставщиками;
∙оптимизация бюджета продвижения товаров;
∙формирование ассортимента;
∙оценка кредитоспособности заемщиков;
∙повышение эффективности подбора персонала.
Впроцессе решения каждой конкретной бизнес-задачи специалисты компании изучают имеющиеся в наличии данные и подбирают те математические алгоритмы, которые наиболее подходят для ее решения в данных условиях.
Работа с клиентом
На примере российской компании SnowCactus рассмотрим процедуру работы консалтинговой компании с клиентом. Комплекс услуг этой компании включает в себя планирование, организацию и осуществление полного цикла использования технологии Data Mining для бизнеса.
Весь цикл представлен на рис. 28.1. Он, по своей сути, является методологией Data Mining. Как уже упоминалось в предыдущих лекциях, методология Data Mining может быть разработана внутри организации, в соответствии с последовательностью работ, выполняемых в рамках аналитического процесса.
320
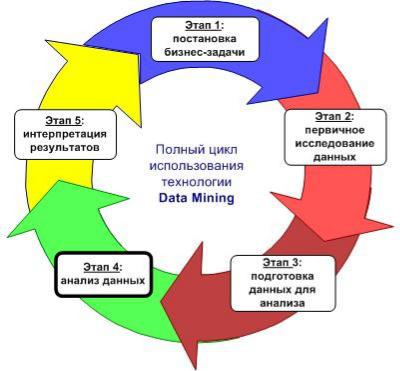
Рис. 28.1. Цикл использования технологии Data Mining в SnowCactus
Цикл состоит из пяти этапов.
Этап 1. Постановка бизнес-задачи
На первом этапе компания вместе с заказчиком формулирует конкретные бизнес-задачи. При первом прохождении этого цикла задача может быть поставлена довольно широко: например, построить профили высокоприбыльных клиентов или определить группы нелояльных покупателей. Во время дальнейших проходов поставленные задачи можно уточнять, расширять и углублять. При формулировании задачи компания учитывает наличие данных, необходимых для ее решения. На этом этапе специалисты компании наравне со специалистами клиента принимают непосредственное участие в процессе формулирования задач, избавляя клиента от технической необходимости ставить задачу в терминах технологии Data Mining.
Этап 2. Первичное исследование данных
После того как бизнес-задача сформулирована, специалисты компании приступают к предварительному исследованию данных, необходимых для решения поставленной задачи. Этот этап компания также практически полностью берет на себя - со стороны заказчика здесь может потребоваться лишь минимальное участие для выяснения, например, смысла исследуемых данных или формулирования интересных для него понятий.
Этап 3. Подготовка данных
321