

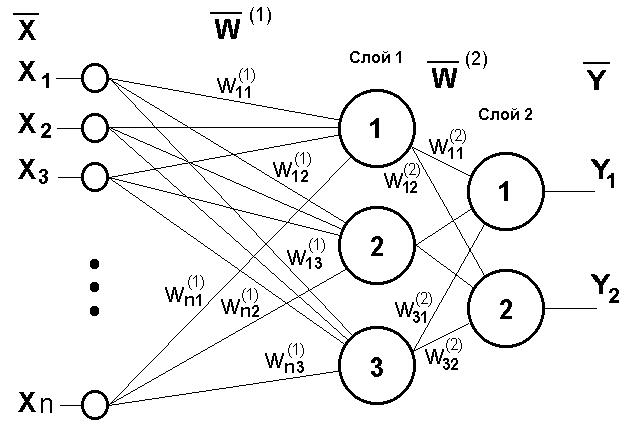
Рис. 11.4. Двухслойный перцептрон
Сеть, изображенная на рисунке, имеет n входов. На них поступают сигналы, идущие далее по синапсам на 3 нейрона, которые образуют первый слой. Выходные сигналы первого слоя передаются двум нейронам второго слоя. Последние, в свою очередь, выдают два выходных сигнала.
Метод обратного распространения ошибки (Back propagation, backprop) - алгоритм обучения многослойных персептронов, основанный на вычислении градиента функции ошибок. В процессе обучения веса нейронов каждого слоя нейросети корректируются с учетом сигналов, поступивших с предыдущего слоя, и невязки каждого слоя, которая вычисляется рекурсивно в обратном направлении от последнего слоя к первому.
Другие модели нейронных сетей будут рассмотрены в следующей лекции.
Программное обеспечение для работы с нейронными сетями
Программное обеспечение, имитирующее работу нейронной сети, называют нейросимулятором либо нейропакетом.
Большинство нейропакетов включают следующую последовательность действий:
∙Создание сети (выбор пользователем параметров либо одобрение установленных по умолчанию).
∙Обучение сети.
126

∙Выдача пользователю решения.
Существует огромное разнообразие нейропакетов, возможность использования нейросетей включена также практически во все известные статистические пакеты.
Среди специализированных нейропакетов можно назвать такие: BrainMaker, NeuroOffice, NeuroPro, и др.
Критерии сравнения нейропакетов: простота применения, наглядность представляемой информации, возможность использовать различные структуры, скорость работы, наличие документации. Выбор определяется квалификацией и требованиями пользователя.
Пример решения задачи
Рассмотрим решение задачи "Выдавать ли кредит клиенту" в аналитическом пакете Deductor (BaseGroup).
В качестве обучающего набора данных выступает база данных, содержащая информацию о клиентах, в частности: Сумма кредита, Срок кредита, Цель кредитования, Возраст, Пол, Образование, Частная собственность, Квартира, Площадь квартиры. На основе этих данных необходимо построить модель, которая сможет дать ответ, входит ли Клиент, желающий получить кредит, в группу риска невозврата кредита, т.е. пользователь должен получить ответ на вопрос "Выдавать ли кредит?". Задача относится к группе задач классификации, т.е. обучения с учителем.
Данные для анализа находятся в файле credit.txt. Импортируем данные из файла при помощи мастера импорта. Запускаем мастер обработки
и выбираем метод обработки данных - нейронная сеть. Задаем назначения исходных столбцов данных. Выходной столбец в нашей задаче - "Давать кредит", все остальные - входные. Этот шаг проиллюстрирован на рис. 11.5.
127
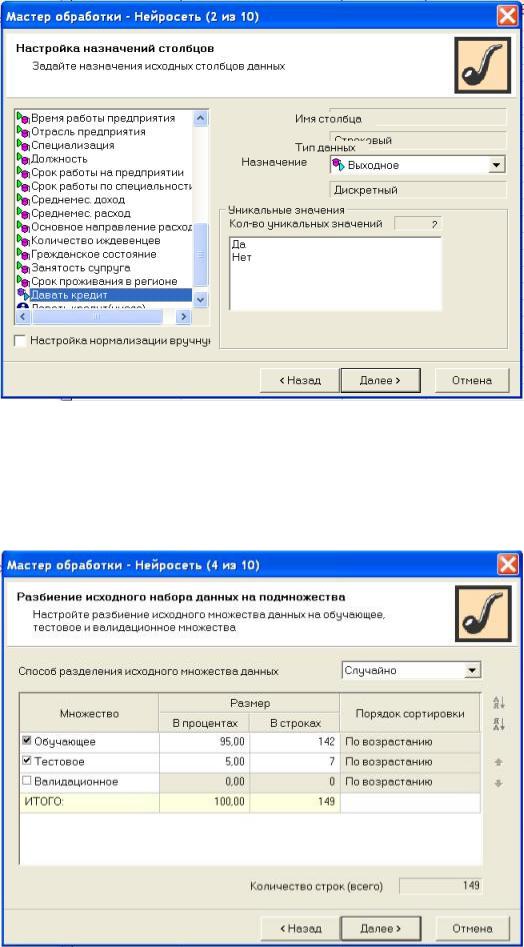
Рис. 11.5. Шаг "Настройка назначений столбцов"
На следующем шаге мастер предлагает разбить исходное множество данных на обучающее и тестовое. Способ разбиения исходного множества данных по умолчанию задан "Случайно". Этот шаг представлен на рис. 11.6.
128
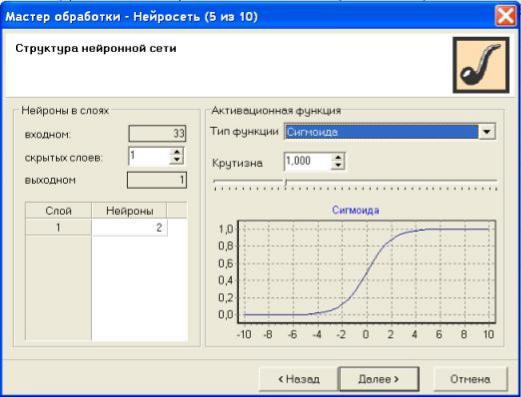
Рис. 11.6. Шаг "Разбиение исходного набора данных на подмножества"
На следующем шаге необходимо определить структуру нейронной сети, т.е. указать количество нейронов в входом слое - 33 (количество входных переменных), в скрытом слое - 1, в выходном слое - 1 (количество выходных переменных). Активационная функция - Сигмоида, и ее крутизна равна единице. Этот шаг проиллюстрирован на рис. 11.7.
Рис. 11.7. Шаг "Структура нейронной сети"
Далее выбираем алгоритм и параметры обучения нейронной сети. Этот шаг имеет название "Настройка процесса обучения нейронной сети", он представлен на рис. 11.8.
129
Рис. 11.8. Шаг "Настройка процесса обучения нейронной сети"
На следующем шаге настраиваем условия остановки обучения. Будем считать пример распознанным, если ошибка меньше 0,005, и укажем условие остановки обучения при достижении эпохи 10000.
На следующем шаге запускаем процесс обучения и наблюдаем за изменением величины ошибки и процентом распознанных примеров в обучающем и тестовом множествах. В нашем случае мы видим, что на эпохе № 4536 в обучающем множестве распознано 83,10% примеров, а на тестовом - 85,71% примеров. Фрагмент этого процесса проиллюстрирован на рис. 11.9.
130
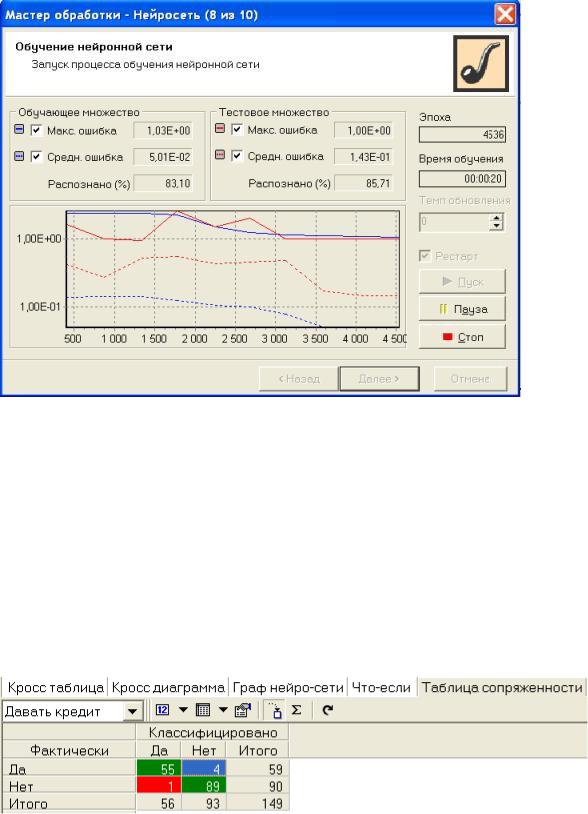
Рис. 11.9. Шаг "Обучение нейронной сети"
После окончания процесса обучения для интерпретации полученных результатов мы имеем возможность выбрать визуализаторы из списка предложенных. Выберем такие: таблица сопряженности, граф нейросети, анализ "что, если", и при помощи них проанализируем полученные данные [48].
На рис. 11.10 показана таблица сопряженности. По ее диагонали расположены примеры, которые были правильно распознаны, т.е. 55 клиентов, которым можно выдавать кредит, и 89 клиентов, которым выдавать кредит не стоит. В остальных ячейках расположены те клиенты, которые были отнесены к другому классу (1 и 4). Можно считать, что правильно классифицированы практически все примеры - 96,64%.
Рис. 11.10. Таблица сопряженности
Визуализатор "что-если" позволяет провести эксперимент. Данные по потенциальному получателю кредита следует ввести в соответствующие поля, и построенная модель
131