

Способы отбора данных в выборку
Для того, чтобы по выборке можно было делать вывод о свойствах генеральной совокупности, выборка должна быть репрезентативной (от франц. représentatif — представляющий собой что-либо, показательный), то есть она должна наиболее полно и адекватно представлять свойства генеральной совокупности. Репрезентативность может быть обеспечена только при объективности отбора данных. Основным условием этого является случайность. Выборка лишь тогда по-настоящему случайна, когда образовалась из генеральной совокупности таким образом, что каждый объект этой совокупности имел равную вероятность быть отобранным и на его включение или исключения не мог повлиять ни один фактор кроме случая.
Различают четыре способов отбора данных в выборку:
Простой случайный отбор – это способ отбора, при котором объекты извлекаются по одному из всей генеральной совокупности, а требование случайности достигается с помощью жребия, таблицы случайных чисел и т.д.
Типический отбор – это способ отбора, при котором генеральная совокупность делится на типические группы, а затем из каждой извлекается в случайном порядке одинаковое число объектов (или пропорционально населенности каждой группы).
Механический отбор – это способ отбора, при котором генеральная совокупность условно делится на такое число групп, сколько объектов должно войти в выборку, то есть выбор объектов производится через определенный интервал.
Серийный отбор – это способ отбора, при котором генеральная совокупность разбивается на серии, некоторые из которых изучаются целиком, то есть отбираются не отдельны объекты, а их группы.
Этапы статистических исследований
Статистическое наблюдение – представляет собой планомерный, научно обоснованный сбор данных, характеризующих изучаемый объект. Оно должно удовлетворять следующим требованиям:
объекты наблюдения должны быть одинаковыми с точки зрения их свойств (возраст, пол, специализация, квалификация и т.д.);
число объектов наблюдения должно быть достаточным, чтобы можно было выявить закономерности и обобщить их свойства (обычно не менее 30).
Статистическая сводка и группировка, является важной подготовительной частью к статистическому анализу и предусматривает:
систематизацию (группировку) данных;
оформление определенных статистических таблиц.
Анализ статистического материала проводится с использованием соответствующих математико-статистических методов.
ПЕРВОНАЧАЛЬНАЯ ОБРАБОТКА СТАТИСТИЧЕСКОГО МАТЕРИАЛА
Первоначальная обработка статистического материала
Сбор статистического материала – это весьма важный и ответственный этап статистического исследования. Однако, большая нагрузка и ответственность в исследовании падает на обработку и представление данных, так как от этого в значительной степени зависят те выводы, к которым придет исследователь в конце работы.
Собранные данные зачастую оказываются представленным в виде беспорядочного набора значений и по ним трудно выявить их изменения или закономерности. Поэтому для изучения закономерностей, полученные данные подвергают предварительной обработке.
Упорядочение (ранжирование) – это исходный этап первоначальной обработки, состоящий в систематизации объектов выборки, то есть в расположении их в какой-либо последовательности, удобной для дальнейшего анализа и рассмотрения.
Группировка – заключается в объединении вариант (объектов) в классы, по группам или интервалам группировки, границы которых устанавливаются произвольно и обязательно указываются. Группировка производится для того, чтобы построить эмпирическое распределение и сформировать с его помощью предположение о форме распределения изучаемого признака в генеральной совокупности из которой была взята выборка.
Первая задача, которую нужно решить при группировке, состоит в том, чтобы определить оптимальное число интервалов и установить длину (шаг) интервала. Это определяется в каждом случае отдельно с учетом конкретных задач исследования, объема выборки и степени варьирования признака в выборке. Однако, оптимальное число интервалов нужно выбрать так, чтобы в достаточной мере отразилось многообразие значений признака и закономерность распределения не искажалась случайным колебанием частот.
Если интервалов будет мало, то есть возможность упустить закономерности формы распределения, а если много – будет слишком много деталей, что мешает установить общие закономерности варьирования (изменения) признака.
Число интервалов (![]() )
устанавливают по формуле Стерджесса:
)
устанавливают по формуле Стерджесса:
![]() ,
,
где - объем выборки.
Для практики целесообразно использовать следующую таблицу:
Объем выборки ( ) |
Число интервалов ( ) |
10-24 |
4 |
25-40 |
5-6 |
41-60 |
6-8 |
61-100 |
7-10 |
101-200 |
8-12 |
Более 200 |
10-15 |
Выбрав число интервалов (классов), рассчитывают длину или шаг интервала:
![]() ,
,
где
![]() и
и
![]() - максимальное и минимальное значение
в выборке.
- максимальное и минимальное значение
в выборке.
Графическое представление.
Пример 1. В исследовании силовых способностей мышц верхних конечностей студентов 3 курса факультета физической культуры и спорта по тесту «Сгибание и разгибание рук в упоре на брусьях» были получены следующие данные:
12 |
20 |
25 |
12 |
12 |
20 |
24 |
20 |
25 |
23 |
10 |
15 |
11 |
24 |
11 |
36 |
29 |
30 |
20 |
32 |
10 |
9 |
18 |
17 |
26 |
40 |
22 |
23 |
21 |
22 |
Определим объем выборки
 .
.Упорядочим (ранжируем) результаты.
№ |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
|
9 |
10 |
10 |
11 |
11 |
12 |
12 |
12 |
15 |
17 |
18 |
20 |
20 |
20 |
20 |
|
21 |
22 |
22 |
23 |
23 |
24 |
24 |
25 |
25 |
26 |
29 |
30 |
32 |
36 |
40 |
![]() - варианта – любое значение
- варианта – любое значение
Определим число и шаг интервала.
![]()
![]()
Намечаем границы интервалов группировки
Нижняя граница первого интервала берется таким образом, чтобы минимальное значение попало примерно в середину интервала, притом, что все значения попадут в выбранное число интервалов. Если это не удается, то выбирается произвольно или равняется минимальному значению или увеличивается шаг интервала на минимально возможное значение.
Чтобы проверить все ли значения попадают внутрь диапазона сравнивают максимальное значение со значением, полученным по формуле:
![]() ,
,
если полученное значение меньше максимального, то шаг интервала увеличивают на единицу
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Определяем место варианте, совпадающей с числом, являющимся границей двух интервалов.
Для этого верхние границы всех интервалов уменьшаются на величину, равную точности измеряемого признака (точность определяется по количеству знаков после запятой у измеренных данных).
1 интервал – 9-14
2 интервал – 15-20
3 интервал – 21-26
4 интервал – 27-32
5 интервал – 33-38
6 интервал – 39-44
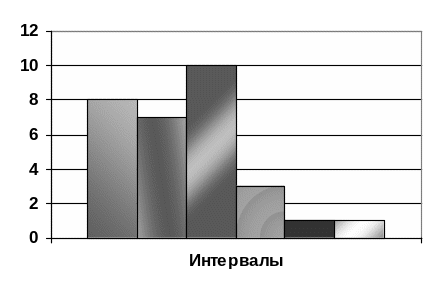
Заполняем статистическую таблицу.
№ |
Границы интервала |
Среднее значение интервала |
Частота |
Накопленная частота |
Частость |
Накопленная частость |
1 |
9-14 |
12 |
8 |
8 |
0,27 |
0,27 |
2 |
15-20 |
18 |
7 |
15 |
0,23 |
0,5 |
3 |
21-26 |
24 |
10 |
25 |
0,33 |
0,83 |
4 |
27-32 |
30 |
3 |
28 |
0,1 |
0,93 |
5 |
33-38 |
36 |
1 |
29 |
0,03 |
0,96 |
6 |
39-44 |
42 |
1 |
30 |
0,03 |
0,99 |
Частота интервала показывает сколько раз значения, относящиеся к каждому интервалу, встречаются в выборке.
Накопленная частота – число, полученное последовательным суммированием частот в направлении от первого интервала к последнему.
Частость (относительная частота) – отношение частоты к объему выборки.
Накопленная частость – число, полученное последовательным суммированием частости в направлении от первого интервала к последнему.
Представим графически полученные данные.
Гистограмма.
Используется для графического представления распределения и состоит их примыкающих друг к другу прямоугольников у которых основания равны ширине интервалов, а высота – частоте в данном интервале.
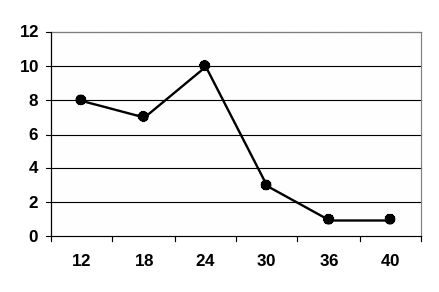
Полигон частот
Образуется ломаной линией соединяющей точки, соответствующие середине интервала и частотам в данном интервале.
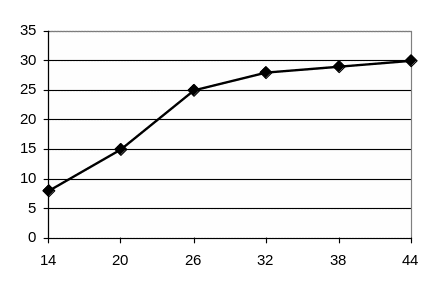
Кумулята.
Получается при соединении отрезками прямых точек, координаты которых соответствуют верхним границам интервалов группировки и накопленным частотам.
числовые характеристики выборки