

Приложение 9.1. D-статистика Дарбина - Уотсона: d1 и d2, уровень значимости в 5%
|
n |
k =1 |
k =2 | ||||||
|
|
d1 |
d2 |
d1 |
d2 | ||||
|
15
|
1,08
|
1,36
|
0,95
|
1,54
| ||||
|
16
|
1,10
|
1,37
|
0,98
|
1,54 | ||||
|
17
|
1,13
|
1,38
|
1,02
|
1,54
| ||||
|
18
|
1,16 1,16
|
1,39
|
1,05
|
1,53
| ||||
|
19
|
1,18
|
1,40
|
1,08
|
1,53
| ||||
|
20
|
I,20
|
1,41
|
1,10
|
1,54
| ||||
|
21
|
1,22
|
1,42
|
1,13
|
1,54
| ||||
|
22
|
1,24
|
1,43
|
1,15
|
1,54
| ||||
|
23
|
1,26
|
1,44
|
1,17
|
1,54
| ||||
|
24
|
1,27
|
1,45
|
1,19
|
1,55
| ||||
|
25
|
1,29
|
1,45
|
1,21
|
1,55
| ||||
При сравнении расчетного значения dw статистики (9.9) с табличным могут возникнуть такие ситуации: d2 < dw < 2 – ряд остатков не коррелирован; dw < d1 – остатки содержат автокорреляцию; d1 < dw < d2 – область неопределенности, когда нет оснований ни принять, ни отвергнуть гипотезу о существовании автокорреляции. Если d превышает 2, то это свидетельствует о наличии отрицательной корреляции. Перед сравнением с табличными значениями dw критерий следует преобразовать по формуле dw´=4 – dw.
Установив наличие автокорреляции остатков, переходят к улучшению модели. Если же ситуация оказалась неопределенной (d1 < dw < d2 ), то применяют другие критерии. В частности, можно воспользоваться первым коэффициентом автокорреляции
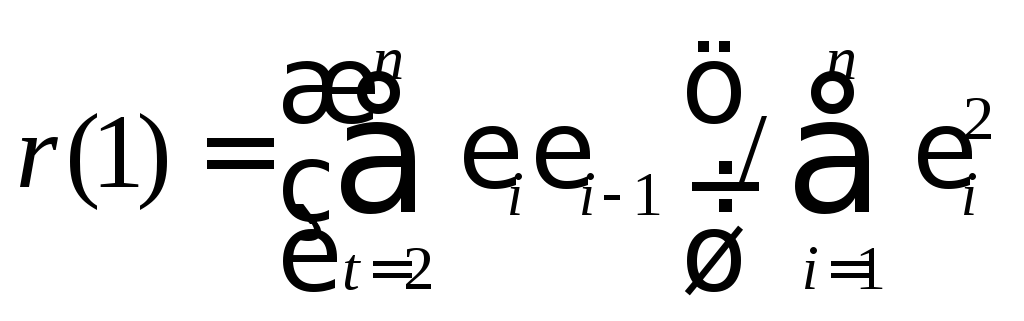 (4.10)
(4.10)
Для принятия решения о наличии или отсутствии автокорреляции в исследуемом ряду фактическое значение коэффициента автокорреляции r(1) сопоставляется с табличным (критическим) значением для 5%-ного уровня значимости (вероятности допустить ошибку при принятии нулевой гипотезы о независимости уровней ряда). Если фактическое значение коэффициента автокорреляции меньше табличного, то гипотеза об отсутствии автокорреляции в ряду может быть принята, а если фактическое значение больше табличного – делают вывод о наличии автокорреляции в ряду динамики.
Обнаружение гетероскедастичности
Для обнаружения гетероскедастичности обычно используют три теста, в которых делаются различные предположения о зависимости между дисперсией случайного члена и объясняющей переменной: тест ранговой корреляции Спирмена, тест Голдфельда - Квандта и тест Глейзера [Доугерти].
При малом объеме выборки для оценки гетероскедастичности может использоваться метод Голдфельда — Квандта.
Данный
тест используется для проверки такого
типа
гетероскедастичности, когда дисперсия
остатков возрастает пропорционально
квадрату фактора.
При этом делается
предположение, что, случайная составляющая
![]() распределена
нормально.
распределена
нормально.
Чтобы оценить нарушение гомоскедастичности по тесту Голдфельда - Квандта необходимо выполнить следующие шаги.
Упорядочение п наблюдений по мере возрастания переменной х.
Разделение совокупности на две группы (соответственно с малыми и большими значениями фактора х) и определение по каждой из групп уравнений регрессии.
Определение остаточной суммы квадратов для первой регрессии
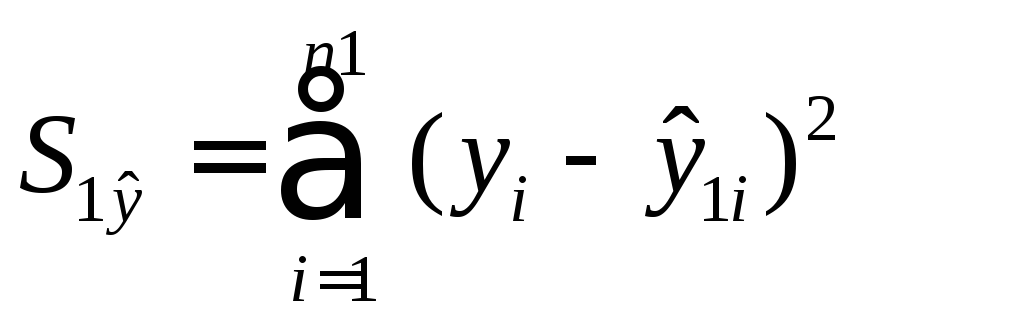 и
второй регрессии
и
второй регрессии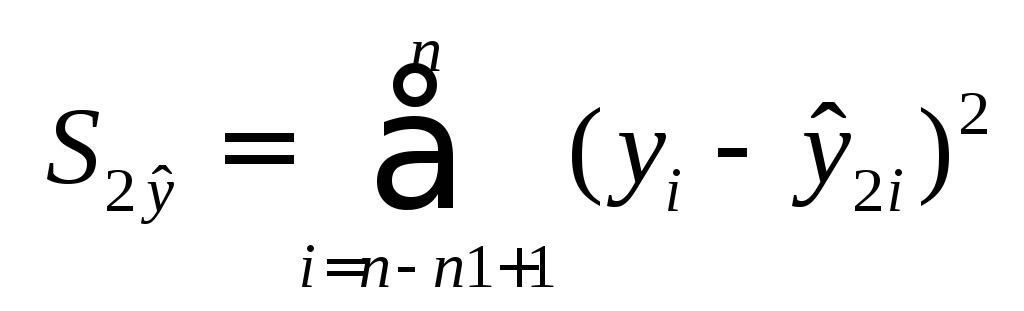 .
.Вычисление отношений
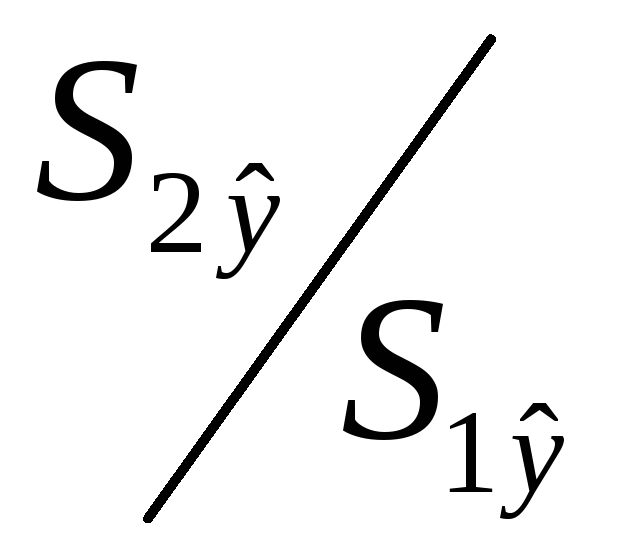 (или
(или ).
В числителе должна быть большая сумма
квадратов.
).
В числителе должна быть большая сумма
квадратов.
Полученное отношение имеет F распределение со степенями свободы k1=n1-m и k2=n-n1-m, (m– число оцениваемых параметров в уравнении регрессии).
Если
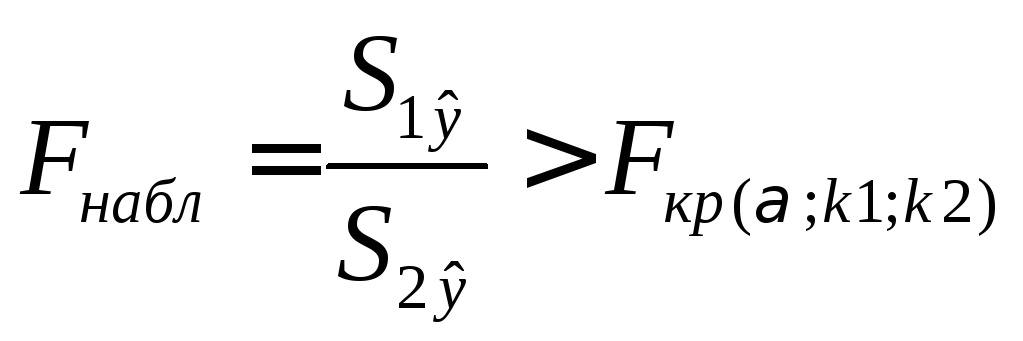 ,
тогетероскедастичность
имеет место.
,
тогетероскедастичность
имеет место.
Чем больше величина F превышает табличное значение F -критерия, тем более нарушена предпосылка о равенстве дисперсий остаточных величин.
Оценка влияния отдельных факторов на зависимую переменную на основе модели (коэффициенты эластичности, - коэффициенты).
Важную роль при оценке влияния факторов играют коэффициенты регрессионной модели. Однако непосредственно с их помощью нельзя сопоставить факторы по степени их влияния на зависимую переменную из-за различия единиц измерения и разной степени колеблемости. Для устранения таких различий при интерпретации применяются средние частные коэффициенты эластичности Э(j) и бета-коэффициенты (j), которые рассчитываются соответственно по формулам:
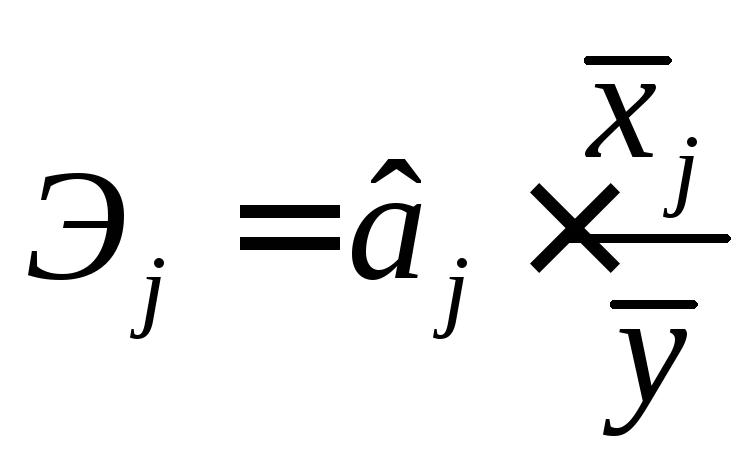 (9.11.)
(9.11.)
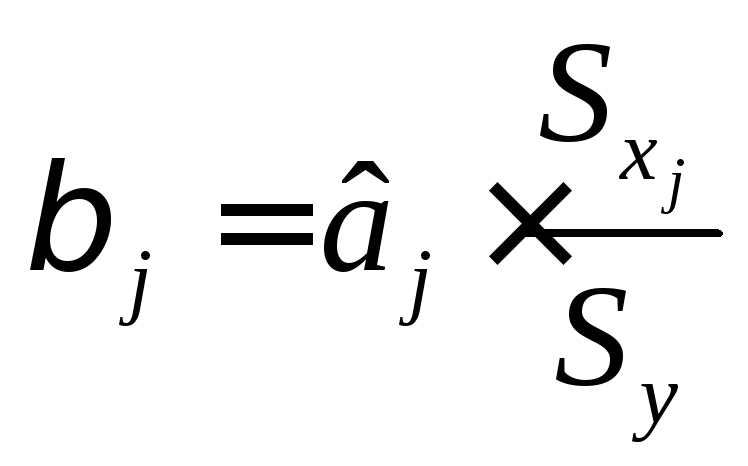 (9.12.)
(9.12.)
где Sxj — среднеквадратическое отклонение фактора j
где
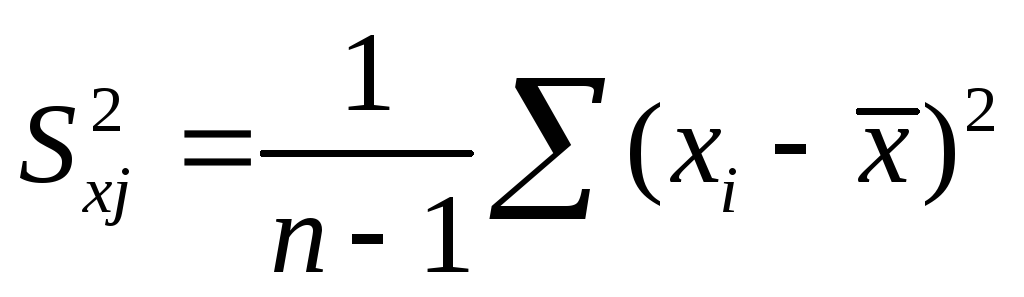
![]()
Коэффициент эластичности показывает, на сколько процентов изменяется зависимая переменная при изменении фактора j на один процент. Однако он не учитывает степень колеблемости факторов.
Бета-коэффициент показывает, на какую часть величины среднего квадратического отклонения Sy изменится зависимая переменная Y с изменением соответствующей независимой переменной Хj на величину своего среднеквадратического отклонения при фиксированном на постоянном уровне значении остальных независимых переменных.
Указанные коэффициенты позволяют упорядочить факторы по степени влияния факторов на зависимую переменную.
Долю влияния фактора в суммарном влиянии всех факторов можно оценить по величине дельта - коэффициентов (j):
![]()
где
![]() —
коэффициент парной корреляции между
фактором
j
(j
=
1,...,m)
и зависимой переменной.
—
коэффициент парной корреляции между
фактором
j
(j
=
1,...,m)
и зависимой переменной.
Использование многофакторных моделей для анализа и прогнозирования развития систем и процессов.
Одна из важнейших целей моделирования заключается в прогнозировании поведения исследуемого объекта. Обычно термин «прогнозирование» используется в тех ситуациях, когда требуется предсказать состояние системы в будущем. Для регрессионных моделей он имеет, однако, более широкое значение. Как уже отмечалось, данные могут не иметь временной структуры, но и в этих случаях вполне может возникнуть задача оценки значения зависимой переменной для некоторого набора независимых, объясняющих переменных, которых нет в исходных наблюдениях. Именно в этом смысле — как построение оценки зависимой переменной — и следует понимать прогнозирование в эконометрике.
При использовании построенной модели для прогнозирования делается предположение о сохранении в период прогнозирования существовавших ранее взаимосвязей переменных.
Построение точечных и интервальных прогнозов на основе регрессионной модели. Какие факторы влияют на ширину доверительного интервала?
Для того чтобы определить область возможных значений результативного показателя, при рассчитанных значениях факторов следует учитывать два возможных источника ошибок: рассеивание наблюдений относительно линии регрессии и ошибки, обусловленные математическим аппаратом построения самой линии регрессии. Ошибки первого рода измеряются с помощью характеристик точности, в частности, величиной Sy. Ошибки второго рода обусловлены фиксацией численного значения коэффициентов регрессии, в то время как они в действительности являются случайными, нормально распределенными.
Для линейной модели регрессии доверительный интервал рассчитывается следующим образом. Оценивается величина отклонения от линии регрессии (обозначим ее U):
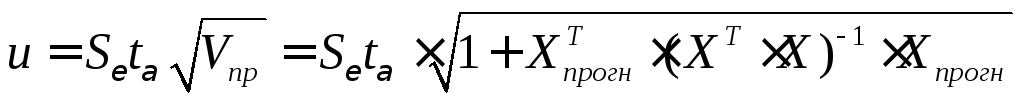 (9.13)
(9.13)
где
![]()