

Garrett R.H., Grisham C.M. - Biochemistry (1999)(2nd ed.)(en)
.pdf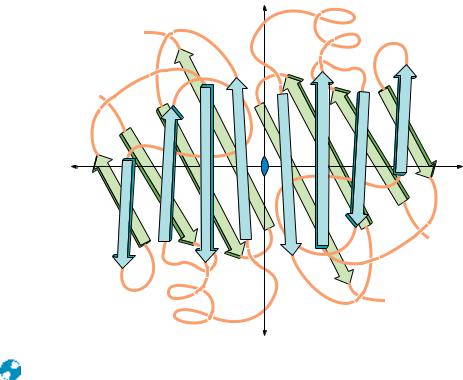
202 Chapter 6 ● Proteins: Secondary, Tertiary, and Quaternary Structure
|
|
|
y |
|
|
|
C' |
|
|
|
|
|
|
N' |
|
|
|
|
|
|
|
|
H' |
F |
E |
B |
C |
|
|
|
|
|
|
A |
x |
B' |
E' |
F' |
|
G |
x |
A' |
|
|
|
|||
|
|
|
|
H |
|
|
C' |
|
|
|
|
|
|
|
|
|
|
|
|
N |
|
|
|
|
|
|
C |
|
|
|
y |
|
|
|
● The polypeptide backbone of the prealbumin dimer. The monomers associate in a manner that continues the -sheets. A tetramer is formed by isologous interactions between the side chains extending outward from sheet D A G H HGAD in both dimers, which pack together nearly at right angles to one another.
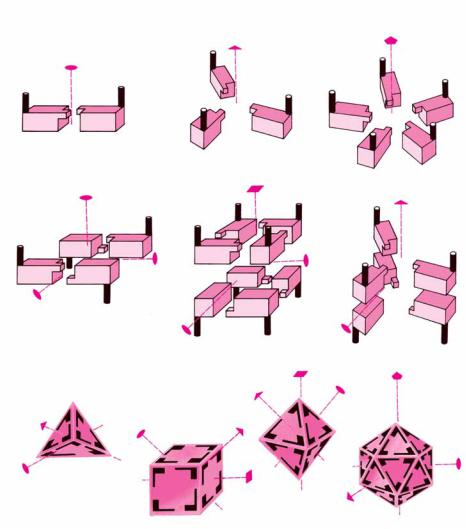
Symmetry of Quaternary Structures
One useful way to consider quaternary interactions in proteins involves the symmetry of these interactions. Globular protein subunits are always asymmetric objects. All of the polypeptide’s -carbons are asymmetric, and the polypeptide nearly always folds to form a low-symmetry structure. (The long helical arrays formed by some synthetic polypeptides are an exception.) Thus, protein subunits do not have mirror reflection planes, points, or axes of inversion. The only symmetry operation possible for protein subunits is a rotation. The most common symmetries observed for multisubunit proteins are cyclic symmetry and dihedral symmetry. In cyclic symmetry, the subunits are arranged around a single rotation axis, as shown in Figure 6.44. If there are two subunits, the axis is referred to as a twofold rotation axis. Rotating the quaternary structure 180° about this axis gives a structure identical to the original one. With three subunits arranged about a threefold rotation axis, a rotation of 120° about that axis gives an identical structure. Dihedral symmetry occurs when a structure possesses at least one twofold rotation axis perpendicular to another n-fold rotation axis. This type of subunit arrangement (Figure 6.44) occurs in concanavalin A (where n 2) and in insulin (where n 3). Higher symmetry groups, including the tetrahedral, octahedral, and icosahedral symmetries, are much less common among multisubunit proteins, partly because of the large number of asymmetric subunits required to assemble truly symmetric tetrahedra and other high symmetry groups. For example, a truly symmetric tetrahedral protein structure would require 12 identical monomers arranged in triangles, as shown in Figure 6.45. Simple four-subunit tetrahedra of protein monomers, which actually possess dihedral symmetry, are more common in biological systems.




 α
α




 8.0 nm
8.0 nm206 Chapter 6 ● Proteins: Secondary, Tertiary, and Quaternary Structure
solvent water is often energetically unfavorable, decreased surface-to-volume ratios usually result in more stable proteins. Subunit association may also serve to shield hydrophobic residues from solvent water. Subunits that recognize either themselves or other subunits avoid any errors arising in genetic translation by binding mutant forms of the subunits less tightly.
Genetic Economy and Efficiency
Oligomeric association of protein monomers is genetically economical for an organism. Less DNA is required to code for a monomer that assembles into a homomultimer than for a large polypeptide of the same molecular mass. Another way to look at this is to realize that virtually all of the information that determines oligomer assembly and subunit–subunit interaction is contained in the genetic material needed to code for the monomer. For example, HIV protease, an enzyme that is a dimer of identical subunits, performs a catalytic function similar to homologous cellular enzymes that are single polypeptide chains of twice the molecular mass (Chapter 16).
Bringing Catalytic Sites Together
Many enzymes (see Chapters 14 to 16) derive at least some of their catalytic power from oligomeric associations of monomer subunits. This can happen in several ways. The monomer may not constitute a complete enzyme active site. Formation of the oligomer may bring all the necessary catalytic groups together to form an active enzyme. For example, the active sites of bacterial glutamine synthetase are formed from pairs of adjacent subunits. The dissociated monomers are inactive.
Oligomeric enzymes may also carry out different but related reactions on different subunits. Thus, tryptophan synthase is a tetramer consisting of pairs of different subunits, 2 2. Purified -subunits catalyze the following reaction:
Indoleglycerol phosphate 34 Indole Glyceraldehyde-3-phosphate
and the -subunits catalyze this reaction:
Indole L-Serine 34 L-Tryptophan
Indole, the product of the -reaction and the reactant for the -reaction, is passed directly from the -subunit to the -subunit and cannot be detected as a free intermediate.
Cooperativity
There is another, more important reason for monomer subunits to associate into oligomeric complexes. Most oligomeric enzymes regulate catalytic activity by means of subunit interactions, which may give rise to cooperative phenomena. Multisubunit proteins typically possess multiple binding sites for a given ligand. If the binding of ligand at one site changes the affinity of the protein for ligand at the other binding sites, the binding is said to be cooperative. Increases in affinity at subsequent sites represent positive cooperativity, whereas decreases in affinity correspond to negative cooperativity. The points of contact between protein subunits provide a mechanism for communication between the subunits. This in turn provides a way in which the binding of ligand to one subunit can influence the binding behavior at the other subunits. Such cooperative behavior, discussed in greater depth in Chapter 15, is the underlying mechanism for regulation of many biological processes.


