Garrett R.H., Grisham C.M. - Biochemistry (1999)(2nd ed.)(en)
.pdf
|
|
5.1 ● |
Proteins Are Linear Polymers of Amino Acids |
111 |
|
Table 5.1 |
|
|
|
|
|
|
|
|
|
|
|
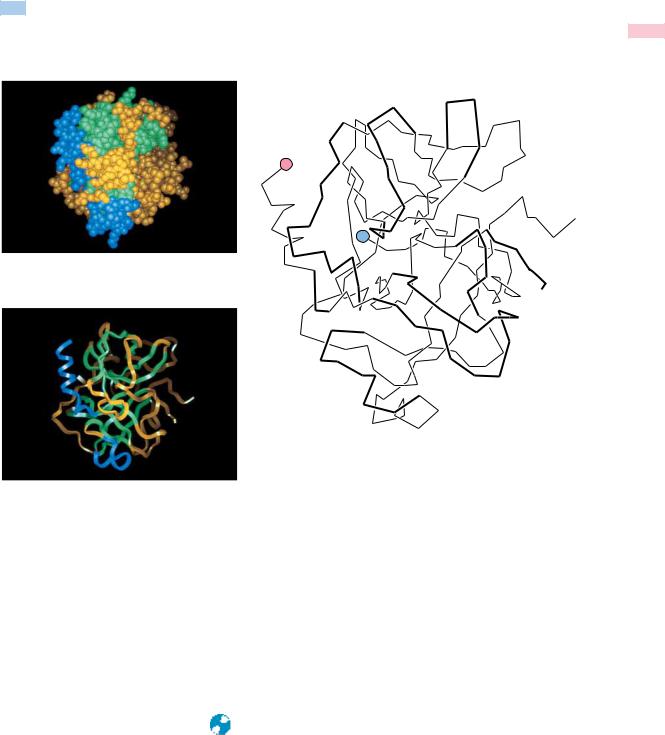
Size of Protein Molecules* |
|
|
|
|
|
|
|
|
|
||
Protein |
Mr |
Number of Residues per Chain |
Subunit Organization |
||
|
|
|
|
|
|
Insulin (bovine) |
5,733 |
21 |
(A) |
|
|
|
|
30 |
(B) |
|
|
Cytochrome c (equine) |
12,500 |
104 |
|
1 |
|
Ribonuclease A (bovine pancreas) |
12,640 |
124 |
|
1 |
|
Lysozyme (egg white) |
13,930 |
129 |
|
1 |
|
Myoglobin (horse) |
16,980 |
153 |
|
1 |
|
Chymotrypsin (bovine pancreas) |
22,600 |
13 ( ) |
|
|
|
|
|
132 |
( ) |
|
|
|
|
97 |
( ) |
|
|
Hemoglobin (human) |
64,500 |
141 |
( ) |
2 2 |
|
|
|
146 |
( ) |
|
|
Serum albumin (human) |
68,500 |
550 |
|
1 |
|
Hexokinase (yeast) |
96,000 |
200 |
|
4 |
|
-Globulin (horse) |
149,900 |
214 |
( ) |
2 2 |
|
|
|
446 |
( ) |
|
|
Glutamate dehydrogenase (liver) |
332,694 |
500 |
|
6 |
|
Myosin (rabbit) |
470,000 |
1800 (heavy, h) |
h2 1 2 2 |
|
|
|
|
190 |
( ) |
|
|
|
|
149 |
( ) |
|
|
|
|
160 |
( ) |
|
|
Ribulose bisphosphate carboxylase (spinach) |
560,000 |
475 |
( ) |
8 8 |
|
|
|
123 |
( ) |
|
|
Glutamine synthetase (E. coli) |
600,000 |
468 |
|
12 |
|
Insulin
Cytochrome c |
Ribonuclease |
Myoglobin |
|
Lysozyme |
Hemoglobin
Immunoglobulin
Glutamine synthetase
*Illustrations of selected proteins listed in Table 5.1 are drawn to constant scale.
Adapted from Goodsell and Olson, 1993. Trends in Biochemical Sciences 18:65–68.
5.1 ● Proteins Are Linear Polymers of Amino Acids |
113 |
amount of ammonium released during acid hydrolysis gives an estimate of the total number of Asn and Gln residues in the original protein, but not the amounts of either. Accordingly, the concentrations of Asp and Glu determined in amino acid analysis are expressed as Asx and Glx, respectively. Because the relative contributions of [Asn Asp] or [Gln Glu] cannot be derived from the data, this information must be obtained by alternative means.
Amino Acid Analysis of Proteins
The complex amino acid mixture in the hydrolysate obtained after digestion of a protein in 6 N HCl can be separated into the component amino acids by either ion exchange chromatography (see Chapter 4) or by reversed-phase high-pressure liquid chromatography (HPLC) (see Chapter Appendix). The amount of each amino acid can then be determined. In ion exchange chromatography, the amino acids are separated and then quantified following reaction with ninhydrin (so-called postcolumn derivatization). In HPLC, the amino acids are converted to phenylthiohydantoin (PTH) derivatives via reaction with Edman’s reagent (see Figure 5.19) prior to chromatography (precolumn derivatization). Both of these methods of separation and analysis are fully automated in instruments called amino acid analyzers. Analysis of the amino acid composition of a 30-kD protein by these methods requires less than 1 hour and only 6 g (0.2 nmol) of the protein.
Table 5.2 gives the amino acid composition of several selected proteins: ribonuclease A, alcohol dehydrogenase, myoglobin, histone H3, and collagen. Each of the 20 naturally occurring amino acids is usually represented at least once in a polypeptide chain. However, some small proteins may not have a representative of every amino acid. Note that ribonuclease (12.6 kD, 124 amino acid residues) does not contain any tryptophan. Amino acids almost never occur in equimolar ratios in proteins, indicating that proteins are not composed of repeating arrays of amino acids. There are a few exceptions to this rule. Collagen, for example, contains large proportions of glycine and proline, and much of its structure is composed of (Gly-x-Pro) repeating units, where x is any amino acid. Other proteins show unusual abundances of various amino acids. For example, histones are rich in positively charged amino acids such as arginine and lysine. Histones are a class of proteins found associated with the anionic phosphate groups of eukaryotic DNA.
Amino acid analysis itself does not directly give the number of residues of each amino acid in a polypeptide, but it does give amounts from which the percentages or ratios of the various amino acids can be obtained (Table 5.2). If the molecular weight and the exact amount of the protein analyzed are known (or the number of amino acid residues per molecule is known), the molar ratios of amino acids in the protein can be calculated. Amino acid analysis provides no information on the order or sequence of amino acid residues in the polypeptide chain. Because the polypeptide chain is unbranched, it has only two ends, an amino-terminal or N-terminal end and a carboxyl-terminal or
C-terminal end.
The Sequence of Amino Acids in Proteins
The unique characteristic of each protein is the distinctive sequence of amino acid residues in its polypeptide chain(s). Indeed, it is the amino acid sequence of proteins that is encoded by the nucleotide sequence of DNA. This amino acid sequence, then, is a form of genetic information. By convention, the amino acid sequence is read from the N-terminal end of the polypeptide chain through to the C-terminal end. As an example, every molecule of ribonucle-

114 Chapter 5 ● Proteins: Their Biological Functions and Primary Structure
Table 5.2
Amino Acid Composition of Some Selected Proteins
Values expressed are percent representation of each amino acid.
|
|
|
|
Proteins* |
|
|
|
|
|
|
|
|
|
Amino Acid |
RNase |
ADH |
Mb |
Histone H3 |
Collagen |
|
|
|
|
|
|
|
|
Ala |
6.9 |
7.5 |
9.8 |
13.3 |
11.7 |
|
Arg |
3.7 |
3.2 |
1.7 |
13.3 |
4.9 |
|
Asn |
7.6 |
2.1 |
2.0 |
0.7 |
1.0 |
|
Asp |
4.1 |
4.5 |
5.0 |
3.0 |
3.0 |
|
Cys |
6.7 |
3.7 |
0 |
1.5 |
0 |
|
Gln |
6.5 |
2.1 |
3.5 |
5.9 |
2.6 |
|
Glu |
4.2 |
5.6 |
8.7 |
5.2 |
4.5 |
|
Gly |
3.7 |
10.2 |
9.0 |
5.2 |
32.7 |
|
His |
3.7 |
1.9 |
7.0 |
1.5 |
0.3 |
|
Ile |
3.1 |
6.4 |
5.1 |
5.2 |
0.8 |
|
Leu |
1.7 |
6.7 |
11.6 |
8.9 |
2.1 |
|
Lys |
7.7 |
8.0 |
13.0 |
9.6 |
3.6 |
|
Met |
3.7 |
2.4 |
1.5 |
1.5 |
0.7 |
|
Phe |
2.4 |
4.8 |
4.6 |
3.0 |
1.2 |
|
Pro |
4.5 |
5.3 |
2.5 |
4.4 |
22.5 |
|
Ser |
12.2 |
7.0 |
3.9 |
3.7 |
3.8 |
|
Thr |
6.7 |
6.4 |
3.5 |
7.4 |
1.5 |
|
Trp |
0 |
0.5 |
1.3 |
0 |
0 |
|
Tyr |
4.0 |
1.1 |
1.3 |
2.2 |
0.5 |
|
Val |
7.1 |
10.4 |
4.8 |
4.4 |
1.7 |
|
Acidic |
8.4 |
10.2 |
13.7 |
8.1 |
7.5 |
|
Basic |
15.0 |
13.1 |
21.8 |
24.4 |
8.8 |
|
Aromatic |
6.4 |
6.4 |
7.2 |
5.2 |
1.7 |
|
Hydrophobic |
18.0 |
30.7 |
27.6 |
23.0 |
6.5 |
|
*Proteins are as follows:
RNase: Bovine ribonuclease A, an enzyme; 124 amino acid residues. Note that RNase lacks tryptophan.
ADH: Horse liver alcohol dehydrogenase, an enzyme; dimer of identical 374 amino acid polypeptide chains. The amino acid composition of ADH is reasonably representative of the norm for water-soluble proteins.
Mb: Sperm whale myoglobin, an oxygen-binding protein; 153 amino acid residues. Note that Mb lacks cysteine.
Histone H3: Histones are DNA-binding proteins found in chromosomes; 135 amino acid residues. Note the very basic nature of this protein due to its abundance of Arg and Lys residues. It also lacks tryptophan.
Collagen: Collagen is an extracellular structural protein; 1052 amino acid residues. Collagen has an unusual amino acid composition; it is about one-third glycine and is rich in proline. Note that it also lacks Cys and Trp and is deficient in aromatic amino acid residues in general.
ase A from bovine pancreas has the same amino acid sequence, beginning with N-terminal lysine at position 1 and ending with C-terminal valine at position 124 (Figure 5.6). Given the possibility of any of the 20 amino acids at each position, the number of unique amino acid sequences is astronomically large. The astounding sequence variation possible within polypeptide chains provides

5.2 ● Architecture of Protein Molecules |
115 |
|
|
|
|
|
|
|
|
50 |
|
|
|
|
|
|
|
|
|
|
|
|
|
Leu |
Ser Glu His |
Val Phe |
Thr |
Asn |
|
|
|||
|
|
|
|
Ala |
|
|
|
100 |
|
|
|
||||
|
|
|
|
Asp |
|
|
|
|
|
|
|
Val |
|
||
|
|
|
|
|
|
Lys Asn Ala Gln Thr Thr |
|
|
Pro |
41 |
|||||
|
|
|
Val |
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
||||||||
|
|
|
Gln |
|
|
His |
|
|
|
|
Lys |
|
|
Lys |
|
|
|
|
Ile |
|
|
124 |
|
Tyr |
|
40 |
|||||
|
|
Ala |
|
|
|
|
|
|
|
Cys |
|||||
|
|
Ile |
|
|
HOOC |
Val Ser |
Ala |
|
|
Ala |
|
||||
|
Val |
|
|
|
|
|
Arg |
||||||||
|
Val |
|
|
|
|
|
|
Asp |
|
|
|
Cys |
|||
|
|
|
|
|
|
|
|
|
|
|
|||||
58 |
|
|
|
|
|
|
|
|
|
|
95 |
Asp |
|||
|
Cys |
|
Ala |
|
|
|
|
|
|
120 Phe |
|
|
Asn |
||
|
|
|
|
|
|
|
Pro |
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
Lys |
|||
|
|
|
|
|
|
|
|
|
Val His 119 |
|
|
|
|||
60 |
Ser |
|
Cys Glu Gly |
|
|
Val |
|
|
Pro |
||||||
|
|
|
|
Tyr |
|
|
|
|
Thr |
||||||
|
Gln |
110 |
|
|
|
|
|
|
|
|
Tyr |
||||
|
|
|
Asn Pro |
|
|
|
|
|
|
||||||
Lys |
|
Ser Thr Met |
|
80 |
|
|
Glu Thr |
|
|
90 Lys |
Leu |
||||
|
Ser |
|
|
|
|
|
|||||||||
Asn |
Tyr |
|
Ile Thr |
Arg |
Gly Ser |
Ser |
|
Asn |
|||||||
Val |
Ser |
|
|
|
|
Asp |
Cys 84 |
|
|
|
|
Arg |
|||
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
26 |
|
|
|
Ser |
|
|
Ala |
|
Gln |
|
|
|
|
|
Cys |
|
|
30 |
|||
|
|
|
|
21 |
|
|
|
|
Lys |
|
|||||
65 |
|
|
20 |
|
|
|
Tyr |
Asn Gln Met Met |
|
||||||
Cys |
|
Tyr |
|
Ser |
Ser |
|
|
||||||||
|
|
Ala |
Asn |
|
|
|
|
|
|
||||||
Lys |
|
72 |
|
|
Ser |
|
|
|
|
|
|
||||
|
Cys |
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
Ala |
|
|
|
|
|
|
|
|
|
|
|
|
Asn |
|
|
|
|
|
|
|
12 |
|
|
10 |
|
|
||
|
Asn |
|
|
|
|
|
|
|
|
|
|
||||
Gly |
|
Ser Thr Ser Ser Asp Met His Gln Arg |
|
|
|||||||||||
Thr 70 |
|
|
|||||||||||||
|
Gln |
|
|
|
|
|
|
|
7 |
|
Glu |
|
|
||
Glu Thr Ala Ala Ala Lys Phe
H2N Lys 1
FIGURE 5.6 ● Bovine pancreatic ribonuclease A contains 124 amino acid residues, none
of which are tryptophan. Four intrachain disulfide bridges (SOS) form cross-links in this polypeptide between Cys26 and Cys84, Cys40 and Cys95, Cys58 and Cys110, and Cys65 and
Cys72. These disulfides are depicted by yellow bars.
a key insight into the incredible functional diversity of protein molecules in biological systems, which is discussed shortly.
5.2 ● Architecture of Protein Molecules
Protein Shape
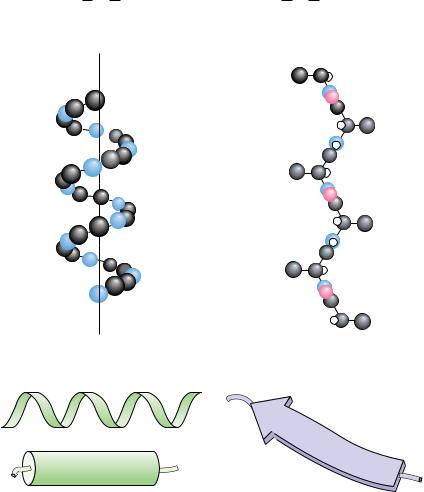
As a first approximation, proteins can be assigned to one of three global classes on the basis of shape and solubility: fibrous, globular, or membrane (Figure 5.7). Fibrous proteins tend to have relatively simple, regular linear structures. These proteins often serve structural roles in cells. Typically, they are insoluble in water or in dilute salt solutions. In contrast, globular proteins are roughly spherical in shape. The polypeptide chain is compactly folded so that hydrophobic amino acid side chains are in the interior of the molecule and the hydrophilic side chains are on the outside exposed to the solvent, water. Consequently, globular proteins are usually very soluble in aqueous solutions. Most soluble proteins of the cell, such as the cytosolic enzymes, are globular in shape. Membrane proteins are found in association with the various membrane systems of cells. For interaction with the nonpolar phase within membranes, membrane proteins have hydrophobic amino acid side chains oriented outward. As such, membrane proteins are insoluble in aqueous solutions but can be solubilized in solutions of detergents. Membrane proteins characteristically have fewer hydrophilic amino acids than cytosolic proteins.

 C
C

 C
C
 C
C C
C