

Garrett R.H., Grisham C.M. - Biochemistry (1999)(2nd ed.)(en)
.pdf Performic acid
Performic acid
142 Chapter 5 ● Proteins: Their Biological Functions and Primary Structure
the Chapter Appendix). Peptides that were originally linked by disulfides now migrate as distinct species following disulfide cleavage and are obvious by their location off the diagonal (Figure 5.26e). These cysteic acid–containing peptides are then isolated from the paper and sequenced. From this information, the positions of the disulfides in the protein can be stipulated.
Sequence Databases
A database of protein sequences collected by protein chemists can be found in the Atlas of Protein Sequence and Structure. However, most protein sequence information has been derived from translating the nucleotide sequences of genes into codons and, thus, amino acid sequences (see Chapter 13). Sequencing the order of nucleotides in cloned genes is a more rapid, efficient, and informative process than determining the amino acid sequences of proteins. A number of electronic databases containing continuously updated sequence information are readily accessible by personal computer. Prominent among these are PIR (Protein Identification Resource Protein Sequence Database), GenBank (Genetic Sequence Data Bank), and EMBL (European Molecular Biology Laboratory Data Library).
5.8 ● Nature of Amino Acid Sequences
With a knowledge of the methodology in hand, let’s review the results of amino acid composition and sequence studies on proteins. Table 5.8 lists the relative frequencies of the amino acids in various proteins. It is very unusual for a globular protein to have an amino acid composition that deviates substantially from these values. Apparently, these abundances reflect a distribution of amino acid polarities that is optimal for protein stability in an aqueous milieu. Membrane proteins have relatively more hydrophobic and fewer ionic amino acids, a condition consistent with their location. Fibrous proteins may show compositions that are atypical with respect to these norms, indicating an underlying relationship between the composition and the structure of these proteins.
Proteins have unique amino acid sequences, and it is this uniqueness of sequence that ultimately gives each protein its own particular personality. Because the number of possible amino acid sequences in a protein is astronomically large, the probability that two proteins will, by chance, have similar amino acid sequences is negligible. Consequently, sequence similarities between proteins imply evolutionary relatedness.
Homologous Proteins from Different Organisms
Have Homologous Amino Acid Sequences
Proteins sharing a significant degree of sequence similarity are said to be homologous. Proteins that perform the same function in different organisms are also referred to as homologous. For example, the oxygen transport protein, hemoglobin, serves a similar role and has a similar structure in all vertebrates. The study of the amino acid sequences of homologous proteins from different organisms provides very strong evidence for their evolutionary origin within a common ancestor. Homologous proteins characteristically have polypeptide chains that are nearly identical in length, and their sequences share identity in direct correlation to the relatedness of the species from which they are derived.

 Gly
Gly Gly
Gly Phe
Phe Heme
Heme His
His Pro
Pro Leu
Leu Gly
Gly Arg
Arg Gly
Gly Gly
Gly Tyr
Tyr Asn
Asn Trp
Trp Leu
Leu Tyr
Tyr Pro
Pro Lys
Lys Met
Met Phe
Phe Gly
Gly Arg
Arg


5.8 ● Nature of Amino Acid Sequences |
145 |
Ancestral |
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
10 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
20 |
|
|
|
|
|
|
|
|
|
|
|
||||||||||
cytochrome c |
|
Pro |
|
Ala |
|
Gly |
|
|
|
Asp |
|
|
? |
|
Lys |
|
Lys |
|
Gly |
|
Ala |
|
Lys |
|
|
Ile |
|
|
Phe |
|
Lys |
|
Thr |
|
? |
|
Cys |
|
Ala |
|
Gln |
|
|
|
|
Cys |
|
His |
|
|
|
Thr |
|
|
Val |
|
Glu |
|
? |
|
Gly |
|
Gly |
|
? |
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||||||||||||||||
Human |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Val |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Gly |
|
|
|
Asp |
|
|
|
Glu |
|
Lys |
|
Gly |
|
Lys |
|
Lys |
|
|
Ile |
|
|
Phe |
|
Ile |
|
Met |
|
Lys |
|
Cys |
|
Ser |
|
Gln |
|
|
|
|
Cys |
|
His |
|
|
|
Thr |
|
|
Val |
|
Glu |
|
Lys |
|
Gly |
|
Gly |
|
Lys |
|
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||||||
cytochrome c |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
30 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
40 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
50 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
His |
|
|
|
Lys |
|
|
Val |
|
Gly |
|
Pro |
|
Asn |
|
Leu |
|
His |
|
|
Gly |
|
|
Leu |
|
Phe |
|
Gly |
|
Arg |
|
Lys |
|
? |
|
Gly |
|
|
|
|
Gln |
|
Ala |
|
|
|
? |
|
|
Gly |
|
Tyr |
|
Ser |
|
Tyr |
|
Thr |
|
Asp |
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
His |
|
|
|
Lys |
|
Thr |
|
Gly |
|
Pro |
|
Asn |
|
Leu |
|
His |
|
|
Gly |
|
|
Leu |
|
Phe |
|
Gly |
|
Arg |
|
Lys |
|
Thr |
|
Gly |
|
|
|
|
Gln |
|
Ala |
|
|
|
Pro |
|
|
Gly |
|
Tyr |
|
Ser |
|
Tyr |
|
Thr |
|
Ala |
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
60 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
70 |
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
Ala |
|
|
|
Asn |
|
|
Lys |
|
Asn |
|
Lys |
|
Gly |
|
? |
|
? |
|
|
|
Trp |
|
|
? |
|
|
Glu |
|
Asn |
|
Thr |
|
Leu |
|
Phe |
|
Glu |
|
|
|
|
Tyr |
|
Leu |
|
|
Glu |
|
|
Asn |
|
Pro |
|
Lys |
|
Lys |
|
Tyr |
|
Ile |
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
|
|
|
|
|
|
|
Ala |
|
|
|
Asn |
|
|
Lys |
|
Asn |
|
Lys |
|
Gly |
|
Ile |
|
Ile |
|
|
|
Trp |
|
|
|
Gly |
|
Glu |
|
Asp |
|
Thr |
|
Leu |
|
Met |
|
Gln |
|
|
|
|
Tyr |
|
Leu |
|
|
Glu |
|
|
Asn |
|
Pro |
|
Lys |
|
Lys |
|
Tyr |
|
Pro |
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
80 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
90 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
100 |
|
|
|
|
|
|
|
|
|
Pro |
|
|
|
Gly |
|
Thr |
|
Lys |
|
Met |
|
? |
|
|
Phe |
|
? |
|
|
|
Gly |
|
|
Leu |
|
Lys |
|
Lys |
|
? |
|
? |
|
Asp |
|
Arg |
|
|
|
Ala |
|
Asp |
|
|
Leu |
|
|
Ile |
|
Ala |
|
Tyr |
|
Leu |
|
Lys |
|
? |
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||
|
|
|
|
|
|
|
Pro |
|
|
|
Gly |
|
Thr |
|
Lys |
|
Met |
|
Ile |
|
Phe |
|
Val |
|
|
Gly |
|
|
|
Ile |
|
|
Lys |
|
Lys |
|
Lys |
|
Glu |
|
Glu |
|
Arg |
|
|
|
Ala |
|
Asp |
|
|
Leu |
|
|
Ile |
|
Ala |
|
Tyr |
|
Leu |
|
Lys |
|
Lys |
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
Ala |
|
|
|
Thr |
|
|
|
Ala |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
Ala |
|
|
|
Thr |
|
|
|
Asn |
|
Glu |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||

146 Chapter 5 ● Proteins: Their Biological Functions and Primary Structure
Related Proteins Share a Common Evolutionary Origin
Amino acid sequence analysis reveals that proteins with related functions often show a high degree of sequence similarity. Such findings suggest a common ancestry for these proteins.
Oxygen-Binding Heme Proteins
The oxygen-binding heme protein of muscle, myoglobin, consists of a single polypeptide chain of 153 residues. Hemoglobin, the oxygen transport protein of erythrocytes, is a tetramer composed of two -chains (141 residues each) and two -chains (146 residues each). These globin polypeptides—myoglobin,-globin, and -globin—share a strong degree of sequence homology (Figure 5.30). Human myoglobin and the human -globin chain show 38 amino acid
|
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
10 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
20 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
Myoglobin |
Gly |
|
|
|
|
|
|
Leu |
|
|
Ser |
|
Asp |
|
Gly |
|
Glu |
|
Trp |
|
Gln |
|
|
Leu |
|
Val |
Leu |
|
Asn |
|
Val |
|
|
Trp |
|
Gly |
|
|
Lys |
|
Val |
|
Glu |
|
Ala |
|
Asp |
|
|
Ile |
|
Pro |
Gly |
|
His |
|
|
Gly |
|
Gln |
|
Glu |
|
|
Val |
|
|
|||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
α |
|
|
|
|
|
|
|
|
|
Ser |
|
|
|
Ala |
|
Asp |
|
|
|
|
|
Thr |
|
Asn |
|
|
Lys |
|
|
|
|
|
Ala |
|
|
|
|
|
|
|
|
|
|
|
|
|
Gly |
|
Ala |
|
His |
|
Ala |
|
Gly |
Gln |
|
Tyr |
|
|
|
|
|
Ala |
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||
|
|
|
|
Val |
|
|
|
|
|
|
Leu |
|
Pro |
|
Lys |
|
Val |
Ala |
|
Trp |
|
Gly |
|
|
Lys |
|
Val |
|
|
|
|
Gly |
Glu |
|
|
Ala |
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
β |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
Val |
|
|
His |
|
Leu |
|
|
Thr |
|
Pro |
|
Glu |
|
Glu |
|
Lys |
|
|
|
Ser |
|
Ala |
|
Val |
Thr |
|
|
Ala |
|
|
|
Leu |
|
|
Trp |
|
Gly |
|
|
Lys |
|
Val |
|
Asn |
|
|
|
|
|
|
|
|
|
Val |
|
Asp |
Glu |
|
Val |
|
|
Gly |
|
Gly |
|
Glu |
|
|
Ala |
|
|
|||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
30 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
40 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
50 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
60 |
|
|
||||||
|
Leu |
|
|
Ile |
|
|
|
Arg |
|
Leu |
|
Phe |
|
|
Lys |
|
Gly |
|
His |
|
Pro |
|
Glu |
|
|
|
Thr |
|
Leu |
|
Glu |
|
Lys |
|
|
Phe |
|
|
Asp |
|
Lys |
|
Phe |
|
|
Lys |
|
His |
|
Leu |
|
Lys |
|
Ser |
|
|
Glu |
|
Asp |
Glu |
|
Met |
|
Lys |
|
Ala |
|
Ser |
|
|
|
|
Glu |
|
|
|||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||
|
Leu |
|
|
Glu |
|
|
Arg |
|
Met |
|
Phe |
|
Leu |
Ser |
|
Phe |
Pro |
|
Thr |
|
|
Thr |
|
|
Lys |
|
Thr |
|
Tyr |
|
Phe |
|
Pro |
|
His |
|
Phe |
|
|
|
|
|
|
Asp |
|
Leu |
|
Ser |
|
|
His |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Gly |
|
|
Ser |
|
|
|
|
Ala |
|
|
|||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Leu |
|
|
Gly |
|
|
|
Arg |
|
Leu |
|
Leu |
|
|
Val |
|
Val |
|
Tyr |
|
Pro |
|
Trp |
|
|
|
Thr |
|
Gln |
|
Arg |
|
Phe |
|
|
Phe |
|
|
Glu |
|
Ser |
|
Phe |
|
|
Gly |
|
Asp |
|
Leu |
|
Ser |
|
|
Thr |
|
|
Pro |
|
Asp |
Ala |
|
Val |
|
Met |
|
Gly |
|
|
Asn |
|
|
|
|
Pro |
|
|
|||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
70 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
80 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
90 |
|
|
|
|
|
|
|
|
|
|
|||
|
Asp |
|
|
Leu |
|
|
|
|
|
Lys |
|
|
|
|
|
|
Ala |
|
Thr |
|
|
|
Leu |
|
|
|
Thr |
|
|
|
|
|
|
Gly |
|
|
Gly |
|
|
Ile |
|
|
Leu |
|
Lys |
|
|
Lys |
|
Lys |
|
Gly |
|
His |
|
His |
|
|
Glu |
Ala |
Glu |
|
Ile |
|
|
|
Lys |
|
Pro |
|
|
|
|
|
|
|
|
Ala |
|
|
||||||||||||||||||||||||||
|
|
|
|
Lys |
|
|
|
His |
|
Gly |
|
|
|
Val |
|
|
|
|
Ala |
|
Leu |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Leu |
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Gln |
|
|
Val |
|
Lys |
|
|
Gly |
|
His |
|
Gly |
|
Lys |
|
Lys |
|
Val |
|
Ala |
|
|
Asp |
|
Ala |
|
Leu |
|
Thr |
|
Asn |
|
Ala |
|
Val |
|
Ala |
|
|
His |
|
Val |
|
Asp |
|
Asp |
|
Met |
|
Pro |
Asn |
Ala |
|
Leu |
|
|
Ser |
|
Ala |
|
Leu |
|
|
|
|
Ser |
|
|
|||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Lys |
|
|
Val |
|
Lys |
|
|
Ala |
|
His |
|
Gly |
|
Lys |
|
Lys |
|
Val |
|
Leu |
|
|
Gly |
|
Ala |
|
Phe |
|
Ser |
|
Asp |
|
Gly |
|
Leu |
|
Ala |
|
|
His |
|
Leu |
|
Asp |
|
Asn |
|
Leu |
|
Lys |
Gly |
Thr |
|
Phe |
|
|
Ala |
|
Thr |
|
Leu |
|
|
Ser |
|
|
|||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
100 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
110 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
120 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
Gln |
|
|
Ser |
|
His |
|
|
Ala |
|
Thr |
|
|
Lys |
|
His |
|
Lys |
|
Ile |
|
Pro |
|
|
|
Val |
|
Lys |
|
Tyr |
|
Leu |
|
|
Glu |
|
|
Phe |
|
|
Ile |
|
Ser |
|
|
Glu |
|
Cys |
|
Ile |
|
Ile |
|
Gln |
|
|
Val |
Leu |
Gln |
|
Ser |
|
|
|
Lys |
|
His |
|
Pro |
|
|
|
Gly |
|
|
|||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Asp |
|
|
|
|
|
|
|
|
|
|
|
Ala |
|
His |
|
|
|
|
|
Arg |
|
|
|
|
|
|
|
|
|
|
Val |
|
|
|
|
|
|
|
Lys |
|
|
|
|
|
|
|
Ser |
|
|
His |
|
Cys |
|
|
|
Leu |
|
His |
|
|
Thr |
|
|
|
|
|
Ala |
|
|
|
|
|
|
Leu |
|
Pro |
|
|
|
|
Ala |
|
|
||||||||||||||||||||||
|
|
|
Leu |
|
His |
|
|
|
|
|
Lys |
|
Leu |
|
|
Val |
|
Asp |
|
|
Pro |
|
|
Asn |
|
Phe |
|
|
|
Leu |
|
Leu |
|
|
|
|
|
Leu |
|
|
|
Leu |
Ala |
|
|
|
His |
|
|
|
|
|
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Glu |
|
|
Leu |
|
His |
|
|
Cys |
|
Asp |
|
|
Lys |
|
Leu |
|
His |
|
Val |
|
Asp |
|
|
|
Pro |
|
Glu |
|
Asn |
|
Phe |
|
|
Arg |
|
|
Leu |
|
|
Leu |
|
Gly |
|
|
Asn |
|
Val |
|
Leu |
|
Val |
|
Asn |
|
|
Val |
Leu |
Ala |
|
His |
|
|
|
His |
|
Phe |
|
Gly |
|
|
Lys |
|
|
||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
130 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
140 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
150 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
Asp |
|
|
Phe |
|
Gly |
|
|
Ala |
|
Asp |
|
|
Ala |
|
Gln |
|
Gly |
|
Ala |
|
Met |
|
|
|
Asn |
|
Lys |
|
Ala |
|
Leu |
|
|
Glu |
|
|
Leu |
|
|
Phe |
|
Arg |
|
|
Lys |
|
Asp |
|
Met |
|
Ala |
|
Ser |
|
|
Asn |
Tyr |
Lys |
|
Glu |
|
|
|
Leu |
|
Gly |
|
Phe |
|
Gln |
|
Gly |
|||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ala |
|
|
|
|
His |
|
|
|
Ser |
|
Leu |
|
|
Asp |
|
|
|
|
Phe |
|
Leu |
|
|
|
|
|
|
Ser |
|
|
|
|
Ser |
|
|
Thr |
|
Val |
|
|
|
Thr |
|
Ser |
|
|
|
|
|
|
|
Arg |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
Glu |
|
|
Phe |
|
Thr |
|
Pro |
|
Val |
Ala |
Lys |
Ala |
Val |
Leu |
Lys |
Tyr |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||
|
Glu |
|
|
Phe |
|
Thr |
|
|
Pro |
|
Pro |
|
|
Val |
|
Gln |
|
Ala |
|
Ala |
|
Tyr |
|
|
|
Gln |
|
Lys |
|
Val |
|
Val |
|
|
Ala |
|
|
|
|
Gly |
|
|
Val |
|
|
Ala |
|
|
Asn |
|
Ala |
|
Leu |
|
Ala |
|
His |
|
|
Lys |
Tyr |
His |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||
α –chain of horse methemoglobin |
β –chain of horse methemoglobin |
Sperm whale myoglobin |
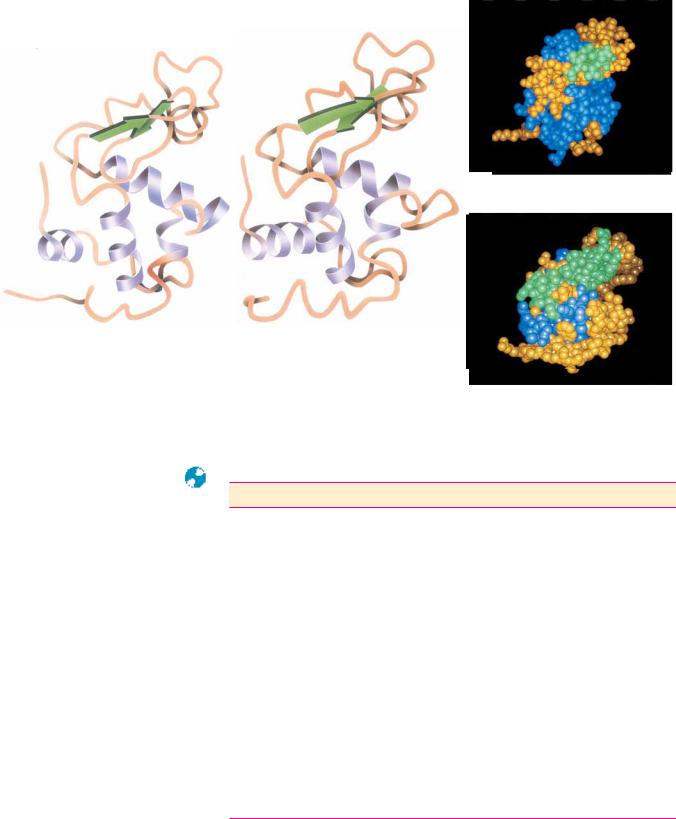
FIGURE 5.30 ● Inspection of the amino acid sequences of the globin chains of human hemoglobin and myoglobin reveals a strong degree of homology. The -globin and
-globin chains share 64 residues of their approximately 140 residues in common. Myoglobin and the -globin chain have 38 amino acid sequence identities. This homology is further reflected in these proteins’ tertiary structure. (Irving Geis)

5.9 ● Synthesis of Polypeptides in the Laboratory |
149 |
hemoglobin variants that have been discovered to date. Some of these are listed in Table 5.9.
A variety of effects on the hemoglobin molecule are seen in these mutants, including alterations in oxygen affinity, heme affinity, stability, solubility, and subunit interactions between the -globin and -globin polypeptide chains. Some variants show no apparent changes, whereas others, such as HbS, sicklecell hemoglobin (see Chapter 15), result in serious illness. This diversity of response indicates that some amino acid changes are relatively unimportant, whereas others drastically alter one or more functions of a protein.
5.9 ● Synthesis of Polypeptides in the Laboratory
Chemical synthesis of peptides and polypeptides of defined sequence can be carried out in the laboratory. Formation of peptide bonds linking amino acids together is not a chemically complex process, but making a specific peptide can be challenging because various functional groups present on side chains of amino acids may also react under the conditions used to form peptide bonds. Furthermore, if correct sequences are to be synthesized, the -COOH group of residue x must be linked to the -NH2 group of neighboring residue y in a way that prevents reaction of the amino group of x with the carboxyl group of y. Ingenious synthetic strategies are required to circumvent these technical problems. In essence, any functional groups to be excluded from reaction must be blocked while the desired coupling reactions proceed. Also, the blocking groups must be removable later under conditions in which the newly formed peptide bonds are stable. These limitations mean that addition of each amino acid requires several steps. Further, all reactions must proceed with high yield if peptide recoveries are to be acceptable. Peptide formation between amino and carboxyl groups is not spontaneous under normal conditions (see Chapter 4), so one or the other of these groups must be activated to facilitate the reaction. Despite these difficulties, biologically active peptides and polypeptides have been recreated by synthetic organic chemistry. Milestones include the pioneering synthesis of the nonapeptide posterior pituitary hormones oxytocin and vasopressin by du Vigneaud in 1953, and in later years, the blood pres- sure–regulating hormone bradykinin (9 residues), melanocyte-stimulating hormone (24 residues), adrenocorticotropin (39 residues), insulin (21 A-chain and 30 B-chain residues), and ribonuclease A (124 residues).
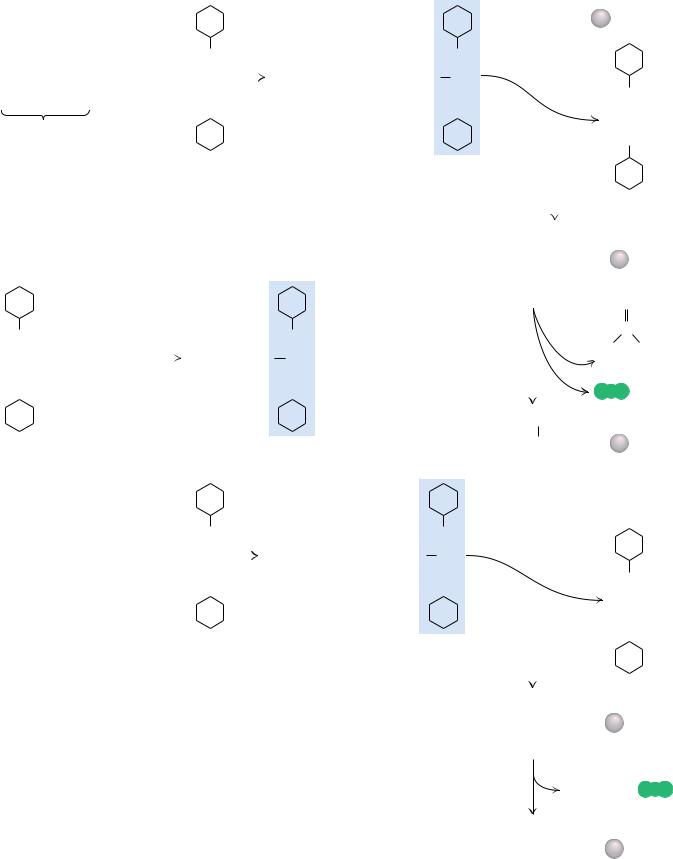
Solid Phase Peptide Synthesis
Bruce Merrifield and his collaborators found a clever solution to the problem of recovering intermediate products in the course of a synthesis. The carboxylterminal residues of synthesized peptide chains were covalently anchored to an insoluble resin particle large enough to be removed from reaction mixtures simply by filtration. After each new residue was added successively at the free amino-terminus, the elongated product was recovered by filtration and readied for the next synthetic step. Because the growing peptide chain was coupled to an insoluble resin bead, the method is called solid phase synthesis. The procedure is detailed in Figure 5.33. This cyclic process has been automated and computer controlled so that the reactions take place in a small cup with reagents being pumped in and removed as programmed. The 124-residue-long bovine pancreatic ribonuclease A sequence was synthesized, and the final product was enzymatically active as an RNase.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Aminoacyl- |
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
resin particle |
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
R1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
H2N |
|
CHC |
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
N |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
N |
|
|
|
|
|
|
|
|
|
|
|
|
O |
|
|
|
|
|
|||||||||
|
|
|
|
CH3 |
|
|
|
|
|
|
|
R2 |
|
|
|
|
|
|
|
|
|
|
|
CH3 |
|
|
|
|
|
R2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
CH3 |
|
C |
|
O |
|
|
C |
|
|
|
NHCHCOOH + |
|
C |
|
|
|
|
|
|
|
CH3 |
|
C |
|
O |
|
C |
|
|
NHCHC |
|
O |
C |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
NH |
|
||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
N |
|
|
|
|
|
|
|
|
|
CH3 |
|
|
O |
|
|
|
|
|
|
|
|
|
NH |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
CH3 |
|
O |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
O |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
|
Blocking group |
|
|
|
|
|
|
Incoming |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
C |
|
O |
|
|||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
blocked |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
NH |
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
amino acid |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Dicyclohexyl- |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Activated |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
carbodiimide |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
amino acid |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Dicyclohexylurea |
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
CH3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
CH3 |
|
|
|
|
|
|
R2 |
|
R1 |
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
CH3 |
|
|
C |
|
|
O |
|
C |
|
Cl |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Amino-blocked |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
dipeptidyl- |
CH3 |
|
C |
|
O |
|
C |
|
|
NHCHCNHCHC |
|
|
|
|
|
|
||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
CH3 |
O |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
resin particle |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
BocCl |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
CH3 |
|
O |
|
|
|
|
|
O |
|
|
|
O |
|
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
CH2 |
|
|||
|
N |
|
|
|
|
|
|
R |
|
O |
|
|
|
|
R O |
|
N |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Acid |
|
|
|
|
|
|
|
|
|
|
C |
|
|
|
||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
H3C |
CH3 |
|
|||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
+ H2N |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
|
C |
|
C |
|
C |
|
OH |
|
|
H2N |
|
C |
|
C |
|
O C |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Isobutylene |
||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
N |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
NH |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
H |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
H |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
CO2 |
|
|
|
||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
R2 |
|
R1 |
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Dipeptide-resin |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
Dicyclohexyl- |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Activated |
|
|
|
|
|
|
|
|
|
|
H2NCHCNHCHC |
|
|
|
|
|
|
||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
particle |
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||||||||||||||
carbodiimide |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
amino acid |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
O |
|
|
|
O |
|
|
|
||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
CH3 |
|
|
|
|
|
|
R3 |
N |
|
|
|
CH3 |
|
|
|
|
|
|
R3 |
|
|
|
|
|
|
N |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
CH3 |
|
C |
|
O |
|
C |
|
|
|
NHCHCOOH + |
C |
|
|
|
CH3 |
|
C |
|
O |
|
C |
|
|
NHCHC |
|
|
|
O |
|
C |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
NH |
|
||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
|
CH3 |
|
|
O |
|
|
|
|
|
|
|
|
|
|
CH3 |
|
O |
|
|
|
|
O |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||
|
|
|
|
|
|
|
|
N |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
NH |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Incoming blocked |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
C |
|
O |
||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
amino acid |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
NH |
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
FIGURE 5.33 ● |
Solid phase synthesis of a peptide. (inset) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Activated |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
amino acid |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||||
Tertiary butyloxycarbonyl chloride (tBocCl) is an excellent |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||
reagent for blocking amino groups of amino acids during |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
CH3 |
|
|
|
|
|
|
|
|
R3 |
R2 |
R1 |
|
|||||||||||||||||||||||||||||||||||||
organic synthesis. Dicyclohexylcarbodiimide (DCCD) is a pow- |
Amino-blocked |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
erful agent for activating carboxyl groups to condense with |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||||||
CH3 |
|
|
|
C |
|
|
O |
|
|
C |
|
|
|
NHCHC NHCHCNHCHC |
|
|
|
|
|
|
||||||||||||||||||||||||||||||||||||||||||||||
amino groups to form peptide bonds. The carboxyl group of |
tripeptidyl- |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||||||||||||||||
resin particle |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||||
the first amino acid (the carboxyl-terminal amino acid of the |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
CH3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
O |
|
|
|
O |
|
O |
|
O |
|
||||||||||||||||||||||||||||||||||||||
peptide to be synthesized) is attached to an insoluble resin |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||
particle (the aminoacyl-resin particle). The next amino acid, |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||
with its amino group blocked by a tBoc group and its carboxyl |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Acid |
|
|
|
|
|
|
+ |
|
|
||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Isobutylene |
|
CO2 |
||||||||||||||||||||||||||||||||
group activated with DCCD, is reacted with the aminoacyl- |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||||
resin particle to form a peptide linkage, with elimination of |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||
DCCD as dicyclohexylurea. Acid treatment removes the N-ter- |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
R3 |
R2 |
R1 |
|
|||||||||||||||||||||||||||||||||
minal tBoc blocking group as the gaseous products CO2 and |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
Tripeptidyl-resin |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||||||||||||
isobutylene, exposing the N-terminus of the dipeptide for |
|
|
|
|
|
|
|
|
|
|
|
|
H2NCHC |
|
NHCHC |
|
NHCHC |
|
|
|
|
|
|
|
|
|||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
particle |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||||||||||||
another cycle of amino acid addition. The growing peptide |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||
chain is easily recovered after cyclic additions of amino acids |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
O |
|
O |
|
O |
|
||||||||||||||||||||||||||||||
simply by filtering or centrifuging the reaction mixture. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||
150