

MonografiaOxana_tanya
.pdfвизначити місце цієї точки у всій сукупності, що дозволяє їх упорядкувати та класифікувати.
У залежності від цілей проведеного дослідження таксономічні методи можна розподілити на три групи: методи упорядкування, методи розбивання, методи вибору репрезентантів груп.
Перша група включає методи, що упорядковують одиниці досліджуваної сукупності, причому тут можна зазначити два напрями. В
одному випадку досягається лінійне упорядкування, в іншому – нелінійне.
Лінійне упорядкування (наприклад, методом Чекановського) полягає у проектуванні точок багатомірного простору на пряму [91].
Вроцлавські математики [92] розробили так називаний метод дендритів (іменований також вроцлавською таксономією), при якому точки багатомірного простору проектуються на площину, чим досягається нелінійне упорядкування досліджуваних елементів.
Вроцлавська таксономія знаходить усе більше застосування у багатьох економічних дисциплінах як у своєму первісному вигляді, так і в подальших модифікаціях. Особливе значення має тут робота З.Хельвига
[28], у якій автор, зокрема, подав концепцію так званого показника рівня розвитку, відповідно до якої досліджувані об'єкти упорядковуються за відстанями до деякої штучно сконструйованої точки, що була називана еталоном розвитку.
Друга група методів має справу з задачами розбивання множини на групи однорідних елементів. Серед них можна зазначити метод Чекановського, пристосований для проведення територіально-економічних досліджень завдяки тому, що в ньому враховується інформація про зв'язки між всіма об'єктами ( чи розташовані вони далеко або близько одне від одного). Іншим методом, що широко використовується є так називаний метод куль. Він менш трудомісткий, ніж інші методи, що є його достоїнством.
Третя група таксономічних методів застосовується з метою вибору
131
репрезентантів груп. Вона має велике значення, особливо при знаходженні так званих діагностичних ознак, тобто ознак, що передають найістотніші риси досить численного набору вихідних ознак.
Іншим цілям служить факторний аналіз. Головною його метою є встановлення загальних закономірностей, що визначають сутність досліджуваного явища. Матеріалом, на базі якого проводяться такі дослідження, служать спостереження над варіацією значень безлічі ознак,
що характеризують дане явище. Безпосереднє розкриття існуючих закономірностей буває досить ускладнено, а іноді й просто неможливе,
якщо розглянута множина ознак виявляється настільки великою, що надлишок інформації починає заважати розумінню найбільш істотних взаємозв'язків. Виявлення закономірностей спрощується, якщо серед розглянутих ознак знайдуться такі, що дуже корельовані між собою і тому мало відрізняються одне від одного у відношенні до інформації про явище, що досліджується. У таких випадках варто замінити групу дуже корельованих ознак якоюсь розрахунковою "синтетичною" величиною.
Отримана величина після інтерпретації (що відповідає області дослідження) називається фактором і розглядається як одна з закономірностей явища, що досліджується.
Така заміна груп корельованих ознак факторами повинна відбуватися з найменшими втратами інформації, укладеної у вихідній безлічі ознак. Теоретично повне відображення інформації, що міститься в деякій безлічі ознак, досягається лише в тому випадку, коли кількість факторів дорівнює кількості ознак. На практиці ж найчастіше така умова не є необхідною, оскільки лише першим факторам (трьом-чотирьом)
вдається дати ясну економічну інтерпретацію, і, що особливо важливо, при цьому вже досягається досить повне відображення інформації.
Дуже часто методи факторного та кластерного аналізу використовуються у маркетингових дослідженнях при розбитті на групи споживачів якогось товару або послуги.
132
Найбільш популярним є метод кластерного аналізу [34]. Це пояснюється універсальністю цього методу при рішенні досить широкого кола маркетингових задач, відносною простотою інтерпретації результатів.
Кластер ний аналіз застосовується не тільки для сигметування споживачів,
але й для рішення великої кількості інших аналітичних задач, що постають перед дослідником. Іншим досить популярним інструментом аналізу є факторний аналіз, що дозволяє скоротити кількість параметрів вибірки до істотно меншої кількості. Спільне використання двох даних інструментів:
факторного та кластерного аналізу – дозволяє в багатьох випадках істотно спростити задачі, що пов’язані з необхідністю класифікації респондентів,
та в цілому підвищити рівень дослідницької роботи.
5.2 Оцінка та прогнозування неплатоспроможності підприємств
на основі методів кластерного аналізу
У пункті 4.2 були розглянуті моделі багатовимірного дискримінантного аналізу для оцінки ймовірності банкрутства організацій.
Виникає питання, в якому сенсі інтегральний показник фінансового стану підприємства на визначений момент часу, що є розрахованим за допомогою дискримінантної функції за його фактичними даними, є
прогнозним.
Звичайно прогноз, який зроблений на момент часу t, містить
твердження, що деяка подія повинна відбутися у момент часу t+k.
Елементами таких прогнозів є очікувані значення показників.
Оскільки при розрахунку інтегральних показників фінансового стану |
|
підприємства на визначений момент часу tn |
не використовуються |
показники очікувань, виникає питання: в |
якому сенсі вони є |
прогнозованими? |
У тому, що значення |
інтегральних |
показників |
|||
фінансового стану підприємства, які |
розраховані |
на |
основі |
|||
дискримінантної |
функції, |
оцінюються |
до |
настання |
їх |
|
133
неплатоспроможності. Фактично ці інтегральні показники, при умові деякої стабільності, включають до себе елементи очікування.
Взагалі задача розпізнавання фази неплатоспроможності підприємства відноситься до класу задач, які вирішуються у рамках теорії розпізнавання образів з використанням економіко-математичних методів.
Даною проблемою займалися деякі вчені: М.Бонгард, Ю.Горелик,
Н.Загоруйко, Ю.Неймарк, В.Ташеві та ін. [51]. Спираючись на праці наведених вище вчених, схему основних економіко-математичних методів,
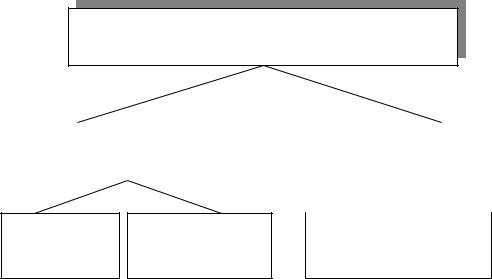
що використовуються в теорії розпізнавання образів, можна зобразити таким чином (рис. 5.1), а відмітні їх особливості наведені в таблиці 5.1
Теорія розпізнавання образів
Статистичні |
|
|
Штучні інтелектуальні |
|
методи |
|
|
системи |
|
|
|
|
|
|
|
|
|
|
|
Кластерний |
Дискримінантний |
Нейроні мережі |
аналіз |
аналіз |
|
Рис 5.1 Класифікація основних економіко-математичних методів,
що використовуються у теорії розпізнавання образів
Враховуючи усе вище згадане, вирішити задачу розпізнавання фази неплатоспроможності підприємства та її прогнозування можливо тільки,
використовуючи разом два методи – кластерний и дискримінантний аналіз.
За допомогою кластерного методу можна провести розбиття сукупності підприємств на дві групи: платоспроможні та неплатоспроможні, у
залежності від змінних, що їх оцінюють. Далі на основі дискримінантного аналізу побудувати рівняння моделі, за допомогою якого можна буде
134
розпізнати фазу неплатоспроможності різних об’єктів, що досліджується на визначений момент часу tn, розрахувати інтегральний показник його фінансового стану, а також спрогнозувати його зміну.
Таблиця 5.1
Відмітні особливості основних економіко-математичних методів, що використовуються у теорії розпізнавання образів
|
|
|
|
Штучні |
|
Порівнювані |
Статистичні методи |
інтелектуальні |
|||
|
|
|
системи |
||
елементи |
|
|
|
||
Кластерний |
Дискримінантний |
Нейроні |
|||
|
|||||
|
аналіз |
аналіз |
мережі |
||
Кількість |
Необхідно |
Задана |
|||
кластерів (груп) |
визначити |
||||
|
|
|
|||
Метод |
Евристичний |
Імовірнісний метод, що базується на |
|||
обґрунтування |
|||||
метод, заснований |
обширних статистичних |
||||
рішень, що |
|||||
на алгоритмах |
розрахунках |
|
|||
використовується |
|
||||
|
|
|
|
||
Оптимальність |
Краще рішення, |
|
|
|
|
рішення |
що не є |
|
|
|
|
|
оптимальним у |
Оптимальне рішення |
|||
|
математичному |
|
|
|
|
|
сенсі |
|
|
|
|
Кінцевий |
Відображення |
Рівняння моделі |
|
|
|
результат |
графічною |
|
Відображення |
||
та розв’язуюче |
|
||||
|
дендрограмою або |
|
мережею |
||
|
правило |
|
|||
|
таблицею |
|
|
||
|
|
|
|
||
Вихідні дані |
|
Статистичні дані |
|
||
Наявність |
Без навчальної |
|
|
|
|
навчальної |
З навчальною вибіркою |
||||
вибірки |
|||||
вибірки |
|
|
|
||
|
|
|
|
||
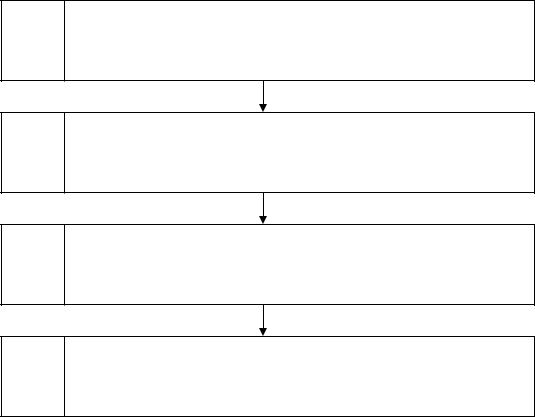
Враховуючи сказане вище, алгоритм оцінки та прогнозування неплатоспроможності підприємства можна подати наступним чином (рис.
5. 2)
Перший етап являє собою розрахунок фінансових коефіцієнтів на основі даних фінансової звітності (див. п. 2.2).
Роздивимось детальніше другий етап. Як зі схеми алгоритму оцінки та прогнозування неплатоспроможності підприємств (рис. 5.2), для
135
розбиття наявної сукупності підприємств на платоспроможні та
неплатоспроможні необхідно використовувати кластерний аналіз.
1 етап
2 етап
3 етап
4 етап
Оцінка фінансового стану наявної сукупності підприємств з використанням системи часних показників
Розбиття наявної сукупності підприємств на платоспроможні та неплатоспроможні на основі кластерного аналізу
Побудова дискримінантної моделі та розрахунок інтегрального показника оцінки фінансового стану підприємства
Визначення напряму зміни фінансового стану підприємства на основі матриці
Рис. 5.2 Алгоритм оцінки та прогнозування неплатоспроможності підприємства
У відповідності до теорієї кластерного аналізу, що викладена у роботах вчених Айвазяна С., Жамбю М., Плюти В., Дюрана В., Одела П. та ін. [1, 2, 34, 40, 91, 92], існують два основні методи кластеризації:
ієрархічний та неієрархічний, що мають у свою чергу різновиди.
При ієрархічній кластеризації об'єкти (окремі спостереження або кластери), що потрапили до кластера, залишаються об'єднаними на всіх подальших етапах кластеризації. Методи розрізняються за способами оцінки відстані між кластерами.
136
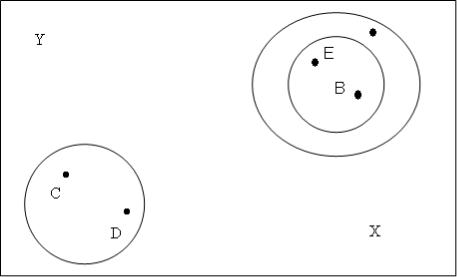
A
Рис. 5.3 Ієрархічна кластеризація
Рисунок 5.3 ілюструє просте рішення методом ієрархічної кластеризації. Об'єкти В і Е є найбільш близькими один до одного і формують кластер. При злитті цього кластера з об'єктом А до нового кластера будуть включено обидва об'єкти: як В, так і Е. Це властивість,
тобто збереження в одному кластері вже приєднаних об'єктів, є визначним для ієрархічної кластеризації.
Неієрархічні методи не вимагають, щоб об'єкти, які потрапили до кластера, залишалися у цьому ж кластері протягом усього подальшого процесу кластеризації. Одним з найбільш поширених методів неієрархічної кластеризації є алгоритм k-середніх. При його використанні треба заздалегідь задати необхідну кількість кластерів, і робота алгоритму приведе до створення з даних саме заданої кількості кластерів. Кількість кластерів підбирається експериментально: як правило, робиться декілька спроб кластеризації з різною кількістю кластерів, і потім результати порівнюються, і вибирається остаточне рішення (можуть використовуватися згадані вище критерії –кількість спостережень на групу, профілі середніх, верифікація).
У таблиці 5.2 наведена порівняльна характеристика основних
137
методів ієрархічної та неієрархічної кластеризації, що найбільш часто використовуються в економічних дослідженнях та реалізовані у пакеті
«STATISTICA 6.0» [18].
Таблиця 5.2
Порівняльна характеристика основних методів кластеризації
|
Методи кластеризації |
||
Характерні |
Ієрархічна |
Неієрархічна |
|
особливості |
Агломеративні |
Дивізійні |
Еталоні |
|
(k-середніх) |
||
|
|
|
|
Кількість |
Не задана |
|
Задана |
кластерів |
|
|
|
Масив вихідної |
Невеликий |
|
Великий |
інформації |
|
|
|
Кластери, що |
Відсутні |
|
Можливі |
перетинаються |
|
|
|
|
|
|
Високий при |
|
|
|
виборі типу |
Ступінь |
Висока при визначенні порогу, |
класифікаційних |
|
використання |
коли необхідно припинити |
процедур та |
|
інтуїції |
кластерізацію |
|
завдання |
|
|
|
початкових умов |
|
|
|
розбиття |
Процес |
Поступове |
Поступове |
Поступове |
кластеризації |
об’єднання |
розбиття |
приєднання |
|
кластерів |
кластерів |
кластерів |
У відповідності до таблиці 5. 2 та зробленої вище постановки задачі,
розбиття наявної сукупності підприємств на платоспроможні та неплатоспроможні відбувалось за допомогою метода неієрархічної кластеризації – ітераційного групування k-середніх. Доцільність використання даного метода кластеризації підтверджують дослідження Менделя І.Д. [51].
На рисунку 5.4 подано алгоритм проведення кластеризації на основі ітераційного кластерного аналізу k-середніх.
138
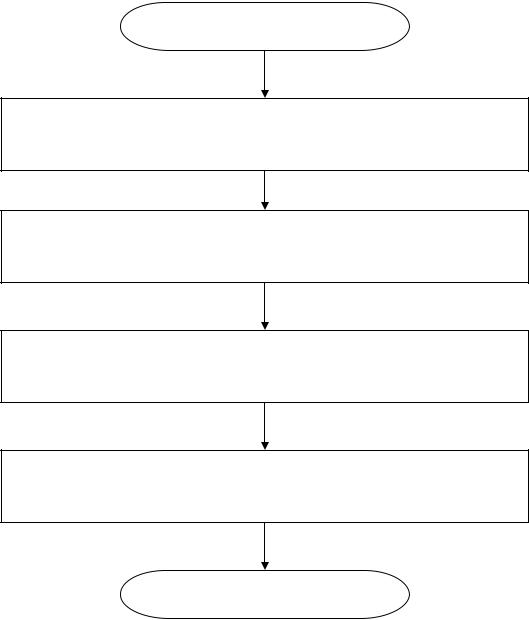
Початок
Відбір підприємств, що належать кластерізації, та показників, що характеризують їх фінансовий стан
Процедура кластерізації підприємств (на основі пакету «STATISTICA 6.0»)
Інтерпретація отриманих кластерів підприємств
Перевірка якості класифікації підприємств
Кінець
Рис. 5. 4. Алгоритм класифікації підприємств на основі кластерного аналізу k-середніх
У відповідності до алгоритму на першому етапі проведення кластерного аналізу k-середніх необхідно відібрати підприємства, що належать кластеризації, та показники, що характеризують їх фінансовий стан. У додатку А (табл.А1…табл.А6) запропоновано перелік фінансових показників, що характеризують фінансовий стан підприємства.
На другому етапі відбувається сама процедура кластеризації. Для її
139
реалізації використовується пакет прикладних програм «STATISTICA 6.0»,
опис застосування якого викладено у роботі [18].
На третьому етапі кластеризації проводиться інтерпретація отриманих кластерів підприємств. У нашому випадку у відповідності до постановки задачі задавалося два кластери підприємств: платоспроможні
та неплатоспроможні.
На заключному етапі кластеризації відбувається перевірка якості
класифікації підприємств.
У теорії вченими пропонується велика кількість формальних процедур оцінки надійності та достовірності рішень кластеризації.
Наприклад, Мендель І.Д. наводить 46 функціоналів якості класифікації.
Тамашевіч В.Н., роздивляючись проблеми якості класифікації,
запропонував для цих цілей використовувати три основні найбільш поширені функціонали: 1) сума квадратів відстаней до центрів класів; 2)
сума відстаней між об’єктами у середині класів; 3) сумарна дисперсія у
середині класів [51]. |
|
|
|
||||||
Роздивимось ці функціонали якості. |
|
||||||||
1 Сума квадратів відстаней до центрів класів: |
|
||||||||
|
|
|
|
|
|
F1 d 2 ( X i |
X l ) min , |
(5.1) |
|
|
|
|
|
|
|
k |
|
|
|
|
|
|
|
|
|
l 1 i S |
|
|
|
де l – номер кластера; |
|
|
|
||||||
|
|
|
|
|
|
|
|
||
|
|
X – центр l -го кластера; |
|
|
|
||||
|
|
X i – вектор значень змінних для i -го об’єкта, що входить до l -го |
|||||||
|
|
|
|
кластера; |
|
|
|
||
|
d 2 ( X |
|
|
|
|||||
|
i |
X l ) – відстань між i -м об’єктом та центром l -го кластера. |
|||||||
|
|
|
|
|
|
|
|
|
|
2 |
Сума відстаней між об’єктами у середині класів: |
|
|||||||
|
|
|
|
|
|
F2 dij2 |
max . |
(5.2) |
|
|
|
|
|
|
|
k |
|
|
|
|
|
|
|
|
|
l 1 i , j Sl |
|
|
|
3 |
Сумарна дисперсія у середині класів: |
|
|||||||
140