

2.3.3. Расстановка (хеширование) записей
В некотором смысле альтернативным подходом к организации физических структур данных является расстановка записей.Как и при использовании линейных и нелинейных структур, основной задачей расстановки записей является минимизация расходов на доступ и изменения данных во внутренней и внешней памяти.
Идея расстановки, известной в англоязычной литературе также под термином хеширование,* заключается в том, чтобы при выделении под размещение данных определенного участка памяти так организовать порядок расположения записей в нем, чтобы место для новых записей и поиск старых записей можно было осуществлять на основе некоторого преобразования их ключевых полей.** При образовании(добавлении)новой записи к значению ее ключевого поля применяется специальнаяхеш-функция(или иначе хеш-свертка), которая ставит в соответствие значению ключевого поля, и, следовательно, всей записи, некоторое числовое значение, обычно являющееся номером (адресом) местоположения, куда в итоге и помещается соответствующая запись (см. рис. 2.20).
* От англ. to hash – нарезать, крошить, делить месиво, т.е. равномерно перемалывать ключи нолей в адреса (номера) записей.
** Отсюда еще одно название данного подхода—«преобразование ключей», впервые введенное в русской литературе еще в 1956 г. будущим академиком А. П. Ершовым.
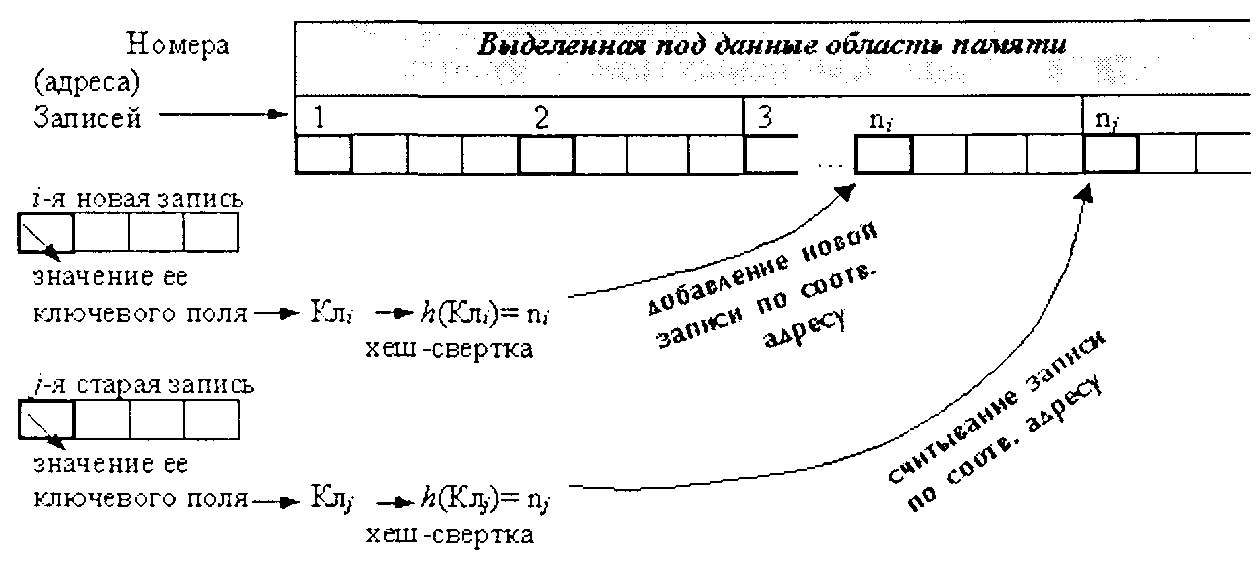
Рис. 2.20. Принцип расстановки записей по значению ключей
При доступе(поиске) нужной записи над значением ее ключевого поля также осуществляется хеш-свертка, что сразу же даст возможность определить местоположение искомой записи и получить к ней доступ.
Таким образом, в идеале хеширование обеспечивает доступ к нужным записям за одно (!!!) обращение к области размещения данных.
Функция преобразования h(Клj) выбирается на основе двух требований: 1) ее результат для возможного диапазона значений ключевого поля должен находиться в пределах диапазона адресов (номеров) области памяти, выделяемой подданные, и 2) значения функции в пределах выделенного диапазона адресов должны быть равномерными. На практике наиболее широкое распространение нашли хеш-функции, основанные на операциях деления по модулю:
h(Клj)=(Клj mod М) + 1,
где (Клj modМ) означает операцию деления по модулю М,*а число М выбирается исходя из необходимости попадания значений хеш-функции в требуемый диапазон.
*Значением операции деления по модулю М является остаток от обычного деления числа на М, например результат деления 213 по модулю 20 равен 13.
Если в качестве М выбрать число, являющееся степенью двух, то подобная хеш-функция эффективно вычисляется процедурами выделения нескольких двоичных цифр.
Для текстовых ключевых полей обычно применяют подобные подходы, основанные на использовании операции сложения по модулю значений кодов первых нескольких символов ключа.
Основной проблемой хеширования с прямой адресацией записей является возможность появления одинаковых значений хеш-сверток при разных значениях полей (так называемые синонимы). Такие ситуации называютсяколлизиями,так как требуют определенного порядка, правила их разрешения.
Применяются два подхода к разрешениюколлизий.Первый подходосновывается на использовании технологиицепных спискови заключается в присоединении к записям, по которым возникают коллизии, специальных дополнительных указателей, по которым размещаются новые записи, конфликтующие по месту расположения с ранее введенными. Как правило, для таких записей отводится специально выделенный участок памяти, называемыйобластью переполнения.В алгоритм доступа добавляются операции перехода по цепному списку для нахождения искомой записи. Вместе с тем при большом количестве переполнении теряется главное достоинство хеширования — доступ к записи за одно обращение к памяти.
Второй подходк разрешению коллизий основывается на использованиидополнительного преобразования ключейпо схеме:
![]()
где n![]() – исходное конфликтующее значение
адреса записи; g(Клi)– дополнительное преобразование ключа;n
– исходное конфликтующее значение
адреса записи; g(Клi)– дополнительное преобразование ключа;n![]() – дополнительное значение адреса.
– дополнительное значение адреса.
При этом могут
встречаться ситуации, когда и такое
дополнительное преобразование
приводит к коллизии, т.е. новое значение
n![]() также оказывается уже занятым. В таких
случаях дополнительное преобразование
g(Клi)чаще всего организуют на основе
рекуррентной процедуры по следующей
схеме:
также оказывается уже занятым. В таких
случаях дополнительное преобразование
g(Клi)чаще всего организуют на основе
рекуррентной процедуры по следующей
схеме:
![]()
где f(k) –некоторая функция над номером итерации (пробы).
В зависимости от вида функции f(k) такие подходы называютлинейнымииликвадратичными пробами.
Основным недостатком второго подхода к разрешению коллизий является во многих случаях существенно больший объем вычислений, а также появление для линейных проб эффектов группирования номеров (адресов) текстовых ключевых полей, т. е. неравномерность номеров, если значения ключей отличаются друг от друга всего несколькими символами.
Вместе с тем коллизии(одинаковые значения хеш-сверток ключей) при использованиистраничной организации структуры файлов баз данныхво внешней памяти получили свое положительное и логичное разрешениеи применение. Значением хеш-свертки ключа в этом случае является номер страницы, куда помещается или где находится соответствующая запись (см. рис. 2.21).
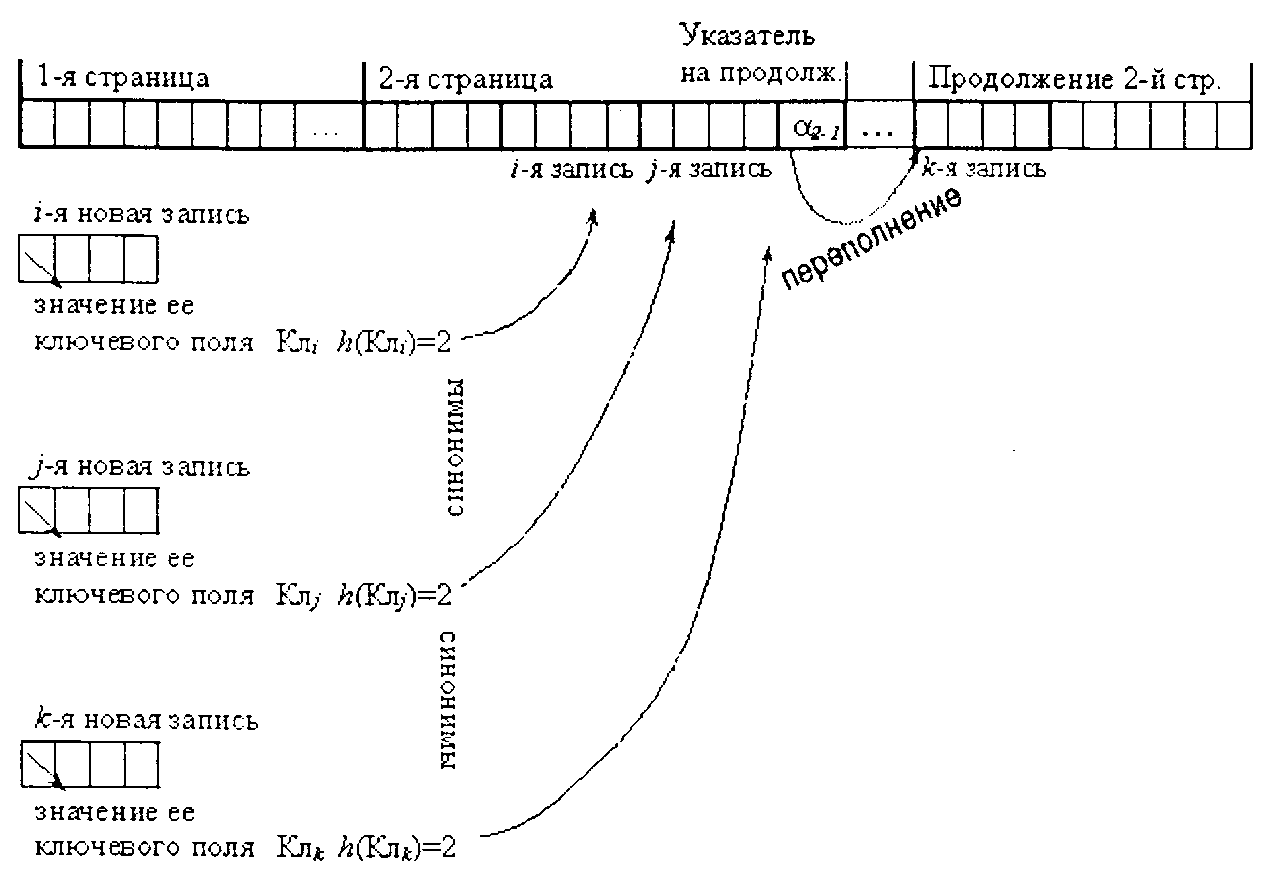
Рис. 2.21. Принцип хеширования записей но страницам файла данных
Для доступак нужной записи сначала производится хэш-свертка значения его ключевого поля и тем самым определяется номер страницы файла базы данных, содержащей нужную запись. Страница файла данных из дисковой пересылается в оперативную память, где путем последовательного перебора отыскивается требуемая запись. Таким образом, при отсутствии переполнении доступ к записям осуществляется за одно страничное считывание данных из внешней памяти.
С учетом того что количество записей, помещающихся в одной странице файла данных, в большинстве случаев достаточно велико, случаи переполнений на практике не так часты. Вместе с тем, при большом количестве записей в таблицах файла данных, количество переполнении может существенно возрасти и так же, как и в классическом подходе, теряется главное достоинство хэширования — доступ к записям за одну пересылку страницы в оперативную память. Для смягчения подобных ситуаций могут применяться комбинации хэширования и структуры Б-деревьев для размещения записей по страницам в случаях переполнения.
Внутренняя схема базы данных обычно скрыта от пользователей информационной системы, за исключением возможности установления и использования индексации полей. Вместе с тем, особенности физической структуры файлов данных и индексных массивов, принципы организации и использования дискового пространства и внутренней памяти, реализуемые конкретной СУБД, должны учитываться проектировщиками банков данных, так как эти «прозрачные» для пользователей-абонентов особенности СУБД критично влияют на эффективность обработки данных в информационной системе.