

4. Ввод, обработка и вывод данных в фактографических аис
Как уже отмечалось, цикл функционирования автоматизированных информационных систем включает сбор, комплектование данных, поиск и выдачу сведений для удовлетворения информационных потребностей абонентов систем. Если исключить организационно-технологические аспекты сбора, комплектования и выдачи информации, технология работы пользователей с базами данных АИС включает ввод (загрузку), обработку и вывод данных.
Предоставление пользователю средств реализации функций ввода, обработки и выдачи данных является одной из основных функций интерфейса автоматизированных информационных систем.
4.1. Языки баз данных
Как следует из рассмотрения внутренней схемы баз данных, одной из основных функций систем управления базами данных является создание и поддержание собственной системы размещения и обмена данными между внешней (дисковой) и оперативной памятью. От эффективности реализации в каждой конкретной СУБД данной функции (формат файлов данных, индексирование, хэширование и буферизация) во многом зависит и эффективность функционирования СУБД в целом. Поэтому основные усилия создателей первых СУБД в конце 60-х — начале 70-х годов были сосредоточены именно в этом направлении.
Однако такой подход приводил к «самостийности», уникальности каждой конкретной СУБД и созданной на ее основе автоматизированной информационной системы. В результате для реализации любой функции по вводу, обработке или выводу данных требовались квалифицированные программисты для написания специальных программ на алгоритмических языках высокого уровня (в 70-х годах ФОРТРАН, КОБОЛ и др.), «знающих» особенности структуры и способы размещения данных во внешней и оперативной памяти. В итоге работа с базами данных осуществлялась через посредника в виде квалифицированного программиста, «переводящего» информационные потребности пользователя в машинный код,* что схематично иллюстрируется на рис. 4.1.
* В этом плане примечателен афоризм Чарльза Бахмана, который метко подметил, что «программист— это штурман в море данных». Статью по поводу присуждения ему премии Тьюринга за пионерские работы в области технологий баз данных он так и назвал — «The Programmer As Navigator»(Программист как штурман). [Вацкевич Д. Стратегии клиент/сервер, – К.: Диалектика, 1996. С. 216.]
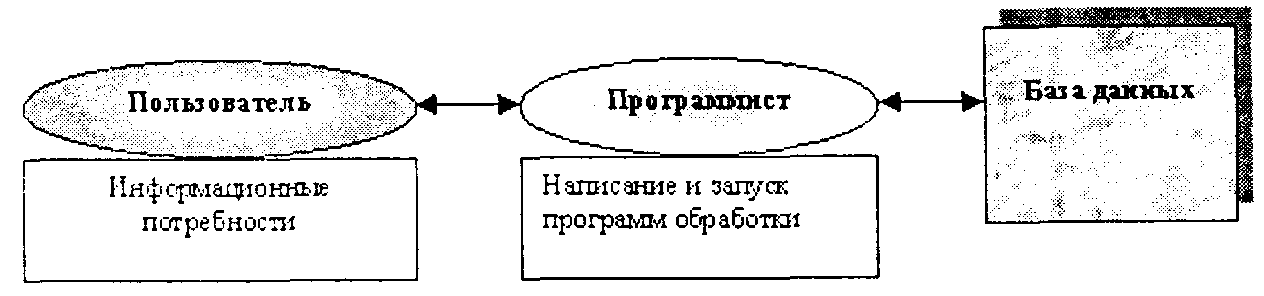
Рис. 4.1. Схема взаимодействия пользователя с базой данных в ранних СУБД
Такое положение дел приводило к большим накладным расходам при создании и эксплуатации автоматизированных информационных систем и в определенной степени сдерживало распространение вычислительной техники в процессах информационного обеспечения деятельности предприятий и организаций.
Основателем теории реляционных СУБД Е. Коддом было выдвинуто предложение о создании специального языка для общения(взаимодействия)пользователя-непрограммиста с базами данных.Идея такого языка сводилась к набору из нескольких фраз-примитивов английского языка («выбрать», «обновить», «вставить», «удалить»), через которые пользователь-непрограммист ставил бы «вопросы» к СУБД по своим информационным потребностям. В этом случае дополнительной функцией СУБД должна быть интерпретация этих «вопросов» на низкоуровневый язык машинных кодов для непосредственной обработки данных и предоставление результатов пользователю. Так родилась уже упоминавшаяся по структуре СУБД «машина данных». Иначе говоря, машина данных «понимает» язык базы данных и в результате разделяет собственно данные и задачи по их обработке. В таком подходе взаимодействие пользователя с базой данных можно проиллюстрировать схемой, приведенной на рис. 4.2.

Рис. 4.2. Схема взаимодействия пользователя с базой данных через язык баз данных
В практику эти идеи впервые претворились в ходе реализации проекта System R(1975-1979 гг.) с участием еще одного известного специалиста по базам данных Криса Дейта. В ходе проекта System Rбыл создан язык SEQUEL,трансформировавшийся впоследствии в язык структурированных запросов SQL (Structured Query Language).*При этом дополнительно к возможностям формирования «вопросов» к базе данных пользователю также решено было предоставить и возможность описания самой структуры данных, ввода данных и их изменения.
* Добавим также, что примерно в то же время в компании IBMбыл создан еще один реляционный язык—QBE (Query-By-Example),т. е. язык запросов по образцу, применявшийся впоследствии во многих коммерческих системах обработки табличных данных и послуживший идеологической основой для создания визуальных «конструкторов» запросов в современных СУБД.
Идеи языка SQLоказались настолько плодотворными, что он быстро завоевал популярность и стал широко внедряться в создаваемых в конце 70-х и в 80-х годах реляционных СУБД. Однако плодотворность идей языка SQLв отличие от первоначального замысла проявилась вовсе не в том, что на нем стали «разговаривать» с базами данных пользователи, не являющиеся профессиональными программистами. Язык SQL,в конечном счете, позволил, как уже отмечалось,отделить низкоуровневые функции по организации структуры и обработке данных от высокоуровневых функций,позволяя при создании и эксплуатации банков данных сосредоточиваться на смысловом, а не техническом аспекте работы с данными.
Быстрое и массовое распространение языка SQLв реляционных СУБД к середине 80-х годов привело фактически к принятию его в качестве стандартапо организации и обработке данных. В 1986 г. Американским национальным институтом стандартов (ANSI)и Международной организацией по стандартизации (ISO)язык был стандартизирован де-юре, т. е. признан стандартным языком описания и обработки данных в реляционных СУБД. В 1989 г. ANSI/ISOбыла принята усовершенствованная версия SQL— SQL2,а в 1992 г. третья версия — SQL3.
Язык SQLотносится к так называемым декларативным (непроцедурным) языкам программирования. В отличие от процедурных языков (С, Паскаль, Фортран, Кобол, Бейсик) на нем формулируются предложения (инструкции) о том, «что сделать», но не «как сделать, как получить».Машина данныхв СУБД исполняет рольинтерпретатораи как раз строит машинный код, реализующий способ получения результата, задаваемого SQL-инструкциями.
Язык SQLсостоит издвухчастей:
• языка описания (определения) данных — DDL (Data Definition Language);
• языка манипулирования данными — DML (Data Manipulation Language).
Синтаксис SQL-инструкцийвключает:
• названиеинструкции (команду);
• предложения,определяющие источники, условия операции;
• предикаты,определяющие способы и режимы отбора записей, задаваемых предложениями;
• выражения,значения которых задают свойства и параметры выполнения инструкции и предложения.
Структуру SQL-инструкций можно разделить на две основные части, схематично представленные на рис. 4.3.*
* Квадратные скобки, как это общепринято, означают необязательность элемента

Рис. 4.3. Структура SQL-инструкций.
Первая часть включает название (команду) SQL-инструкции, предикат (необязательный элемент) и аргументы инструкции, которыми являются перечисляемые через запятую имена полей одной или нескольких таблиц.
Вторая часть состоит из одного или нескольких предложений, аргументы которых могут задавать источники данных (имена таблиц, операции над таблицами), способы, условия и режимы выполнения команды (предикаты сравнения, логические и математические выражения по значениям полей таблиц).
Перечень SQL-инструкций разделяется по частям языка SQL.
В состав языка DDLвходят несколько базовых инструкций, обеспечивающих основной набор функций присоздании реляционных таблици связей между ними.
CREATETABLE... —создать таблицу;
CREATEINDEX... —создать индекс;
ALTERTABLE... —изменить структуру ранее созданной таблицы;
DROP... —удалить существующую таблицу и базы данных.
В структуре инструкций CREATETABLE иALTERTABLE важную роль играет предложение CONSTRAINT(создать ограничения на значения данных) со следующими установками —NOT NULL(не допускаются нулевые, точнее «пустые» значения по соответствующему полю, иначе говоря, определяется поле с обязательным заполнением), AUTOINC(поле с инкрементальным, т. е. последовательно возрастающим с каждой новой записью, характером значений) и PRIMARY KEY(определение для поля уникального, т. е. без повторов, индекса, что в результате задает режим заполнения данного поля с уникальными неповторяющимися по различным строкам значениями).
В состав языка DMLтакже входят несколько базовых инструкций, охватывающих тем не менее основные операциипо вводу, обработке и выводу данных.
SELECT... —выбрать данные из базы данных;
INSERT... —добавить данные в базу данных;
UPDATE... —обновить данные в базе данных;
DELETE... —удалить данные;
GRANT... —предоставить привилегии пользователю;
REVOKE... —отменить привилегии пользователю;
COMMIT... —зафиксировать текущую транзакцию;
ROLLBACK... —прервать текущую транзакцию.
Важное значение имеют разновидности инструкции SELECT—SELECT... INTO ...(выбрать из одной или нескольких таблиц набор записей, из которого создать новую таблицу) и UNION SELECT,которая в дополнении с исходной инструкцией SELECT (SELECT... UNION SELECT...) реализует операцию объединения таблиц.
Помимо предложения CONSTRAINTв SQL-инструкциях используются следующиепредложения:
FROM... —указывает таблицы или запросы, которые содержат поля, перечисленные в инструкции SELECT;
WHERE... —определяет, какие записи из таблиц, перечисленных в предложении FROM,следует включить в результат выполнения инструкции SELECT, UPDAТЕ или DELETE;
GROUP BY... —объединяет записи с одинаковыми значениями в указанном списке полей в одну запись;
НАVING... —определяет, какие сгруппированные записи отображаются при использовании инструкции SELECT с предложением GROUP BY;
IN... —определяет таблицы в любой внешней базе данных, с которой ядро СУБД может установить связь;
ORDERBY... —сортирует записи, полученные в результате запроса, в порядке возрастания или убывания на основе значений указанного поля или полей.
В качестве источника данных по предложению FROM,помимо таблиц и запросов, могут использоваться также результатыопераций соединения таблиц в трех разновидностях—INNER JOIN... ON..., LEFT JOIN. ..ON... иRIGHT JOIN...ON...(внутреннее соединение, левое и правое внешнее соединение, соответственно*).
* Особенности разновидностей операций соединения рассматриваются в п. 4.3.2.1.2.
Предикатыиспользуются для задания способов и режимов использования записей, отбираемых на основе условий в инструкции SQL.Такими предикатами являются:
ALL... —отбирает все записи, соответствующие условиям, заданным в инструкции SQL,используется по умолчанию;
DISTINCT... —исключает записи, которые содержат повторяющиеся значения в выбранных полях;
DISTINCTROW... —опускает данные, основанные на целиком повторяющихся записях, а не на отдельных повторяющихся полях;
ТОРп... —возвращаетпзаписей, находящихся в начале или в конце диапазона, описанного с помощьюпредложения ORDER BY;
Выражениямив инструкциях SQLявляются любые комбинации операторов, констант, значений текстовых констант, функций, имен полей, построенные по правилам математических выражений и результатом которых является конкретное, в том числе и логическое значение.
Язык SQL,конечно же, с точки зрения профессиональных программистов построен довольно просто, но, вместе с тем, как уже отмечалось, надежды на то, что на нем станут общаться с базами данных пользователи-непрограммисты, не оправдались. Причина этого, вероятно, заключается в том, что, несмотря на простоту, язык SQLвсе же является формализованным искусственным языком, осваивание и использование которого в большинстве случаев тяготит конечных пользователей. Исследования основ и способов интерфейса человека с компьютером, эргономических и психологических основ работы с компьютерной информацией, проведенные в конце 70-х и в 80-х годах, показали, что пользователи-специалисты в конкретных предметных областях (а не в области вычислительной техники и программирования) более склонны к диалогово-визуальным формам работы с вычислительными системами и компьютерной информацией.
Поэтому с конца 80-х годов в развитии СУБД наметились две тенденции:
• СУБД для конечных пользователей;
• СУБД для программистов (профессионалов).
В СУБД для конечных пользователейимеется развитый набор диалоговых и визуально-наглядных средств работы с базой данных в виде специальных диалоговых интерфейсов и пошаговых «мастеров»,которые «ведут» пользователя по пути выражения им своих потребностей в обработке данных. Например, при создании новой таблицы соответствующий «мастер» последовательно запрашивает у пользователя имя таблицы, имена, типы и другие параметры полей, индексов и т. д. При этом интерфейсная часть СУБД формирует для ядра СУБД (машины данных) соответствующую и порой весьма сложную инструкцию SQL.
В профессиональных СУБДязык базы данных (SQL)дополняется элементами, присущими процедурным языкам программирования — описателями и средствами работы с различного типа переменными, операторами, функциями, процедурами и т. д. В результате формируется специализированный на работу с данными декларативно-процедурный язык высокого уровня, который встроен в СУБД (точнее надстроен над ядром СУБД). Такие языки называют«включающими»(см. рис. 2.1). На основе включающего языка разрабатываются полностью автономные прикладные информационные системы, реализующие более простой и понятный для специалистов в определенной предметной области (скажем, в бухгалтерии) интерфейс работы с информацией.
С учетом этапов в развитии программных средств СУБД такие языки получили название языков четвертого поколения — 4GL (Forth Generation Language).Языки 4GLмогут быть непосредственно встроены в сами СУБД, а могут существовать в видеотдельных сред программирования.В последнем случае в таких средах разрабатываютсяприкладные частиинформационных систем, реализующие только интерфейс и высокоуровневые функции по обработке данных. За низкоуровневым, как говорят, «сервисом» к данным такие прикладные системы обращаются к SQL-серверам,являющимися отдельными специализированными разновидностями СУБД. «Общение» между прикладными системами и SQL-серверами происходит соответственно на языке SQL.
Свои языки 4GL имеют практически все развитые профессиональные СУБД—Orac/e, SyBase, Informix, Ingres, DB2,отечественная СУБД ЛИНТЕР. Распространенными отдельными средами программирования для создания информационных систем в настоящее время являются системы Visual BasicфирмыMicrosoftи Delphiфирмы Borland Intemational.Кроме того, уже упоминавшиеся CASE-средства автоматизированного проектирования — PowerBuilderфирмы PowerSoft, Oracle Designer фирмы Oracle, SQLWindowsфирмы Guptaи др., также, как правило, имеют свои встроенные языки 4GL.
В заключение следует отметить, что в последнее время наметилась тенденция встраивания развитых языков уровня 4GL и в СУБД для конечных пользователей. В качестве примера можно привести СУБД Accessфирмы Microsoft,имеющей один из наиболее развитых интерфейсов по созданию и работе с базами данных для конечных пользователей, и в то же время оснащенной встроенным языком уровня 4GL — VBA (Visual Basic for Application),являющегося диалектом языка Visual Basic.