

2.2. Модели организации данных
2.2.1. Иерархическая и сетевая модели организации данных
В иерархическоймодели объекты-сущности и отношения предметной области представляются наборами данных, которые имеют строгодревовидную структуру,т. е. допускают только иерархические (структурные) связи-отношения. Иерархическая модель данных была исторически первой, на основе которой в конце 60-х-начале 70-х годов были разработаны первые профессиональные СУБД-СУБД IMS (Information Management System)фирмы IBM,СУБД Totalдля компьютеров НР3000. К иерархическим СУБД также относятся отечественные промышленные СУБД 70-80-х годов «ОКА» и «ИНЭС».
База данных с иерархической моделью данных состоит из упорядоченного набора экземпляров структуры типа «дерево», что иллюстрируется примером на рис. 2.2.
В приведенном примере информационный объект «Отделы» является предком информационного объекта «Подразделения», который, в свою очередь, является предком информационного объекта «Сотрудники». Объект «Подразделения» является потомком объекта «Отделы», а объект «Сотрудники» потомком объекта «Подразделения». Экземпляры потомка с общим предком называются близнецами.
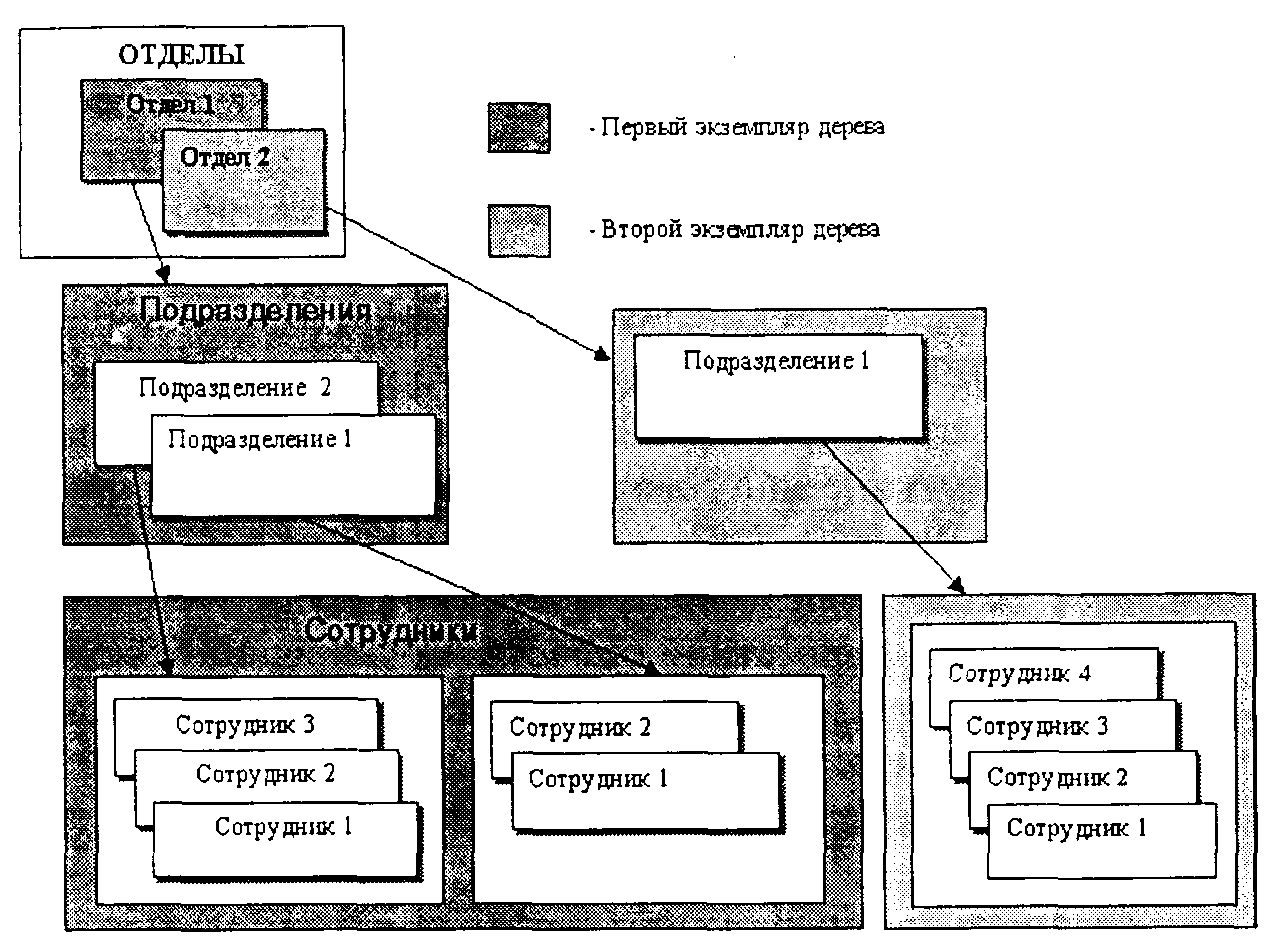
Рис. 2.2. Пример иерархической организации данных
В иерархической модели устанавливается строгий порядок обходадерева (сверху-вниз, слева-направо) и следующиеоперации над данными:
• найти указанное дерево (например, отдел № 3);
• перейти от одного дерева к другому;
• перейти от одной записи к другой (например, от отдела к первому подразделению);
• перейти от одной записи к другой в порядке обхода иерархии;
• удалить текущую запись.
Основное внимание в ограничениях целостностив иерархической модели уделяется целостности ссылок между предками и потомками с учетом основного правила: никакой потомок не может существовать без родителя.
Сетевая модельявляется расширением иерархической и широко применялась в 70-е годы в первых СУБД, использовавшихся крупными корпорациями для создания информационных систем (СУБД IDMS— Integrated Database Management System компании Cullinet Software Inc.,СУБД IDS,отечественные СУБД «СЕТЬ», «БАНК», «СЕТОР»). Одним из идеологов концепции сетевой модели являлся Ч. Бахман. Эталонный вариант сетевой модели данных, разработанный с участием Бахмана, был описан в проекте «Рабочей группы по базам данных» КОДАСИЛ (DBTG CODASYL).
В отличие от иерархической, в сетевой модели объект-потомок может иметь не одного, а вообще говоря, любое количество объектов-предков. Тем самым допускаются любые связи-отношения,в том числе иодноуровневые.В результате сущности и отношения предметной области АИС представляются графом любого (не только древовидного) типа. Пример такой организации данных приведен на рис. 2.3.
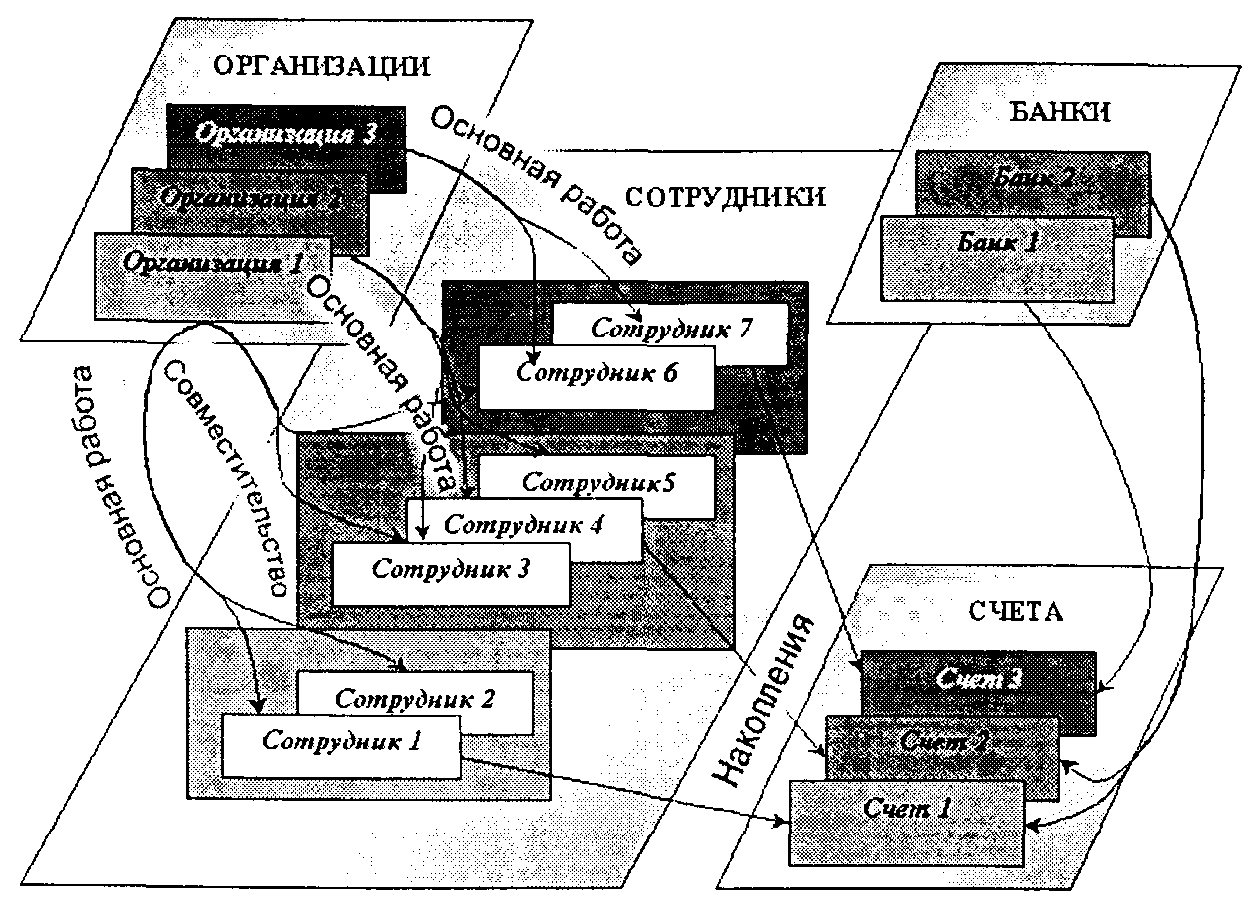
Рис. 2.3. Пример сетевой организации данных
Сетевая СУБД состоит из одного или нескольких типов записей(типов информационных объектов) и наборатипов связеймежду ними. Каждый тип записей представлен в БД набором экземпляров записей данного типа. Аналогично каждый тип связи представлен набором экземпляров связей данного типа между конкретными экземплярами типов записей. В приведенном на рис. 2.3 примере типами записей являются «Организация», «Сотрудник», «Банк», «Счет», а типами связей — «Совместительство», «Основная работа», «Вклады», «Накопления». При этом тип записи «Счет» имеет двух предков — «Сотрудник» и «Банк», экземпляр типа записи «Сотрудник» может иметь два предка (по связям «Основная работа» и «Совместительство»), являющихся различными экземплярами типа записи «Организация».
Для данного типа связи Lмежду типом записи предка Р и типом записи потомка С выполняются следующие условия:
• каждый экземпляр типа Р является предком только в одном экземпляре L,
• каждый экземпляр С является потомком не более чем в одном экземпляре L.
В рамках сетевой модели возможны следующие ситуации:
• тип записи потомка в одном типе связи L1может быть типом записи предка в другом типе связи L2(как в иерархической модели);
• данный тип записи Р может быть типом записи потомка в любом числе типов связи;
• может существовать любое число типов связи с одним и тем же типом записи предка и одним и тем же типом записи потомка;
• если L1и L2—два типа связи с одним и тем же типом записи предка Р и одним и тем же типом записи потомка С, то правила, по которым образуется родство, в разных связях могут различаться;
• типы записей Х и Yмогут быть предком и потомком одной связи и потомком и предком в другой; предок и потомок могут быть одного типа записи (связь типа «петля»).
В сетевой модели устанавливаются следующие операции над данными:
• найти конкретную запись (экземпляр) в наборе однотипных записей;
• перейти от предка к первому потомку по некоторой связи;
• перейти к следующему потомку по некоторой связи;
• создать новую запись;
• уничтожить запись;
• модифицировать запись;
• включить в связь;
• исключить из связи;
• переставить в другую связь.
Реализация связей и сведений по ним в виде отдельных записей в БД обеспечивает одну важную отличительную особенность сетевых СУБД - навигацию по связанным данным. Сетевые СУБД обеспечивают возможность непосредственной «навигации»(перехода) от просмотра реквизитов экземпляра одного типа записи (например, «Организация») к просмотру реквизитов экземпляра связанного типа записей (например, «Сотрудник»). Тем самым пользователю предоставляется возможность многокритериального анализа базы данных без непосредственной формализации своих информационных потребностей через формирование запросов на специальном языке, встроенном в СУБД. Поэтому СУБД с сетевой организацией данных иногда еще называют СУБД с навигацией.
Другой сильной стороной сетевой модели в немногих примерах современной реализации сетевых СУБД является также использование множественных типов данныхдля описания атрибутов информационных объектов (записей), что позволяет создавать информационные структуры, которые хорошо отражают традиционную табличную форму представления структурированных данных. К примеру, при описании типа записи «Сотрудник» в сетевой модели можно ввести реквизит «Имена детей», характер значений которого является множественным.
Сетевая модель позволяет наиболее адекватно отражать инфологические схемы сложных предметных областей. Вместе с тем, несмотря на появление в конце 70-х годов стандарта по сетевой модели данных КОДАСИЛ, не получила широкого распространения ни одна из попыток создания языковых программных средств, которые позволили бы в разных прикладных информационных системах одинаковым образом описывать данные с сетевой организацией. В результате в сетевых СУБД данные оставались жестко связанными как с самой СУБД, так и с прикладными компонентами АИС, что затрудняло специализацию в развитии программных компонент СУБД сетевого типа и объективно затормаживало процесс их развития.