

2.2.2. Реляционная модель организации данных
В реляционной моделиобъекты-сущности инфологической схемы предметной области АИС представляются плоскими таблицами данных. Столбцы таблицы, называемые полями базы данных, соответствуют атрибутам объектов-сущностей инфологической схемы предметной области. Множество атомарных значений атрибута называется доменом.Так доменом для поля «Имя» является множество всех возможных имен. Различные атрибуты могут быть определены на одном и том же домене — например, атрибуты «Год поступления» (в вуз) и «Год окончания» определены на одном и том же домене, являющемся перечнем дат определенного диапазона.
Строки таблицы, представляющие собой различные сочетания значений полей из доменов, называются кортежами (в обиходе просто записями) базы данных и соответствуютэкземплярам объектов-сущностейинфологической схемы предметной области.
Считается, что сильной стороной реляционных баз данных является развитая математическая теория, лежащая в их основе—реляционная алгебра. Само слово «реляционная» происходит от англ. relation —отношение. Но в случае реляционных баз слово «отношение» выражает не взаимосвязь между таблицами-сущностями, а определение самой таблицы как математического отношения доменов.*
* Для любителей математики—отношениемназывается подмножество декартова произведения множеств, роль которых в данном случае играют домены, таким образомтаблицы —это отношение доменов, астроки таблицы (кортежи) —элементы отношения доменов.
Ключевому атрибутуобъекта-сущности, который идентифицирует (определяет, отличает от других) конкретный экземпляр объекта, в таблице соответствует ключевое поле(так называемыйключтаблицы). Примером ключа в таблице «Отделы» может быть поле «Номер отдела» или поле «Наименование отдела». В тех случаях, когда конкретную запись таблицы идентифицирует значение не одного поля, а совокупность значений нескольких полей, тогда все эти поля считаются ключевыми, а ключ таблицы является составным.Примером такой ситуации может служить таблица «Сотрудники», роль составного ключа в которой может играть совокупность полей «Фамилия», «Имя», «Отчество».*
* В той ситуации, когда исключается полное совпадение фамилии, имени и отчества у разных сотрудников.
Ключевое поле для созданной записи (заполненной строки таблицы) впоследствии обновиться (изменить значение) уже не может.
В некоторых таблицах роль ключа могут играть сразу несколько полей или групп полей. Например, в той же таблице «Сотрудники» может быть определен второй ключ «Номер паспорта», который также может идентифицировать конкретную запись (экземпляр) объекта «Сотрудник». В этих случаях один из ключей объявляется первичным.Значения непервичных ключей,которые называются возможными,в отличие от первичных ключей могутобновляться.
Совокупность определенных для таблицы-отношения полей, их свойства (ключи и пр.) составляют схему таблицы-отношения.Две отдельные таблицы-отношения с одинаковой схемой называются односхемными.
Как уже отмечалось, таблица в реляционной модели отражает определенный объект-сущность из мифологической схемы предметной области АИС. Отношения-связиобъектов-сущностей в реляционной модели устанавливаются через введение в таблицах дополнительных полей, которыедублируют ключевые полясвязанной таблицы. К примеру, связь между таблицей «Сотрудники» и таблицей «Отделы» устанавливается через введение копии ключевого поля «Номер отдела» из таблицы «Отделы» в таблицу «Сотрудники» — см. рис. 2.4. Такие поля, дублирующие ключи связанной таблицы, называются внешними ключами.
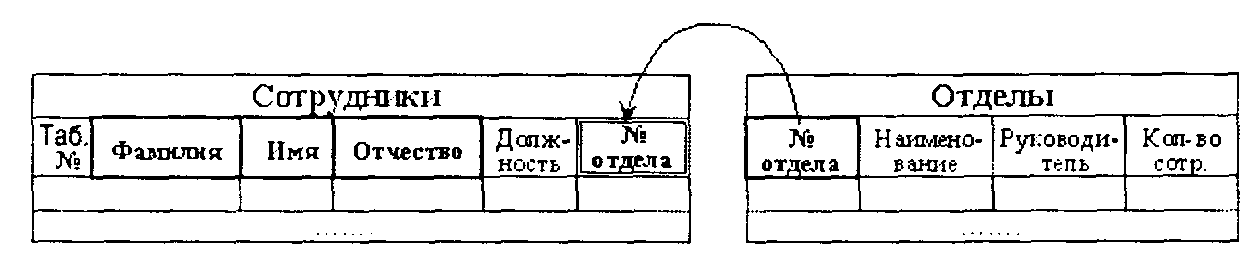
Рис. 2.4. Пример связи в реляционных таблицах
На приведенном рисунке ключевые поля таблиц обведены жирными рамками, а поле с внешним ключом — двойной рамкой.
Так как значения первичного ключа уникальны, т. е. не могут повторяться (в таблице «Отделы» может быть только один кортеж по, к примеру, 710-му отделу), а значения других полей и, в частности, внешнего ключа могут повторяться (в таблице «Сотрудники» может быть несколько строк-кортежей сотрудников по 710-му отделу), то такой механизм автоматически обеспечивает связь типа «Один-ко-многим». Отсюда также можно заключить, что связи между таблицами типа «Один-к-одному» в реляционной модели автоматически обеспечиваются при одинаковых первичных ключах, например между таблицей «Сотрудник» с ключом «Таб_№» и таблицей «Паспорт» с таким же ключом.
Другой вывод, который следует из анализа данного механизма реализации связей, заключается в том, что реляционная модель не может непосредственно отражать связи типа «Многие-ко-многим», что объективно снижает возможности реляционной модели данных при отражении сложных предметных областей.
Таким образом, структурная составляющая реляционной моделиопределяется небольшим набором базовых понятий — таблица-отношение, схема таблицы-отношения, домен, поле-атрибут, кортеж-запись (строка), ключ, первичный ключ, вторичный ключ, внешний ключ (отсылка). Данный набор понятий позволяет описывать естественным образом, близким к понятийному аппарату диаграмм Бахмана, большинство инфологических схем не слишком сложных предметных областей. Это обстоятельство как раз и способствовало интенсивному развитию реляционных СУБД в 80-х-90-х годах.
Ограничения целостности (целостная составляющая) реляционной модели можно разделить на две группы — требованиецелостности сущностейи требованиецелостности ссылок.
Требование целостности сущностейв общем плане заключается в требованииуникальностиэкземпляровобъектов инфологической схемы, отображаемых средствами реляционной модели. Экземплярам объектов инфологической схемы в реляционной модели соответствуют кортежи-записи таблиц-отношений. Поэтому требованиецелостности сущностейзаключается в требовании уникальности каждого кортежа.
Отсюда вытекают следующие ограничения:
• отсутствие кортежей дубликатов (данное требование реализуется не через требование отсутствия совпадения значений одновременно по всем полям, а лишь по полям первичных ключей, что обеспечивает определенную гибкость в описании конкретных ситуаций в предметных областях АИС);
• отсутствие полей с множественным характером значений атрибута (данное ограничение по отношению к весьма типичным ситуациям при описании реальных предметных областей в реляционной модели обеспечивается так называемой нормализациейтаблиц-отношений, т.е. разбиением исходной таблицы на две или более связанные таблицы с единичным характером значений полей-атрибутов).
Требование целостности ссылокзаключается в том, что для любого кортежа-записи с конкретным значением внешнего ключа (отсылки) должен обязательно существовать кортеж связанной таблицы-отношения с соответствующим значением первичного ключа. Простым примером этого очевидного требования является таблица-отношение «Сотрудники» с внешним ключом «№ отдела» и отсылаемая (связанная) таблица «Отделы» с первичным ключом «№ отдела» (см. рис. 2.4). Если существует кортеж-запись «Иванов», работающий в отделе № 710, то в таблице «Отделы» обязательно должен быть кортеж-запись с соответствующим номером отдела (каждый сотрудник должен обязательно в каком-либо отделе хотя бы числиться).
Теоретико-множественный характер реляционных таблиц-отношений требует также отсутствия упорядоченности кортежейиотсутствия упорядоченности полей-атрибутов.Отсутствие упорядоченности записей-кортежей в таблицах-отношениях усложняет поиск нужных кортежей при обработке таблиц. На практике с целью создания условий для быстрого нахождения нужной записи таблицы без постоянного упорядочения (переупорядочения) записей при любых изменениях данных вводят индексирование полей(обычно ключевых). Индексирование полей, или лучше сказать создание индексных массивов, является типовой распространенной операцией практически во всех СУБД, поддерживающих и другие, не реляционные модели данных, и заключается в построении дополнительной упорядоченной информационной структуры для быстрого доступа к записям-кортежам.
Все операциинад данными в реляционной модели (манипуляционная составляющая) можно разделить на две труппы —операции обновлениятаблиц-отношений и операции обработки таблиц-отношений.
К операциям обновленияотносятся:
• операция ВКЛЮЧИТЬ —добавляет новый кортеж (строку-запись) в таблицу-отношение. Требует задания имени таблицы и обязательного значения ключей. Выполняется при условии уникальности значения ключа. Добавить новую строку-запись со значением ключа, которое уже есть в таблице, невозможно;
• операция УДАЛИТЬ — удаляет одну или группу кортежей (строк-записей). Требует задания имени таблицы, имени поля (группы полей) и параметров значений полей, кортежи с которыми должны быть удалены;
• операция ОБНОВИТЬ — изменяет значение не ключевых полей у одного или группы кортежей. Требует задания имени таблицы-отношения, имен полей и их значений для выбора кортежей и имен изменяемых полей.
Особенностью операций обработки в реляционной модели по сравнению с иерархической и сетевой моделью является то, что в качестве единичного элемента обработки выступает не запись (экземпляр объекта), а таблица в целом,т. е. множество кортежей (строк-записей). Поэтому все операции обновления являются операциями над множествами и их результатомявляется также множество, т. е.новая таблица-отношение.Коперациям обновленияотносятся следующие операции:
• операция ОБЪЕДИНЕНИЕ — выполняется над двумя односхемными таблицами-отношениями. Результатом объединения является построенная по той же схеме таблица-отношение, содержащая все кортежи первой таблицы-отношения и все кортежи второй таблицы-отношения. При этом кортежи-дубликаты в итоговой таблице устраняются;
• операция ПЕРЕСЕЧЕНИЕ — выполняется также над двумя односхемными таблицами-отношениями. Результатом является таблица-отношение, построенная по той же схеме и содержащая только те кортежи первой таблицы-отношения, которые входят также в состав кортежей второй таблицы-отношения. Для примера рассмотрим таблицу «Сотрудники» со схемой (полями) «ФИО», «Год рождения», «Национальность» и таблицу «Вкладчики банка «НАДЕЖНЫЙ» с той же схемой. Результатом их пересечения будет новая таблица с той же схемой, содержащая кортежи только тех сотрудников, которые имеют вклады в банке «НАДЕЖНЫЙ», что иллюстрируется примером, приведенным на рис. 2.5;
• операция ВЫЧИТАНИЕ — выполняется также над двумя односхемными таблицами-отношениями. Результатом является таблица-отношение, построенная по той же схеме и содержащая только те кортежи первой таблицы-отношения, которых нет в составе кортежей второй таблицы-отношения. Результатом операции вычитания над таблицами в предыдущем примере будет новая таблица стой же схемой, содержащая кортежи только тех сотрудников, которые не имеют вкладов в банке «НАДЕЖНЫЙ»;

Рис. 2.5. Пример операции ПЕРЕСЕЧЕНИЕ
• операция ПРОИЗВЕДЕНИЕ (ДЕКАРТОВО) — выполняется над таблицами-отношениями с разными схемами. Результатом является таблица-отношение, схема которой включает все поля первой и все поля второй таблицы. Кортежи (строки-записи) результирующей таблицы образуются путем последовательного сцепления каждого кортежа первой таблицы-отношения к каждому кортежу второй таблицы-отношения. Количество кортежей результирующей таблицы соответственно равно произведению количества кортежей первой таблицы на количество кортежей второй таблицы. На рис. 2.6 иллюстрируется пример операции произведения;
• операция ВЫБОРКА (горизонтальное подмножество) — выполняется над одной таблицей-отношением. Результатом является таблица-отношение той же схемы, содержащая подмножество кортежей исходной таблицы-отношения, удовлетворяющих условию выборки;
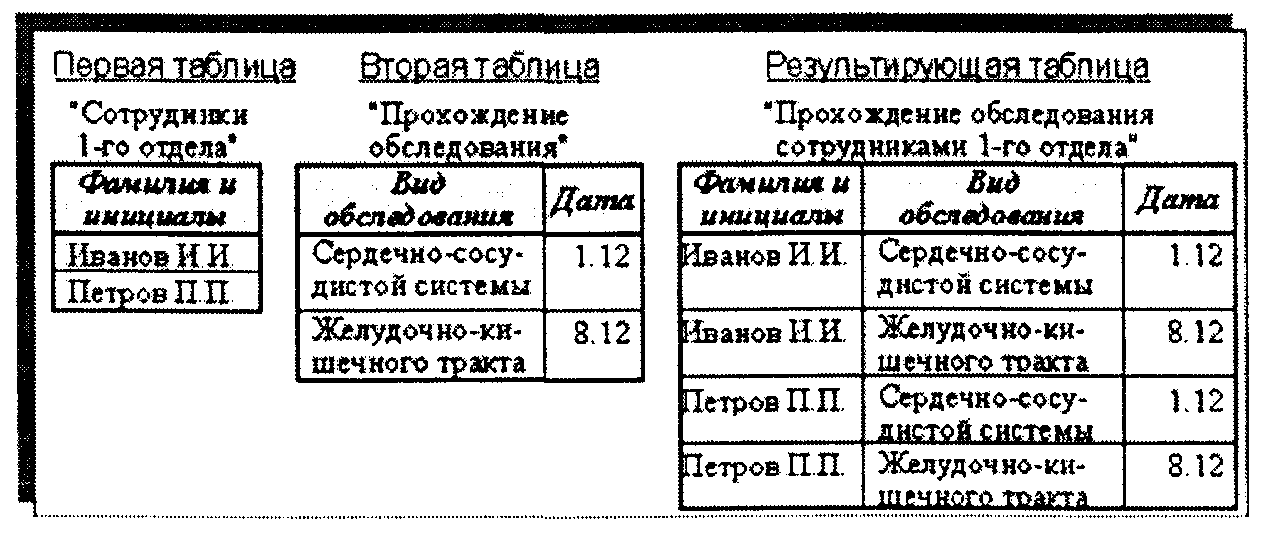
Рис. 2.6. Пример операции произведения
• операция ПРОЕКЦИЯ (ВЕРТИКАЛЬНОЕ ПОДМНОЖЕСТВО) —также выполняется над одной таблицей-отношением. Результатом является новая таблица-отношение, схема которой содержит только некоторое подмножество полей исходной таблицы-отношения. Каждому кортежу исходной таблицы соответствует кортеж итоговой таблицы, образованный соответствующими значениями по полям, вошедшим в итоговую таблицу-отношение. При этом в итоговой таблице кортежи-дубликаты устраняются и поэтому мощность итоговой таблицы (количество кортежей) может быть равна или меньше исходной. На рис. 2.7 приведен пример операции проекции;
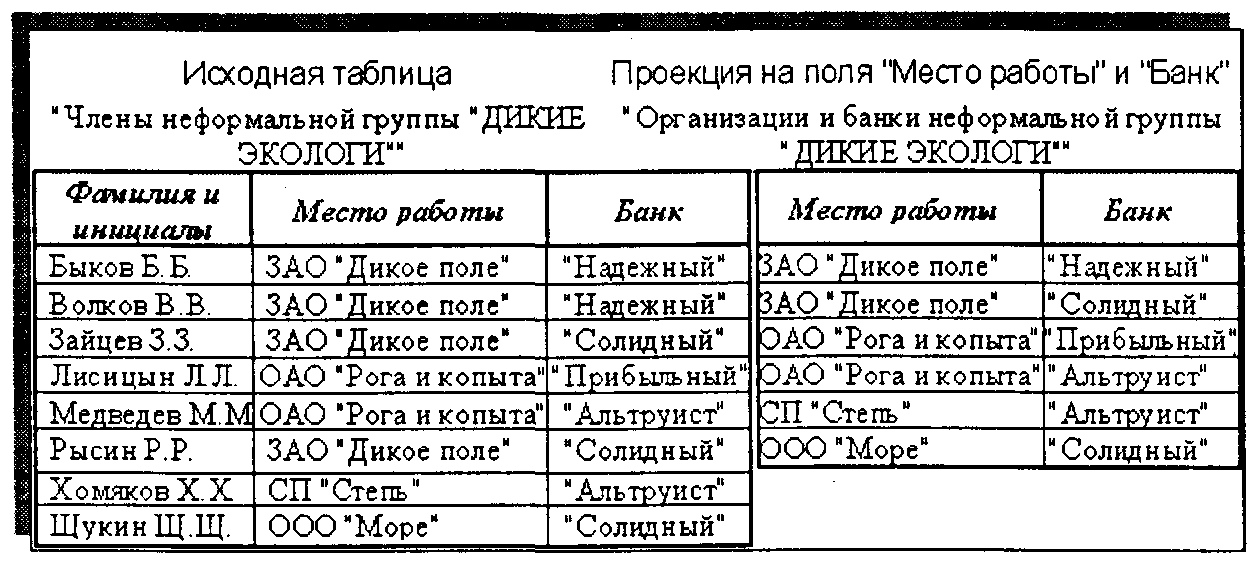
Рис. 2.7. Пример операции проекции
• операция СОЕДИНЕНИЕ — выполняется над таблицами-отношениями с разными схемами. В каждой таблице-отношении выделяется поле, по которому будет осуществляться соединение. При этом оба поля должны быть определены на одном и том же домене. Схема итоговой таблицы-отношения включает все поля первой таблицы и все поля второй таблицы (как в произведении). Кортежи итоговой таблицы-отношения образуются путем сцепления каждого кортежа из первой таблицы с теми кортежами второй таблицы, значения которых по полю сцепления одинаковы. На рис. 2.8 приведен пример операции соединения;
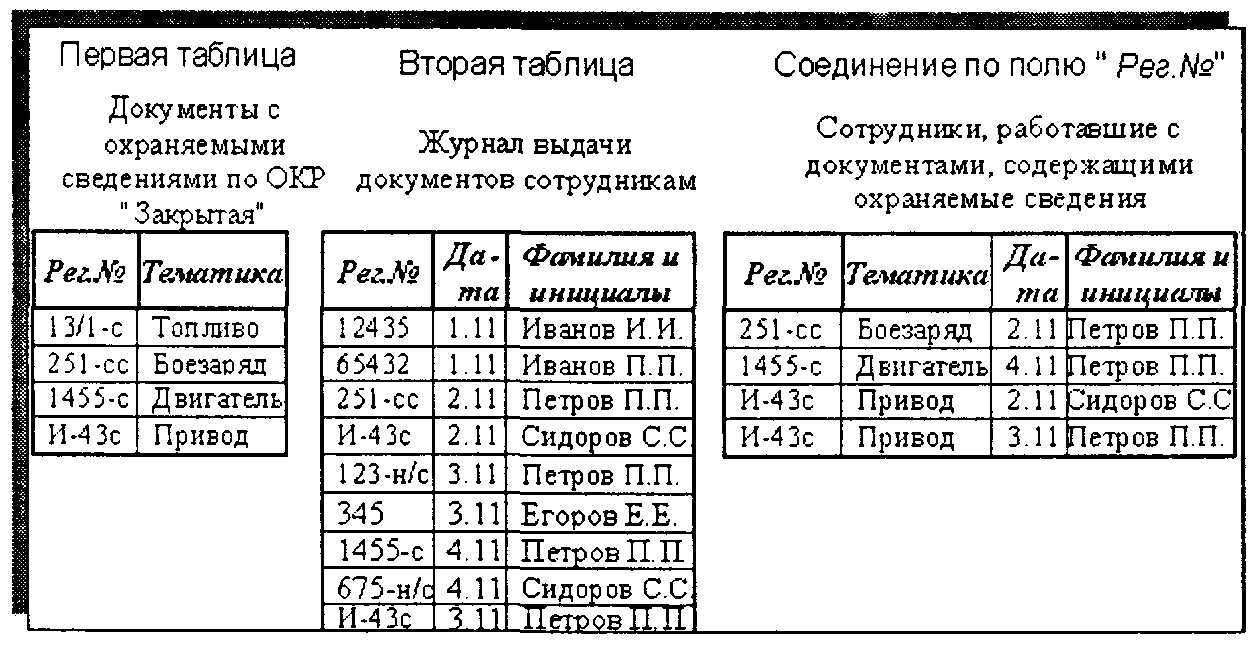
Рис. 2.8. Пример операции соединения
• операция ДЕЛЕНИЕ — выполняется над двумя таблицами-отношениями, первая из которых называется делимым, а вторая делителем. При этом схема таблицы-делителя должна состоять из подмножества полей таблицы делимого. Схема итоговой таблицы-отношения содержит только те поля таблицы-делимого, которых нет во второй таблице-делителе. Кортежи итоговой таблицы-отношения образуются на основе кортежей первой таблицы (делимого) по значениям полей, вошедших в итоговую таблицу при условии того, что если взять произведение (декартово) итоговой таблицы-отношения и второй таблицы-отношения (делителя), то образуются соответствующие кортежи первой таблицы (делимого). На рис. 2.9 приведен пример операции деления.
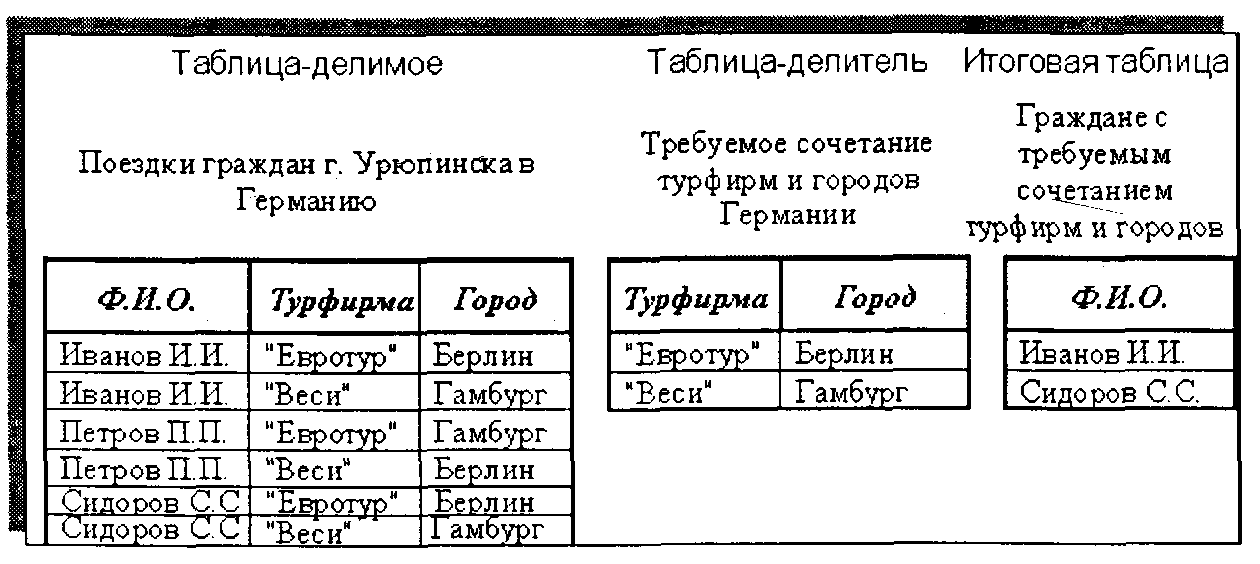
Рис. 2.9. Пример операции деления
В своем исходном виде манипуляционная составляющая реляционной модели не предусматривает операции над полями-атрибутами и схемами таблиц-отношений. Однако на практике применение рассмотренных выше операций манипулирования данными может приводить к временным нарушениям требований ограничения целостностей, которые преодолеваются специальными операциями переименования, удаления, добавления полей-атрибутов.
Реляционная модель организации данных сыграла трудно переоценимую роль в развитии программного обеспечения АИС. Именно реляционные СУБД были тем программным инструментарием, на основе которого происходила массовая информатизация малых и средних предприятий и организаций в 80-х годах. В начале 90-х годов реляционные СУБД стали фактическим стандартом для построения самых разнообразных информационных систем. Вместе с тем проявились и определенные ограничения реляционной модели, которые не позволяют адекватно описывать такие сложные предметные области, как конструирование, производственные технологические процессы и др. Поэтому в 90-х годах были предприняты попытки создания новых усовершенствованных моделей организации данных в виде постреляционных СУБД и объектно-ориентированных СУБД.К сожалению, до сей поры ни одна из попыток создания и описания новых моделей описания данных не стандартизована, и количество коммерческих СУБД, основанных на новых моделях данных, исчисляется единицами.