

5.3. Технологии объектного связывания данных
Унификация взаимодействия прикладных компонентов с ядром информационных систем в виде SQL-серверов, наработанная для клиент-серверных систем, позволила выработать аналогичные решения и для интеграции разрозненных локальных баз данных под управлением настольных СУБД в сложные децентрализованные гетерогенные распределенные системы. Такой подход получил название объектного связывания данных.
С узкой точки зрения, технология объектного связывания данных решает задачу обеспечения доступа из одной локальной базы, открытой одним пользователем,к данным в другой локальной базе* (в другом файле), возможно находящейся на другой вычислительной установке, открытой и эксплуатируемой другим пользователем.
* На практике другой локальной базой может быть и база данных сервера централизованной многопользовательской корпоративной системы.
Решение этой задачи основывается на поддержке современными «настольными» СУБД (MS Access, MS FoxPro, dBaseи др.) технологии «объектов доступа к данным» — DAO.При этом следует отметить, что под объектом понимается интеграция данных и методов их обработки в одно целое (объект), на чем, как известно, основываются объектно-ориентированное программирование и современные объектно-ориентированные операционные среды. Другими словами, СУБД, поддерживающие DAO, получают возможность внедрять и оперировать в локальных базах объектами доступа к данным, физически находящимся в других файлах, возможно на других вычислительных установках и под управлением других СУБД.
Технически технология DAO основана на уже упоминавшемся протоколе ODBC,который принят застандарт доступане толькок даннымна SQL-серверах клиент-серверных систем, но и в качестве стандарта доступа к любым данным под управлением реляционных СУБД. Непосредственно для доступа к данным на основе протокола ODBCиспользуются инициализируемые на тех установках, где находятся данные, специальные программные компоненты, называемыедрайверами ODBC,или инициализируемые ядра тех СУБД, под управлением которых были созданы и эксплуатируются внешние базы данных. Схематично принцип и особенности доступа к внешним базам данных на основе объектного связывания иллюстрируются на рис. 5.6.

Рис. 5.6. Принцип доступа к внешним данным на основе протокола ODBC
Прежде всего, современные настольные СУБД обеспечивают возможность прямого доступа к объектам(таблицам, запросам, формам) внешних баз данных «своих» форматов.Иначе говоря, в открытую в текущем сеансе работы базу данных пользователь имеет возможность вставить специальные ссылки-объекты и оперировать с данными из другой (внешней, т. е. не открываемой специально в данном сеансе) базы данных.Объекты из внешней базы данных, вставленные в текущую базу данных,называются связанными,и, как правило, имеют специальные обозначения для отличия от внутренних объектов. При этом следует подчеркнуть, чтосами данные физическив файл (файлы) текущей базы данных не помещаются, аостаются в файлах «своих» баз дачных.В системный каталог текущей базы данных помещаются все необходимые для доступа сведения о связанных объектах — внутреннее имя и внешнее, т. е. истинное имя объекта во внешней базе данных, полный путь к файлу внешней базы и т. п.
Связанные объектыдля пользователя ничем не отличаются отвнутренних объектов.Пользователь может также открывать связанные во внешних базах таблицы данных, осуществлять поиск, изменение, удаление и добавление данных, строить запросы по таким таблицам и т. д. Связанные объекты можно интегрировать в схему внутренней базы данных, т. е. устанавливатьсвязи между внутренними и связанными таблицами.
Технически оперирование связанными объектами из внешних баз данных «своего» формата мало отличается от оперирования сданными из текущей базы данных. Ядро СУБД при обращении к данным связанного объекта по системному каталогу текущей базы данных находит сведения о месте нахождения и других параметрах соответствующего файла (файлов) внешней базы данных и прозрачно, т. е. невидимо дляпользователя открываетэтотфайл(файлы), а далее обычным порядком организует в оперативной памятибуферизацию страниц внешнего файла данных для непосредственно доступа и манипулирования данными.Следует также заметить, что на основе возможностей многопользовательского режима работы с файлами данных современных операционных систем, с файлом внешней базы данных, если он находится на другой вычислительной установке, можетв тот же момент времени работать и другой пользователь, что и обеспечивает коллективную обработку общих распределенных данных.
Для иллюстрации на рис. 5.7 приведен пример схемы БД, организованной на основе техники объектного связывания данных распределенной системы коллективной обработки данных трех подразделений некоторой организации — службы ДОУ, отдела кадров и бухгалтерии.* На вычислительных установках перечисленных подразделений, объединенных в локальную сеть, создаются и эксплуатируются локальные базы данных, структурные схемы которых отражают задачи и особенности предметных областей сведений, необходимых для информационного обеспечения деятельности соответствующих подразделений. При этом часть данных, распределенных по таким таблицам, как «Сотрудники», «Подразделения», «Штатные категории» и др., являются общепотребными для всех или для группы подразделений. Логично исключить дублирование ввода, редактирования, корректировки и хранения таких общих данных, возложив эти функции на пользователей тех локальных баз данных, где это наиболее естественно и обоснованно сточки зрения функциональных особенностей соответствующих подразделений и сложившихся информационных потоков, а пользователям локальных баз данных других подразделений предоставить доступ к ним. Так, к примеру, таблицы данных по сотрудникам и подразделениям наиболее естественно заполнять данными и хранить в локальной базе кадрового подразделения, обеспечивая доступ к ним пользователей локальных баз службы ДОУ и бухгалтерии. Структурную схему локальных баз этих подразделений в этом случае целесообразно построить на основе объектного связывания данных. На рис. 5.7 связанные, т. е. физически находящиеся в других базах данных, таблицы выделены специальной раскраской и обрамлением. Стрелками на рисунке показаны связи типа «Один-ко-многим» (острие стрелки соответствует стороне «многие»).
* Данный пример является чисто иллюстративным и никаким образом не может претендовать на отражение каких-либо реальных баз данных.

Рис. 5.7. Пример схем локальных баз данных со связанными объектами
На рис. 5.8 приведен еще один пример схемы локальных баз данных, использующих совместные данные по линии информационного обеспечения производства и сбыта продукции. Предметные области сведений по этим трем локальным базам данных очень близки и переплетены, однако, как и в предыдущем примере, с учетом специфики подразделений, ведение и размещение таких общепотребных таблиц как «Продукция», «Типы, номенклатура» целесообразно осуществлять в локальной базе Планово-производственного отдела,таблиц «Комплектующие», «Сырье», «Поставщики» в локальной базеОтдела снабжения,а таблиц «Заказы» и «Клиенты» в локальной базеОтдела сбыта.Опять-таки данные по таблице «Сотрудники» могут быть получены на основе объектного связывания из локальной базыОтдела кадров.
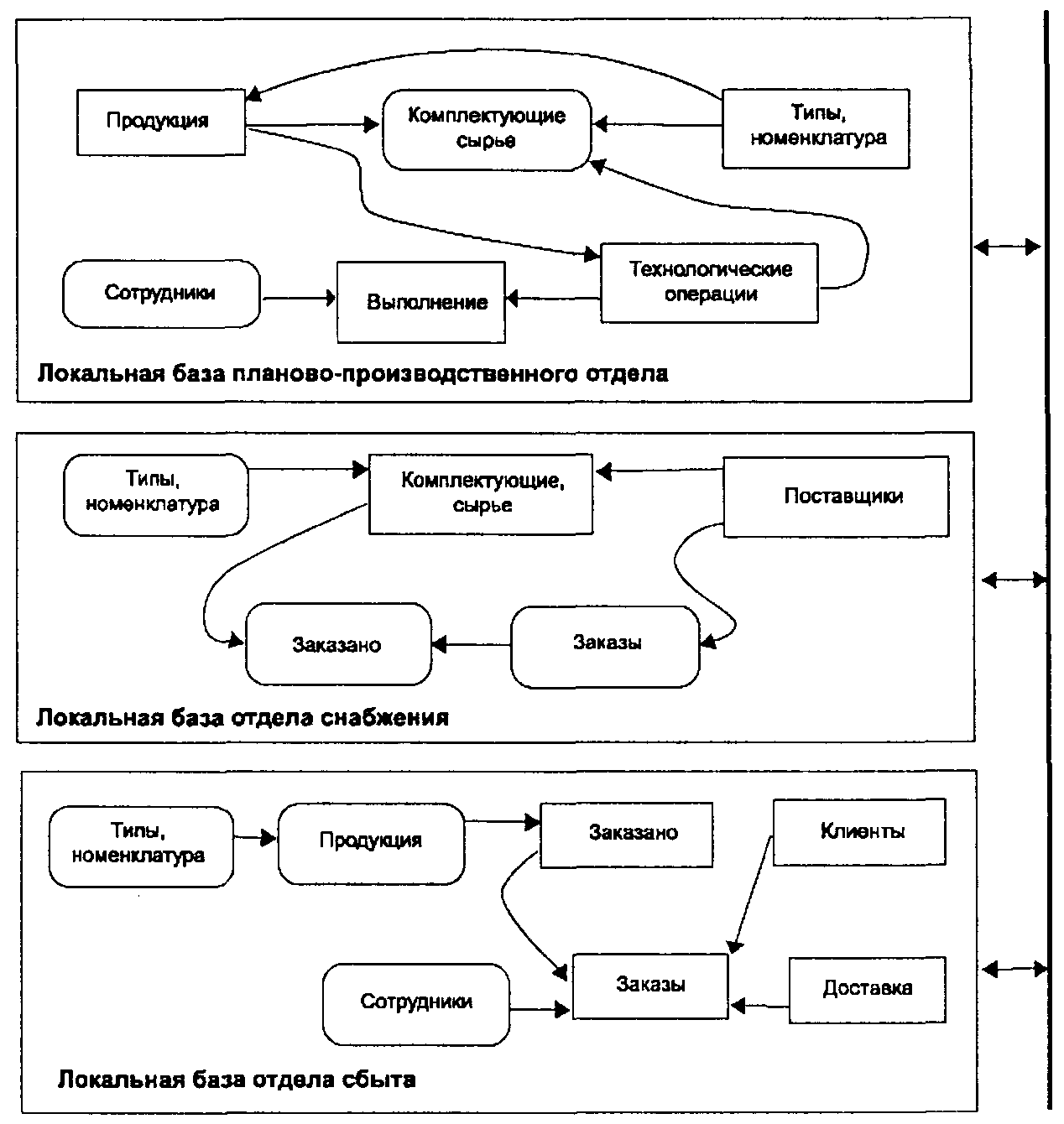
Рис. 5.8. Пример схем локальных баз данных со связанными объектами
Нетрудно заключить, что подобный принцип построения распределенных систем при больших объемах данных в связанных таблицах приведет к существенному увеличению трафика сети,так как по сети постоянно передаются, даже не наборы данных, а страницы файлов баз данных, что может приводить к пиковым перегрузкам сети. Поэтому представленные схемы локальных баз данных со взаимными связанными объектами нуждаются в дальнейшей тщательной проработке с точки зрения интенсивности, направленности потоков данных в сети между локальными базами исходя из информационных технологий, обусловленных производственно-технологическими и организационными процессами.
Не менее существенной проблемой является отсутствие надежных механизмов безопасности данныхи обеспечения ограничений целостности.Так же как и в модели файлового сервера, совместная работа нескольких пользователей с одними и теми же данными обеспечивается только функциями операционной системы по одновременному доступу к файлу нескольких приложений.
Аналогичным образом обеспечивается доступ к данным, находящимся в базах дачных наиболее распространенных форматов других СУБД, таких, например, как базы данных СУБДFoxPro, dBASE,а так же к табличным данным электрон
При этом доступ может обеспечиваться как непосредственно ядром СУБД,так и специальными дополнительными драйверами ISAM (Indexed Sequential Access Method),входящими, как правило, в состав комплекта СУБД. Такой подход реализует интероперабельностьпостроенных подобным образом распределенных гетерогенных систем, т.е. «разномастность» типов СУБД, поддерживающих локальные базы данных. При этом, однако, объектное связывание ограничивается только непосредственно таблицами данных, исключая другие объекты базы данных (запросы, формы, отчеты), реализация и поддержка которых зависят от специфики конкретной СУБД.
Доступ к базам данных других СУБД (см. рис. 5.6) реализуется через технику драйверов ODBC,которыеинсталлируются и выполняются на тех вычислительных установках, где находятся удаленные данные.«Идеология» в данном случае такова. В составе настольной СУБД, поддерживающей локальную базу данных, можно инсталлировать дополнительный программный компонент, называемый драйвером ODBC.*Инсталлируемый драйвер ODBC«регистрируется» в специальном подкаталоге системного каталога операционной системы.** Так образуется рабочая область прямого доступа к источникам данных ODBC.
* В операционной системе Windowsдрайверы ODBCреализуются посредством файлов DDL(библиотеки динамической компоновки).
** В операционной системе Windowsданный подкаталог так и называется —ODBC.
Для непосредственного доступа к источникам данных ODBCядро СУБД по системному каталогу внутренней локальной базы данных определяетместонахождение источника,попротоколу взаимодействия приложений (API)осуществляетвызов (запуск)на вычислительной установке удаленных данных драйвера ODBCи направляет ему по протоколу ODBC SQL-ичструкщтна доступ и обработку данных. При этом режим такого доступа регулируется рядомпараметров(интервал вызова процедур, максимальное время обработки запроса, количество однократно пересылаемых по сети записей из набора данных, формируемых по запросам, время блокировок записей и т. д.). Данные параметры записываются в специальный реестр операционной системы при инсталляции и регистрации соответствующего драйвера ODBC.
При таком подходе каждая локальная СУБД на своей вычислительной установке выполняет роль SQL-сервера, т. е. машины данных, в случае обращения на доступ извне (из других вычислительных установок) к данным из «ее» файлов данных. Так как непосредственную обработку данных в данном случае выполняет «родная» СУБД, знающая все особенности логической и физической структуры «своих» файлов данных, то обеспечивается, как правило, более эффективная обработка, а самое главное, проверяются и выполняются ограничения целостности данных по логике предметной области источников данных.
Определенной проблемой технологий объектного связывания является появление «брешей» в системах защиты данных и разграничения доступа. Вызовы драйверов ODBCдля осуществления процедур доступа к данным помимо пути, имени файлов и требуемых объектов (таблиц), если соответствующие базы защищены, содержат в открытом виде пароли доступа, в результате чего может быть проанализирована и раскрыта система разграничения доступа и защиты данных.