

4.3.4. Особенности обработки данных в субд с сетевой моделью организации данных
Основные принципы и способы обработки данных, рассмотренные для реляционных СУБД, также характерны и для немногих сохранившихся, и продолжающих развиваться СУБД с сетевой моделью организации данных.
В сетевых СУБД подобным же образом, как и в реляционных СУБД, реализуются операции поиска, фильтрации и сортировки данных. Распространенность и популярность языка SQLреляционных СУБД привели к тому, чтоподобные языки для реализации запросов к базам данных были разработаны или просто«внедрены» в сетевые СУБД.При этом так же, как и реляционные СУБД, современные сетевые СУБД предоставляют пользователю и специальные диалогово-наглядные средства формирования запросов. Также в сетевые СУБД встраиваются специальные макроязыки для формирования сложных последовательностей взаимосвязанных запросов (аналог процедур), хранящихся вместе с базой данных.
Вместе с тем обработка данных в СУБД с сетевой моделью организации данных, как уже отмечалось, характеризуется уже упоминавшейся принципиальной особенностью, которой нет в реляционных СУБД. Это непосредственная «навигация»по связанным данным (по связанным записям) в разных информационных объектах (аналоги таблиц в реляционных СУБД). Как уже отмечалось, возможность непосредственной навигации обусловлена тем, что в сетевых СУБД ссылки-связи между записями различного типа (различных таблиц) задаются не через внешние ключи, а через специальные указатели на физические адреса расположения связанных записей.
Просматривая, к примеру, в сетевой СУБД записи объекта «Лицо» и выбрав запись «Иванов» (т. е. поместив табличный курсор на соответствующую запись), можно через активизацию поля «Работает» вызвать на экран поля связанной записи в объекте «Организация» и просмотреть соответствующие данные, а далее, при необходимости, через активизацию поля «Адрес» в записи по объекту «Организация» вызвать и просмотреть данные по дислокации места работы сотрудника «Иванов» и т. д. (см. рис. 4.27).
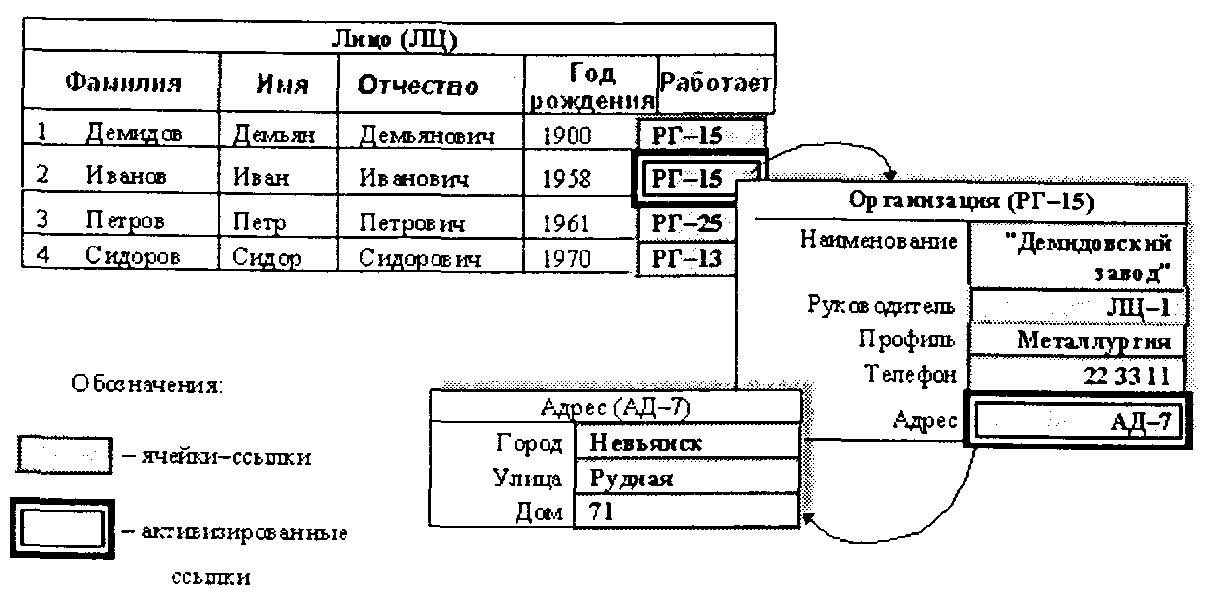
Рис. 4.27. Навигация по связанным записям в сетевых СУБД
В реляционных СУБД для реализации такого просмотра понадобилось бы создать и выполнить запрос на выборку данных из трех таблиц на основе внутреннего (INNER JOIN)соединения при условии отбора соответствующей фамилии сотрудника:
SELECT Лицо.*, Организация.*, Адрес.*
FROM(ЛицоINNERJOIN(АдресINNERJOINОрганизацияONАдрес.№№=Организация.Адрес)
ON(((Лицо.Работает = Организация.Наименование)
WHERE(((Лицo.Фaмилия)=»Ивaнoв»));
При этом, если пользователю необходимо посмотреть те же данные, но для другого сотрудника, то необходимо изменить условия отбора по фамилии и заново выполнить запрос. В сетевых же СУБД для этого достаточно лишь «вернуться» в исходный объект «Лицо», переместить курсор на другую запись и повторить навигацию.
Данный пример показывает, что навигационные возможности сетевых СУБДпозволяют пользователю реализовывать своиинформационные потребности(«беседовать» с базой данных) болееестественным интерактивным способом,шаг за шагом уточняя свои потребности, и тем самым более глубоко и наглядно анализировать (изучать) данные.
Навигационный подход к анализу и просмотру данных, естественный уже для ранних сетевых СУБД, впоследствии (в конце 80-х годов) был реализован в технике гипертекста, и в созданной на его основе новой разновидности документальных информационных систем — гипертекстовых информационно-поисковых систем.
Вместе с тем навигация по связанным данным порождает и ряд своих специфических проблем,таких как «потеря ориентации» и трудности с визуализацией цепочек «пройденных» информационных объектов(записей). Схемы баз данных, отражающих сложные предметные области, могут насчитывать десятки различных информационных объектов и еще большее количество связей между ними. В результате такие базы данных представляют сложное многомерное информационное пространство из множества разнотипных наборов записей, пронизанных и опутанных порой несметным количеством связей. «Путешествуя» в таком клубке, легко «сбиться с пути», потерять общую картину состояния данных.* При этом следует иметь в виду, что особенности человеческого мышления таковы, что человек способен удержать в представлении с полным отслеживанием всех связей и нюансов не более 3-4 сложных объектов.**
* То есть оказаться в ситуации, которая образно выражается известной поговоркой «За деревьями леса не видно».
** Этим, кстати, еще из древности определяется троичная система организации структуры воинских подразделений для эффективного управления ситуацией на поле боя.
Иногда объектом анализа являются не конкретные реквизиты связанных записей, а сама схема связанных записей,т. е. визуализированная цепочка имен связанных от исходного информационного объекта записей. Использованиемножественного типа значений в поляхинформационных объектов сетевых СУБД позволяет реализовывать все типы связей, что приводит к «пучковости» исходящих или входящих связей типа «один-ко-многим», «многие-ко-многим». Визуализация таких цепочек на двумерном экране компьютера может представлять существенные графические сложности.
На рис. 4.28 для примера приведен вариант изображения цепочки связанных записей с корневой записью «Иванов» объекта «Лицо». Такая визуализация позволяет быстро составить общее представление о полученном образовании, трудовой деятельности и проживании данного лица. При этом длина цепочки ограничена тремя последовательно связанными записями, но, как видно из рисунка, и в этом, в общем-то простом для многих жизненных ситуаций случае, достаточно сложно отобразить общую схему связей, не «запутывая» ее восприятие.
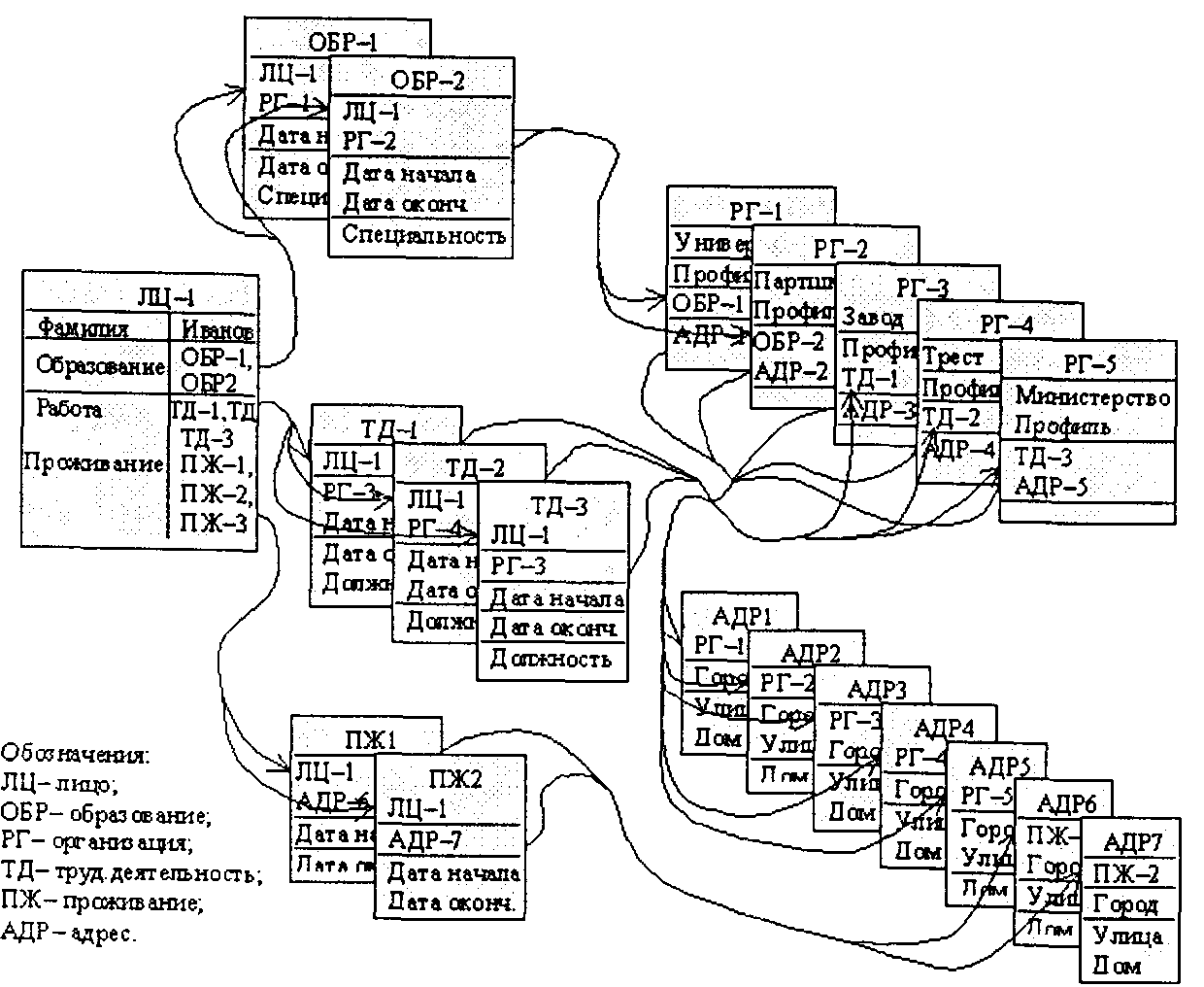
Рис. 4.28. Пример визуализации цепочки связанных записей
Навигация по связанным записям в реляционных СУБД открывает новые возможности анализа данных на основе иных, нежели реляционные, семантических принципах. В частности, становится возможным реализация процедур поиска и построения смысловых окрестностей какой-либо записи по ее связям в базе данных, применение различных процедур информационного анализа на основе алгоритмов поиска на графах и т. п.
Одним из направлений развития современной теории и техники СУБД является линия объектно-ориентированных СУБД, которые на витке наработанных в конце 70-х и в 80-х годах решений по реляционным СУБД, обеспечивают новые возможности по обработке данных на основе методов навигации и визуализации, впервые представленных в сетевых СУБД.