

3.2.2. Проектирование схем реляционных баз данных
В реляционных СУБД при проектировании схемы реляционной базыданных можно выделить следующую последовательностьпроцедур:
а) определение перечня таблиц и их связей;
б)определение перечня полей, типов полей, ключевых полей каждой таблицы (разработка схем таблиц-отношений), установление связей между таблицами через внешние ключи;
в)определение и установление индексов (индексирования) для полей в таблицах;
г)разработка списков (словарей) для полей с перечислительным характером значений данных;
д)установление ограничений целостности по полям таблиц и связям;
е)нормализация таблиц, доработка перечня таблиц и их связей.
Технологически процесс проектирования разделяют на процесс предварительного проектирования таблиц и связенмежду ними:а), б), в), г)ид)и последующуюнормализацию таблиц е).
3.2.2.1. Проектирование и создание таблиц
В качестве первоначальной основы при определении перечня таблиц банка данных и связей между ними используется перечень выделенных объектов-сущностей и отношении концептуальной схемыбанка данных. Иначе говоря,для каждого объекта-сущностив реляционных СУБД осуществляетсяпроектирование соответствующей таблицы.
Поля таблицопределяются на основе первоначально отработанныхатрибутовинформационных объектов концептуальной схемы банка данных. При этом дополнительно к основным базисным характеристикам (домен, поле-атрибут, кортеж, отношение, ключ, внешний ключ) в СУБД используетсятип поля.По своему смыслу тип поля совпадает с понятием типа данных в языках программирования. Традиционные СУБД поддерживают лишь ограниченный набор простых типов полей — числовые, символьные, темпоральные (время, дата), булевы (логические). Современные СУБД оперируют также и со специализированными типами полей (денежные величины), а также со сложными типами полей, заимствованными из языков программирования высокого уровня.
Домены полей таблиц в реляционных СУБД определяют некоторый базисный тип данных для поля, но вместе с тем не являются тождественным понятием типу поля (данных). В некотором смысле домен можно трактовать как некоторое подмножество базисного типа данных с определенной смысловой нагрузкой, — например, множество всех имен из множества всевозможных значений символьного типа данных.
Определение и установление ключевых полейтаблиц в реляционных СУБД является следствием основополагающего требования по ограничениям целостности таблиц-отношений — требования уникальности каждого кортежа-строки. Иначе говоря, одно из полей таблицы, или определенная совокупность полей, в обязательном порядке должно быть определено как ключ. Определение ключевого поля осуществляется на основе смыслового эвристического анализа тематики таблицы при соблюдении принципаминимальной достаточности, т.е. количество полей, образующих ключ таблицы должно быть минимальным.
Правильность определения ключа таблицы проверяется эмпирически по возможным ситуациям совпадения у различных кортежей значений ключа. Во многих случаях выбор ключа является нетривиальной задачей. Какое поле, к примеру, выбрать ключевым для таблицы «Сотрудники»? Напрашивается составной ключ из полей «Фамилия», «Имя», «Отчество», однако в конкретных жизненных ситуациях имеется вероятность их совпадения. Можно добавить в состав ключа еще поле «Год рождения», но и при этом все равно сохранится, хотя и несколько снизится, вероятность совпадения. Альтернативным вариантом ключа может быть «№ паспорта», если ситуации с наличием у одного лица нескольких паспортов полностью исключаются. Если в банке данных ограничиться только сотрудниками данной организации, то отработанным вариантом ключа может быть табельный номер сотрудника — «Таб.№».* На практике распространенным приемом при проектировании таблиц является искусственное введение в качестве ключа параметра, являющегося аналогом табельного номера — внутреннего учетного номера экземпляра (записи) соответствующего объекта.
* Табельный номер кик раз и является примером уникального параметра для каждого сотрудника в платежных ведомостях (таблицах) для преодоления ситуации с совпадением фамилии, имей и т. д. сотрудников.
В некоторых СУБД для создания полей с уникальными идентификационными номерами кортежей-записей введен дополнительный тип поля, называемый «Счетчиком» или полем типа «AUTOINC».В отличие от обычных числовых (или порядкового типа) полей, значения счетчика генерируются СУБД автоматически при образовании новой записи н только в возрастающем порядке, считая все ранее созданные, в том числе и удаленные записи.
Как уже отмечалось, реляционная модель организации данных по признаку множественности обеспечивает лишь два типа связей-отношениймежду таблицами, отражающими объекты-сущности предметной области, —«Один-ко-многим»и«Один-к-одному».
Связь типа «Один-ко-многим»реализует, вероятно, наиболее распространенный тип отношений между таблицами, когда одной записи в таблице на стороне «один» может соответствовать несколько записей в таблице па стороне «многие». Создание связейпроисходит в два этапа.На первом этапев схеме таблицы, находящейся по создаваемой связи на стороне «многие», определяется поле с теми же параметрами (и, как правило, с тем же именем), что и ключевое поле таблицы на стороне «один», т. е. создается полевнешнего ключа. На втором этапе с помощью специальных средств СУБД собственно и определяется связь между таблицами путем установления (через специальные внутренние системные таблицыфакта соответствия ключевого поля таблицы на стороне «один» полю внешнего ключа в таблице на стороне «многие».
В связях типа «Один-к-одному»каждой связанной записи одной таблицы соответствует в точности одна связанная запись в другой таблице. Как уже отмечалось, данный тип связи образуется путем связывания таблиц по одноименным и однотипным ключевым полям, т. е. когда связываемые таблицы имеют одинаковые ключевые поля. Эта ситуация по сути соответствует разбиению одной большой по количеству столбцов таблицы на две таблицы. Необходимость такого разбиения может быть обусловлена соображениями разграничения доступа к данным по определенным полям, либо целесообразностью выделения некоторого подмножества записей в исходной таблице. Так, например, из исходной таблицы «Студенты» можно выделить все записи по студентам, которые живут в общежитии, и образовать две таблицы, связанные отношением «Один-к-одному». Пример такой связи приведен на рис. 3.2.
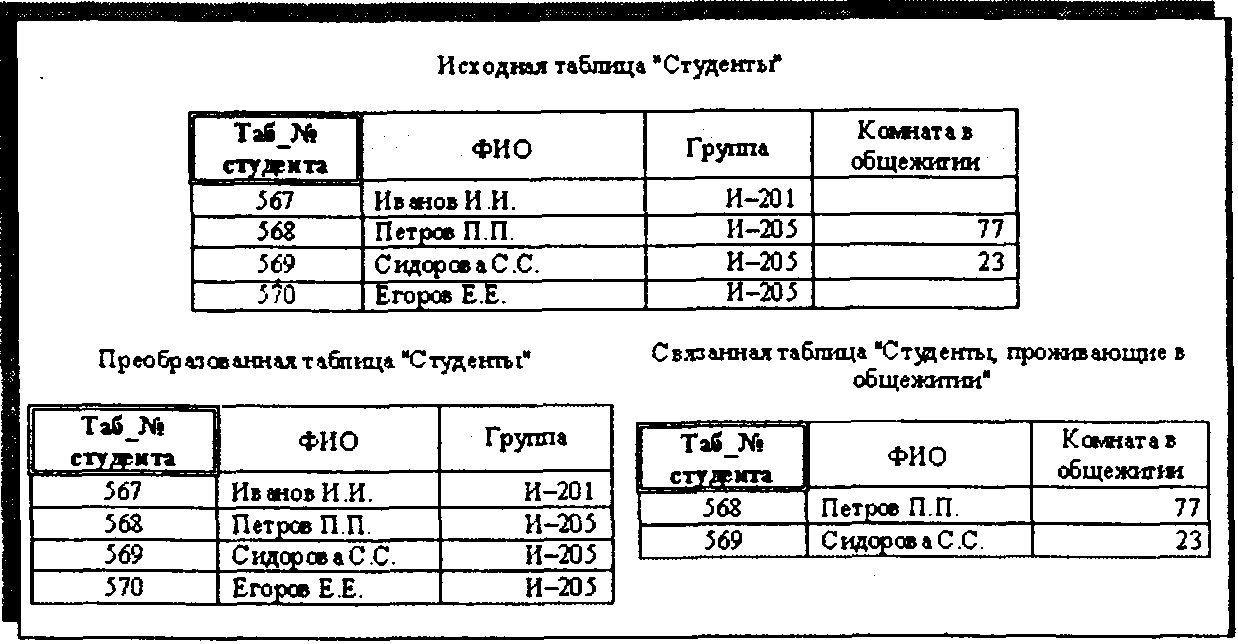
Рис. 3.2. Пример реализации связи «Один-к-одному» в реляционных СУБД
Связи типа «Многие-ко-многим»в реляционных СУБД в большинстве случаев реализуются через создание двух связей«Один-ко-многим»,которые связывают исходные таблицы с третьей общей (связной) таблицей. Ключ связной таблицы состоит, по крайней мере, из двух полей, которые являются полями внешнего ключа для связываемых отношением «Многие-ко-многим» исходных таблиц. Пример реализации связи типа «Многие-ко-многим», выражающей отношение «Согласование» между таблицами «Документы» и «Сотрудники», приведен на рис. 3.3.
Еще одним важным параметром при проектировании таблиц является определение необходимости индексированиятех или иныхполейтаблиц. Определение и установление индексов полей таблиц базы данных является, как уже отмечалось, важным средством создания условий эффективной обработки данных. Индексирование полей (создание индексных массивов) существенно повышает скорость поиска и доступа к записям базы данных. Однако при этом соответственно замедляется ввод и добавление данных из-за необходимости переупорядочения индексных массивов при любом обновлении, удалении или добавлении записей. Поэтому при проектировании таблиц следует тщательно проанализировать, насколько часто при последующей эксплуатации банка данных потребуется поиск или выборка строк-записей таблицы по значениям тех или иных полей, исходя из функций и задач АИС. На основе такого анализа и определяются те поля таблицы, для которых необходимо создать индексы. К примеру, в таблице «Сотрудники» базы данных по документообороту поле «ФИО» целесообразно определить индексируемым, так как, очевидно, довольно часто будет требоваться доступ к записям таблицы именно по значению этого поля. А вот поле «№ кабинета» вряд ли целесообразно индексировать, так как исходя из задач и функций АИС по документообороту, можно прогнозировать, что задачи отбора, группирования и прочей обработки записей сточки зрения размещения сотрудников по кабинетам будут достаточно редкими.
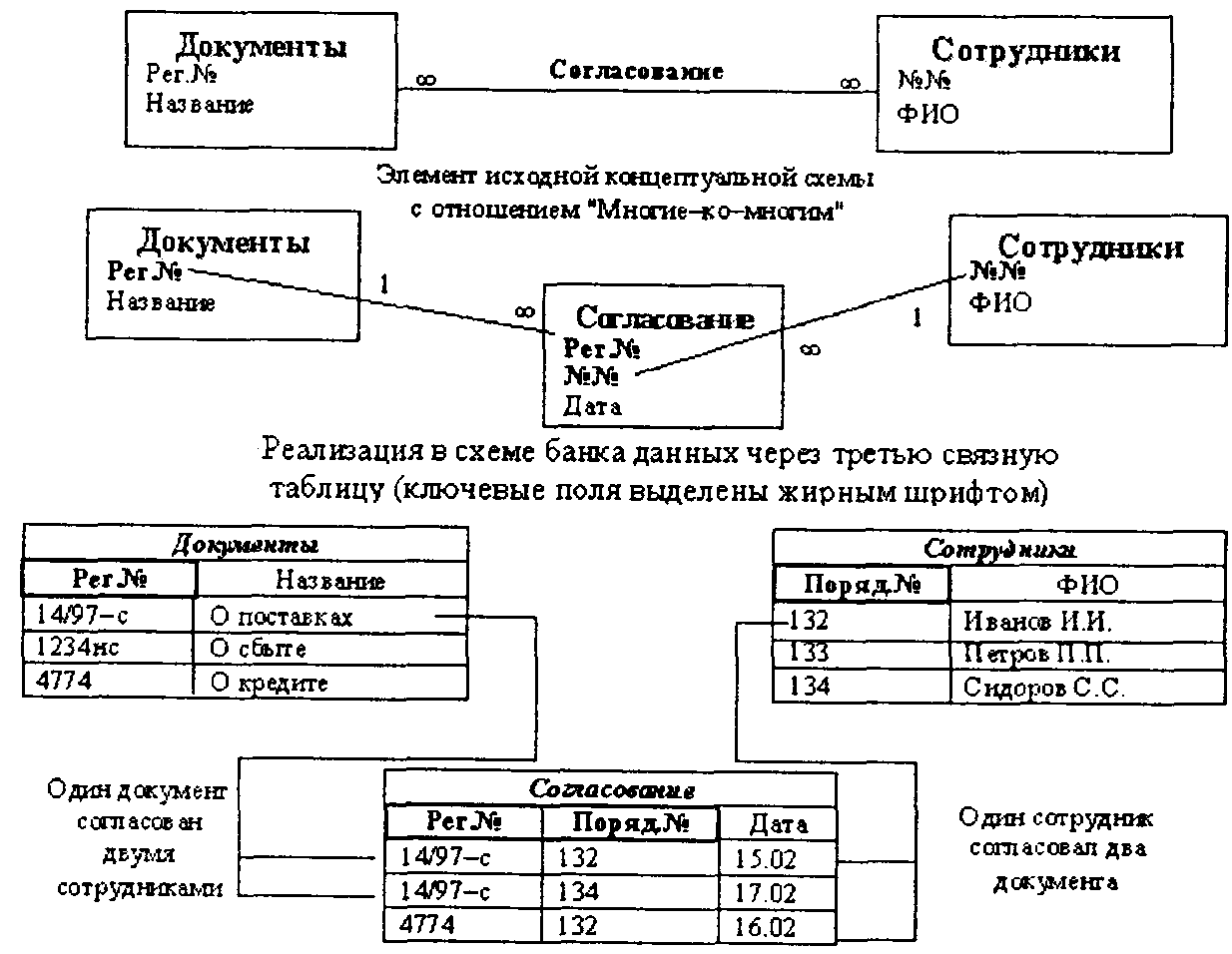
Рис. 3.3. Реализация связей «Многие-ко-многим» в реляционных СУБД
Анализ практики использования индексов в базах данных позволяет сделать вывод, что если в одной таблице установлено более 10 индексов, то либо недостаточно продумана структура базы данных (таблицы), либо не совсем обоснованно определены вопросы обработки данных исходя из задач АИС.
Ключевые поля в большинстве случаев являются индексируемыми автоматически, т. к. поиск и доступ к записям в базе данных производится прежде всего по значениям ключевых полей.
В большинстве СУБД вопросы внутреннего устройства индексных массивов остаются скрытыми и недоступными как для конечных пользователей, так и для проектировщиков. Допускается только лишь качественное определение режима индексирования — без повторов значений индексируемых полей* и с возможностью таких повторов, что, очевидно, определяет разные типы индексных массивов — Б-деревья или инвертированные списки.**
* Так называемый уникальный индекс. Автоматически устанавливается для ключевых полей.
** Как правило, данные вопросы в документации по СУБД не отражаются.
При определении параметров полей таблиц важное значение имеет также выделение полей с перечислительным (словарным, списковым) характером значений.Значения таких полей определяются из некоторого унифицированного списка-словаря.К примеру, поле «Образование» является не просто текстовым, а по сути текстово-списочным, так как набор его всевозможных значений составляет унифицированный список—«Начальное», «Среднее», «Среднеспециальное», «Среднетехническое», «Высшее». Некоторые СУБД обеспечивают возможность при проектировании таблиц построения и привязки к соответствующим полям таких списков-словарей.
Установление списков значений или, иначе говоря, словарей позволяет упростить в дальнейшем ввод данных в записях по таким полям путем выбора соответствующего значения из словаря и, кроме того, унифицировать ввод одинаковых значений в различных записях. К примеру, при ручном наборе значения «Среднее» помимо различий из-за возможных орфографических ошибок, могут быть также и регистровые различия («Среднее», «среднее», «СРЕДНЕЕ»), что в дальнейшем приведет к ошибкам поиска, фильтрации и выборки записей.
Списки (словари)значений могут бытьфиксированными, не изменяемыми в процессе эксплуатации банка данных, илидинамическими.
Фиксированные списки «привязываются» к соответствующим полям через специальные механизмы конкретной СУБД и размещаются в системных таблицах (каталоге) базы данных, доступа к которым пользователи-абоненты системы не имеют.
Динамические словари в большинстве случаев реализуются через создание дополнительных одностолбцовых таблиц, строки которых являются источником списка значений для полей других таблиц. Привязка подобных словарных таблиц в качестве источника значений для полей других таблиц осуществляется также через специальные механизмы конкретной СУБД. Такие таблицы в дальнейшем доступны пользователям банка данных. Соответственно обновление, добавление или удаление записей в таблицах-словарях позволяет изменять словарный базис для полей соответствующих таблиц. В некоторых СУБД дополнительно может также устанавливаться режим ограничения значенийсловарно-списочных полей только установленнымспискомзначений. Установление такого режима целесообразно в тех случаях, когда нужно исключить, в принципе, даже случайный (ошибочный) выход значений поля за пределы списка. Так, например, в случае поля «Оценка» значения могут быть только из списка «Неудовлетворительно», «Удовлетворительно», «Хорошо», «Отлично».
Одним из важных в практическом плане этапов проектирования таблиц является установление ограничений целостности по полям и связям.Как уже указывалось, в исходном виде в реляционной модели данных основным ограничением по значению полей является требование уникальности табличных строк-кортежей, что проявляется в требовании уникальности значений ключевых полей. Дополнительно в реляционных СУБД могут устанавливаться требования уникальности значений и по другим (не ключевым) полям через создание для них индексов в режиме без повторов (UNIQUE),а также установления режима обязательного заполнения в строках-кортежах определенных полей (режим NOT NULL).
Вместе с тем современные СУБД могут предоставлять и более развитые возможности установления ограничений целостности данных. Можно определять допустимые диапазоны значений полей (например, значение поля «Оклад» не может быть меньше величины минимального размера оплаты труда), а также относительные соотношения значений по определенным полям таблицы (например, значение поля «Количество» в таблице «Товары» не может быть меньшим значения поля «Мин_за-пас», значение поля «Дата_исполнения» в таблице «Заказы» не может быть позднее поля «Дата_размещения» плюс определенное количество дней, скажем 7 дней, исходя из того требования, что любой заказ клиента должен быть исполнен в течение максимум 7 дней). Такие ограничения целостности данных отражают ту часть правил и особенностей предметной области АИС,которая не формализуется в рамках реляционной модели данных.*
* Ввиду данного обстоятельства в некоторых англоязычных источниках такие ограничения целостности называют «правилами бизнеса».
Другая часть ограничений целостности данных касается уже упоминавшегося требования целостности ссылок.
Поддержание очевидного требования целостности ссылок встречает определенные трудности на этапе эксплуатации банка данных. Такой типичной ситуацией является, к примеру, удаление записи по отделу № 710 в таблице «Отделы». Если оставить без соответствующего изменения все связанные кортежи в таблице «Сотрудники» (кортежи со значением «710» внешнего ключа «№ отдела»), то как раз и произойдет нарушение целостности ссылок.
На практике в реляционных СУБД существует три подходареализации требования целостности по ссылкам. Впервом подходезапрещается удалять кортеж-запись какой-либо таблицы, если на него существуют ссылки из связанных таблиц. Иначе говоря, запись по отделу № 710 можно удалить лишь в том случае, если перед этим удалены (или переадресованы по ссылкам на другие записи) все сотрудники со значением «710» внешнего ключа «№ отдела». Вовтором подходе при удалении записиотдела № 710 значения внешних ключей всех связанных кортежей таблицы «Сотрудники» автоматически становятсянеопределенными.* Притретьем подходеосуществляется каскадное удалениевсех кортежей, связанных с удаляемым кортежем, т. е. при удалении записи по отделу № 710 автоматически удаляются записи из таблицы «Сотрудники» с соответствующим значением внешнего ключа «№ отдела». Выбор того или иного режима целостности ссылок определяется на основе эвристического анализа правил и возможных ситуаций в предметной области АИС.
* Соответственно в этом случае СУБД различает «пустые» (NULL)и «неопределенные» значения полей.
В заключение отметим, что разделение процесса проектирования таблиц на этапы а, б, в, г и д является условным, а сам процесс предварительного проектирования (создания) таблиц, как будет показано в параграфе 4.1, реализуется специальными инструкциями языка SQL.