

6.3.3. Методы количественной оценки релевантности документов
Количественные показатели релевантности — процент соответствия содержимого документа запросу, ранжирование (самый релевантный документ, менее релевантный, еще менее релевантный) и т. п., позволяют существенно увеличить конечную эффективность использования документальной системы, предоставляя пользователю возможность после отбора документов сразу сосредоточиваться на наиболее важных из них.
Определение количественных показателей релевантности документов в полнотекстовых ИПС основывается на тех или иных подходах по вычислению мер близости двоичных векторов документов и запросов.
Документ Dkпредставляется в системе двоичным вектором:
![]()
где dk,i =1, если словоформа под номеромiприсутствует вk-м документе, и 0, если отсутствует.
Аналогичным образом представляются поисковые образы запроса Zпользователя:
![]()
где zk = 1, если словоформа под номеромkприсутствует в запросе, и zk = 0, если отсутствует.
Критерии релевантностиподразделяются помоделям представленияисопоставления документовизапросов, к которымотносятся:
• булева модель;
• модель нечетких множеств;
• пространственно-векторная модель;
• вероятностно-статистическая модель.
В качестве показателя (меры) релевантности документов используется так называемое значение статуса выборки (retrieval status value— RSV). В булевой моделикритерием релевантности являетсяполное совпадение векторов ПОД и ПОЗ. Соответственно RSV вбулевой модели определяется как логическая сумма операций попарного логического произведения соответствующих элементов векторов ПОД и ПОЗ:
![]()
где k = 1,...,N, N —количество документов в базе, L —количество словоформ в словаре, &—логическая операция «И».
Значением RSVв булевой модели может быть единица (релевантный документ) или ноль (нерелевантный документ). По сути, булева модель не дает количественной меры релевантности и ничем не отличается от простого поиска по индексу системы с логической операцией «И» словоформ-дескрипторов.
В системах на основе модели нечетких множествзначения компонент векторов ПОД и ПОЗ могут принимать не только два альтернативных значения —1 и 0 (термин принадлежит документу или не принадлежит), но и такое значение, как «неполная, частичная принадлежность». Соответственно в модели нечетких множеств переопределены и логические операции, чтобы учитывать возможность неполной принадлежности подобных логических элементов анализируемым множествам (поисковым образам запросов). Вычисление значений статуса выборкиRSVпроизводится аналогичным булевой модели образом с учетом переопределения операции & («И»).
Несмотря на некоторое расширение выразительных возможностей представления и сопоставления документов и запросов, модель нечетких множеств, как и булева модель, не дает по-настоящему количественной меры релевантности, хотя достоинством обеих моделей является их простота и невысокие вычислительные затраты на реализацию.
В системах на основе пространственно-векторных моделейпоисковое пространство представлено многомерным пространством, каждое измерение которого соответствует словоформе (термину) из словаря системы. Например, если в словаре всего три словоформы, то поисковое пространство является трехмерным, и т. д. В исходном варианте пространство имеет евклидову метрику, т. е. представляется ортогональным базисом нормированных векторов, отражающих соответствующие словоформы словаря системы. Поисковый образ документа и запроса в поисковом пространстве представляется многомерным вектором единичной длины, координаты которого отражают наличие или отсутствие в документе соответствующих словоформ. В случае трехмерной размерности пространственно-векторная модель иллюстрируется на рис. 6.10.
Показатель релевантности(по аналогии с булевой моделью будем обозначать егоRSV)для пространственно-векторной модели в простейшем случае определяется скалярным произведением векторов ПОД и ПОЗ:
![]()
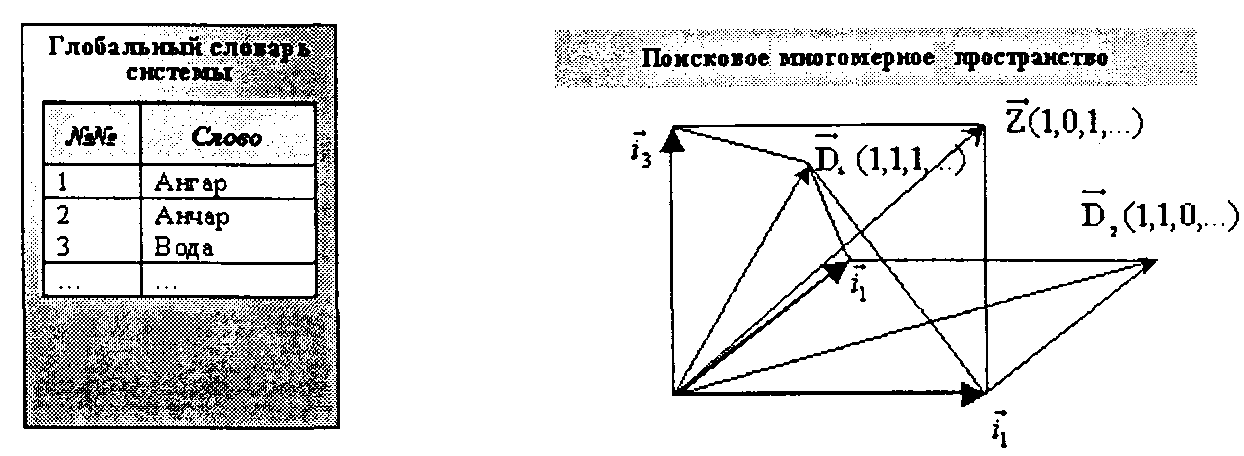
Рис. 6.10. Иллюстрация пространственно-векторной модели представления и сопоставления документов и запросов
Таким образом, определяемый показатель релевантности RSV может изменяться в диапазоне от 0 до N(N — число словоформ или терминов в словаре системы) и действительно количественно отражает степень релевантности документов. Так, в приведенном на рис. 6.10 примере значение RSV1 =2, а значение RSV2 =1. Для выдачи пользователю конкретного набора релевантных документов информационно-поисковые системы ограничиваются выдачей документов, показатель релевантности которых запросу RSV превышает некоторый заранее установленный порог.
Следует также заметить, что при таком подходе абсолютные значения показателя релевантности зависят не только собственно от самой степени релевантности, но и от количества N словоформ в словаре системы. Поэтому на практике применяютнормализованный вариант RSV,определяя его с учетом ортогональности и ортонормированности поискового пространства как косинус угла между вектором ПОД и вектором ПОЗ:
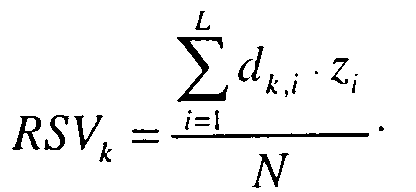
В этом случае RSV принимает значения от 0 до 1 и не зависит от объема словаря системы.
Определенным
недостатком такого подхода к расчету
количественной меры релевантности
является нечувствительность к
степени соответствия отсутствующих
словоформ (терминов) в ПОД и ПОЗ.Интуитивно понятно, что чем ближе
содержание документа и запроса, тем
меньше в документе должно быть
словоформ (терминов), которых нет в
запросе. Если, к примеру, в словаре
системы всего 6 элементов и имеется два
документа![]() и
и![]() ,
то для запроса
,
то для запроса![]() значениеRSV для обоих документов
будет равно 2 (33%), хотя интуитивно понятно,
что более близким по содержанию является
первый документ, а второй документ,
скорее всего, затрагивает более
широкую тематику, не обязательно
интересующую пользователя.
значениеRSV для обоих документов
будет равно 2 (33%), хотя интуитивно понятно,
что более близким по содержанию является
первый документ, а второй документ,
скорее всего, затрагивает более
широкую тематику, не обязательно
интересующую пользователя.
Такой чувствительностьюобладает показатель релевантности, определяемый следующим образом:
![]()
где
![]() и
и![]() — дополнение к элементам
— дополнение к элементам
![]() и
и![]() ,
т. е.
,
т. е.
![]() ,
если
,
если
![]() и наоборот.
и наоборот.
Если вернуться к
предыдущему примеру с документами
![]() ,
,![]() и запросом
и запросом![]() ,
тоRSV для первого документа будет
равным 5 (83%), а для второго документа
2 (33%), что выглядит, конечно же,
«справедливее».
,
тоRSV для первого документа будет
равным 5 (83%), а для второго документа
2 (33%), что выглядит, конечно же,
«справедливее».
Более развитым, но и более сложным подходом к определению мер близости ПОД и ПОЗ является учет разной значимости словоформ (терминов) и их зависимости друг от друга.В пространственно-векторной модели это означаетотход от ортогональности и ортонормированности базисных векторов поискового пространства.В этом случае скалярное произведение векторов ПОД и ПОЗ более гибко и осмысленно отражает близость соответствующих векторов и, тем самым, смысловое содержание документов и запросов.
В простейшем варианте подобного расширения пространственно-векторной модели различные словоформы в глобальном словаре системы дополняются специальными весовыми коэффициентами,отражающимиважность соответствующей словоформы (термина) для конкретной предметной обласmu.Соответственно поисковые векторы документов и запросов в этом случае превращаются из двоичных векторов в обычные, т. е. с любыми значениями (а не только 0 или 1) своих компонент. Иногда такой подход называют «окрашиванием»* глобального словаря системы. Следует также заметить, что в случае перехода от глобального словаря (отражающего все слова и словоформы) к словарю терминов происходит вырождение полнотекстового характера ИПС и она переходит в категорию систем на основе тезаурусов.
* В смысле окрашивания по определенной предметной области.
На практике применяются также и другие подходы, расширяющие возможности двоичной (ортогональной и ортонормированной) пространственно-векторной модели. Такие подходы базируются на вероятностно-статистической модели.При этом можно выделить две разновидности вероятностно-статистического подхода:
• придание весовых коэффициентов словоформам (терминам) глобального словаря вне контекста конкретного документа;
• придание весовых коэффициентов компонентам векторов ПОД по итогам индексирования конкретного документа (с учетом контекста конкретного документа).
Первый подходоснованна анализе итогов индексирования совокупности документов, уже вошедших в базу(хранилище) ИПС. Совокупность словоформ (терминов), обязательно присутствующих в любом документе базы, считается наиболее адекватно отражающей тематику предметной области ИПС, и соответствующие словоформы (термины предметной области) получают наибольший вес, наибольшую значимость в словаре системы, по которому производится индексирование документов. В качествечисловых характеристик весов значимости терминовиспользуются те или иные статистические параметры,такие, например, как относительная или абсолютная частота вхождения термина в документы базы системы. Разновидностью такого подхода являетсяучет количества вхождений в совокупность документовбазы тех или иныхсловоформ или терминов.
Более сложные варианты развития первого подходаосновываются на технологиях«обучения»инастраиванияИПС на конкретные предметные области. Традиционный способ обучения основывается на использовании обучающей выборки документов.Такая выборка формируется либо на основе отбора текстов экспертами в конкретной предметной области, либо путем использования документов по соответствующим рубрикам каталогов библиотек и т. п. Далее осуществляется исследование обучающей выборки на предмет статистических показателей вхождений в документы выборки тех или иных словоформ или терминов. Результатом обучения является«окрашенность»(различные весовые коэффициенты словоформ) словаря системы.
Другой подходосновывается наапостериорном выделении в поисковом пространстве«сгущений»векторов ПОД и последующем анализе совокупности и количественных данных вхождения в такие группы документов тех или иных словоформ (терминов). Предполагается, что такие группы соответствуют особенностям тематики конкретной предметной области, и словоформы, в них входящие, получают наибольшие весовые коэффициенты на основе тех или иных статистических параметров. Еще одним вариантом являетсяучет дискриминируемости (различимости) термина.Если при внесении в текст одного из двух близких по векторам ПОД документов какого-либо термина происходит резкое«расщепление»этих векторов, то такой термин считаетсяболее информативным и значимым, и его коэффициент важности, соответственно, должен быть выше.
При втором подходе к реализации вероятностно-статистической модели различия в весах значимости словоформ или терминовпроявляются по результатам индексирования конкретного документа. В простейшем варианте анализируется,сколько раз тот или иной термин входит в данный документ. Словоформам или терминам, имеющим наибольшее количество вхождений, присваиваются более высокие веса в векторе ПОД. В векторах запросов (ПОЗ) все словоформы или термины считаются равнозначными, но их различные веса в векторах ПОД обеспечивают большую релевантность тех документов, где соответствующие словоформы или термины встречаются наиболее часто.
Отдельной ветвью развития второго подхода является использование обратной, интерактивной связи с пользователем. В этом случае информационно-поисковая система стремится настроиться не столько на определенную предметную область, сколько на специфические особенности тематики информационных потребностей конкретного пользователя. В общем видедля каждого пользователя ИПСсоздаетсвое поисковое пространство с индивидуальным окрашиванием компонентов векторов ПОД. Такоеиндивидуальное окрашивание производится путемзапрашивания системой у пользователя его оценки релевантности выданных на каждый текущий запрос документов.Уточнив у пользователя, какие на его взгляд документы наиболее релевантны, система анализирует особенности и статистические параметры вхождения тех или иных словоформ (терминов) в эти наиболее релевантные документы, переопределяет и уточняет их весовые коэффициенты. Тем самым в последующих запросах более адекватно и глубже учитываются информационные потребности конкретного пользователя.
Существуют и другие разновидности вероятностно-статистических подходов к расширению пространственно-векторной модели поиска документов, но, к сожалению, из-за отсутствия в документации на коммерческие ИПС соответствующей информации по деталям механизмов поиска и релевантности документов оценить и проанализировать их эффективность довольно затруднительно.
В целом же информационно-поисковые полнотекстовые системы являются одним из наиболее интенсивно развивающихся направлений документальных информационных систем, существенно продвигая теорию и практику информационного поиска документов и развивая методы анализа и автоматизированной обработки текстовой неструктурированной информации.