

5. Распределенные информационные системы
В некомпьютерных информационных технологиях информационные ресурсы организаций и предприятий, с одной стороны, разделены и распределены логически (по различным подразделениям, службам) и физически (находятся в различных хранилищах, картотеках, помещениях). С другой стороны, информационные ресурсы создаются и используются своей определенной частью или в целом коллективно или индивидуально. Иначе говоря, с одними и теми же документами, картотеками и прочими информационными массивами могут в рамках общего проекта или в своей части одновременно работать несколько сотрудников и подразделений.
Первоначальные подходы к созданию баз данных АИС заключались в сосредоточении данных логически и физически в одном месте — на одной вычислительной установке. Однако такая организация информационных ресурсов чаще всего является не совсем естественной с точки зрения традиционных («бумажных») информационных технологий конкретного предприятия (организационной структуры) и при внедрении АИС происходит «ломка» привычных информационных потоков и структур.* Все информационные ресурсы предприятия, организации сосредотачиваются централизованно в одном месте, что требует определенных технологических, кадровых и материальных затрат и может порождать ряд новых проблем и задач. Следует отметить, что такому подходу также способствовала и господствующая на начальном этапе автоматизации предприятий и организаций в 70-х годах тогдашняя парадигма вычислительных систем — общая мощная вычислительная установка (main frame)и групповая работа пользователей с удаленных терминалов через системы разделения времени.
* В данном контексте более понятен сам термин — «внедрение», предполагающий сопротивление.
Опыт внедрения автоматизированных систем управления в различных организационных структурах в 70-е— 80-е гг. показал не всегда высокую эффективность подобной автоматизации, когда новые технологические информационно-управленческие подразделения (отдел автоматизации, отдел АСУ, информационная служба и т. п.) и новые электронные информационные потоки зачастую функционировали вместе с сохраняющимися традиционными организационными структурами, а также вместе с традиционными («бумажными», «телескопными») информационными потоками.
Осознание подобных проблем постепенно стало приводить к мысли о распределенных информационных системах.
5.1. Понятие распределенных информационных систем, принципы их создания и функционирования
Впервые задача об исследовании основ и принципов создания и функционирования распределенных информационных систем была поставлена известным специалистом в области баз данных К. Дейтом в рамках уже не раз упоминавшегося проекта System R,что в конце 70-х — начале 80-х годов вылилось в отдельный проект создания первой распределенной системы (проект System R*).Большую роль в исследовании принципов создания и функционирования распределенных баз данных внесли также и разработчики системы Ingres.
Собственно в основе распределенных АИС лежат две основные идеи:
• много организационно и физически распределенных пользователей, одновременно работающих с общими данными — общей базой данных (пользователи с разными именами, в том числе располагающимися на различных вычислительных установках, с различными полномочиями и задачами);
• логически и физически распределенные данные, составляющие и образующие тем не менее единое взаимосогласованное целое — общую базу данных (отдельные таблицы, записи и даже поля могут располагаться на различных вычислительных установках или входить в различные локальные базы данных).
Крис Дейт сформулировал также основные принципысоздания и функционирования распределенных баз данных. К их числу относятся:
• прозрачность расположения данных для пользователя(иначе говоря, для пользователя распределенная база данных должна представляться и выглядеть точно так же, как и нераспределенная);
• изолированность пользователей друг от друга(пользователь должен «не чувствовать», «не видеть» работу других пользователей в тот момент, когда он изменяет, обновляет, удаляет данные);
• синхронизация и согласованность(непротиворечивость) состояния данных в любой момент времени.
Из основных вытекает ряд дополнительных принципов:
• локальная автономия(ни одна вычислительная установка для своего успешного функционирования не должна зависеть от любой другой установки);
• отсутствие центральной установки(следствие предыдущего пункта);
• независимость от местоположения(пользователю все равно где физически находятся данные, он работает так, как будто они находятся на его локальной установке);
• непрерывность функционирования(отсутствие плановых отключений системы в целом, например для подключения новой установки или обновления версии СУБД);
• независимость от фрагментации данных(как от горизонтальной фрагментации, когда различные группы записей одной таблицы размещены на различных установках или в различных локальных базах, так и от вертикальной фрагментации, когда различные поля-столбцы одной таблицы размещены на разных установках);
• независимость от реплицирования(дублирования) данных (когда какая-либо таблица базы данных, или ее часть физически может быть представлена несколькими копиями, расположенными на различных установках, причем «прозрачно» для пользователя);
• распределенная обработка запросов(оптимизация запросов должна носить распределенный характер — сначала глобальная оптимизация, а далее локальная оптимизация на каждой из задействованных установок);
• распределенное управление транзакциями(в распределенной системе отдельная транзакция может требовать выполнения действий на разных установках, транзакция считается завершенной, если она успешно завершена на всех вовлеченных установках);
• независимость от аппаратуры(желательно, чтобы система могла функционировать на установках, включающих компьютеры разных типов);
• независимость от типа операционной системы(система должна функционировать вне зависимости от возможного различия ОС на различных вычислительных установках);
• независимость от коммуникационной сети(возможность функционирования в разных коммуникационных средах);
• независимость от СУБД*(на разных установках могут функционировать СУБД различного типа, на практике ограничиваемые кругом СУБД, поддерживающих SQL).
* Данное свойство характеризуют также термином «интероперабельность».
В обиходе СУБД, на основе которых создаются распределенные информационные системы, также характеризуют термином «Распределенные СУБД»,и, соответственно, используют термин«Распределенные базы данных».
Важнейшую роль в технологии создания и функционирования распределенных баз данных играет техника «представлений» (Views).
Представлением называется сохраняемый в базе данных авторизованный глобальный запрос на выборку данных.Авторизованность означает возможность запуска такого запроса толькоконкретно поименованным в системе пользователем. Глобальность заключается в том, что выборка данных может
осуществляться со всей базы данных,в том числе из данных, расположенных на других вычислительных установках. Напомним, что результатом запроса на выборку является набор данных, представляющий временную на сеанс открытого запроса таблицу, с которой (которыми) в дальнейшем можно работать, как с обычными реляционными таблицами данных. В результате таких глобальных авторизованных запросов для конкретного пользователя создается некая виртуальная база данных со своим перечнем таблиц, связей,т. е.со «своей» схемой и со «своими» данными.В принципе, с точки зрения информационных задач, в большинстве случаев пользователю безразлично, где и в каком виде находятся собственно сами данные. Данные должны быть такими и логически организованы таким образом, чтобы можно было решать требуемые информационные задачи и выполнять установленные функции.
Схематично идея техники представлений проиллюстрирована на рис. 5.1.
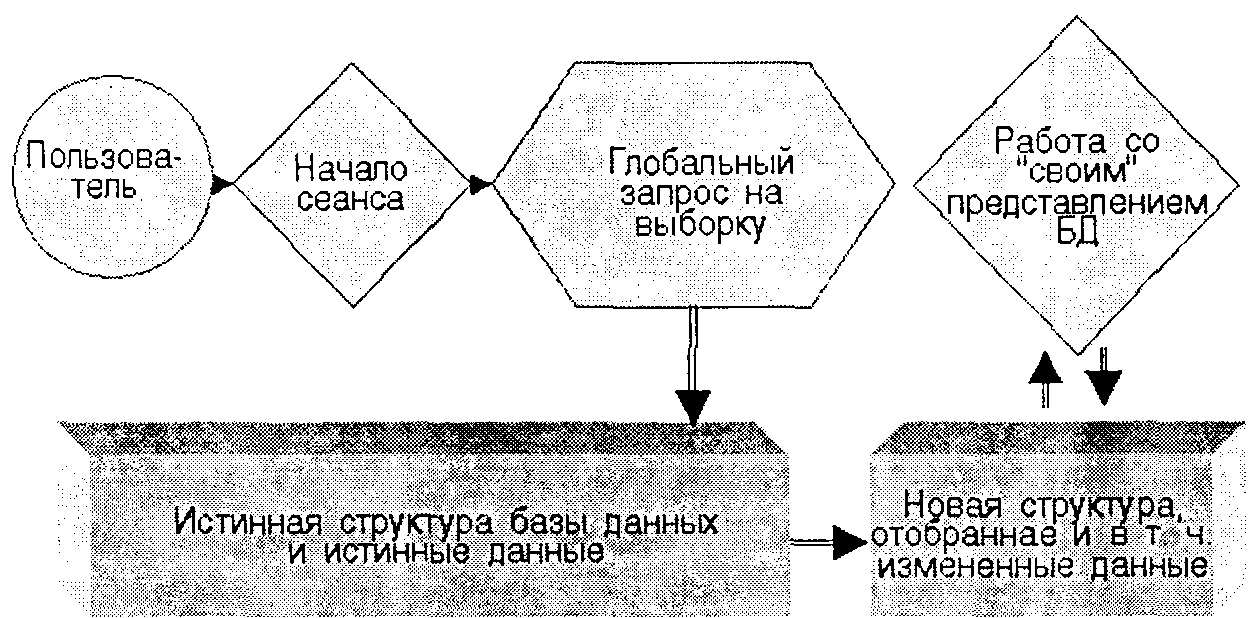
Рис. 5.1. Основная идея техники представлений
При входепользователя в распределенную систему ядро СУБД, идентифицируя пользователя,запускаетзапросы его ранее определенного и хранимого в базе данныхпредставленияи формирует ему «свое»видение базы данных,воспринимаемое пользователем как обычная (локальная) база данных. Так как представление базы данных виртуально, то «настоящие» данные физически находятся там, где они находились до формирования представления. При осуществлении пользователем манипуляций с данными ядро распределенной СУБД по системному каталогу базы данных само определяет, где находятся данные, вырабатывает стратегию действий, т. е. определяет, где, на каких установках целесообразнее производить операции, куда для этого и какие данные необходимо переместить из других установок или локальных баз данных, проверяет выполнение ограничений целостности данных. При этом большая часть таких операций прозрачна (т. е. невидима) для пользователя, и он воспринимает работу в распределенной базе данных, как в обычной локальной базе.
Технологически в реляционных СУБД техника представлений реализуется через введение в язык SQL-конструкций, позволяющих аналогично технике «событий-правил-процедур» создавать именованные запросы-представления:
CREAТЕ VIEWИмяПредставленият AS
SELECT...
FROM...
...;
В данных конструкциях после имени представления и ключевого слова ASразмещается запрос на выборку данных, собственно и формирующий соответствующее представление какого-либо объекта базы данных.
Авторизация представлений осуществляется применением команд (директив) GRANT,присутствующих в базовом перечне инструкций языка SQL(см. п. 4.1) и предоставляющих полномочия и привилегии пользователям:
GRANT SELECTON ИмяПредставленияTOИмяПользователя1, ИмяПользователя2,...;
Соответственно директива REVOKEотменяет уставленные ранее привилегии.
Несмотря на простоту и определенную изящность идеи «представлений», практическая реализация подобной технологии построения и функционирования распределенных систем встречает ряд серьезных проблем.Первая из них связана с размещением системного каталогабазы данных, ибо при формировании для пользователя «представления» распределенной базы данных ядро СУБД в первую очередь должно «узнать», где и в каком виде в действительности находятся данные. Требование отсутствия центральной установки приводит к выводу о том, что системный каталог должен быть на любой локальной установке. Но тогда возникаетпроблема обновлений.Если какой-либо пользователь изменил данные или их структуру в системе, то эти изменения должны отразиться во всех копиях системного каталога. Однако размножение обновлений системного каталога может встретить трудности в виде недоступности (занятости) системных каталогов на других установках в момент распространения обновлений. В результате может быть не обеспечена непрерывность согласованного состояния данных, а также возникнуть ряд других проблем.
Решение подобных проблем и практическая реализация распределенных информационных систем осуществляется через отступлениеот некоторых рассмотренных вышепринципов создания и функционирования распределенных систем.В зависимости оттого, какой принцип приносится в «жертву» (отсутствие центральной установки, непрерывность функционирования, согласованного состояния данных и др.) выделилисьнесколькосамостоятельныхнаправленийв технологиях распределенных систем —технологии «Клиент-сервер», технологии реплицирования, технологии объектного связывания.
Реальные распределенные информационные системы, как правило, построены на основе сочетания всех трех технологий, но в методическом плане их целесообразно рассмотреть отдельно. Дополнительно следует также отметить, что техника представлений оказалась чрезвычайно плодотворной также и в другой сфере СУБД—защите данных. Авторизованный характер запросов, формирующих представления, позволяет предоставить конкретному пользователю те данные и в том виде, которые необходимы ему для его непосредственных задач, исключив возможность доступа, просмотра и изменения других данных.