

2.3. Внутренняя схема баз данных фактографических аис
Изначально и по сей день программное обеспечение АИС (СУБД) в качестве места физического размещения данных ориентировано на внешнюю (дисковую) память. Как уже отмечалось, размещение данных во внешней памяти, точнее эффективность доступа к ним во внешней памяти, существенно влияет на эффективность обработки данных. В результате важным аспектом АИС является внутренняя схема базы данных, которую организует и поддерживает СУБД.
В общем плане внутренняя схема базы данных включает три основных компонента, представленные на рис. 2.10.

Рис. 2.10. Cocтаввнутренней схемы базы данных
Центральным компонентом внутренней схемы являются информационные массивы,включающие собственноданные(информационных объектов логической схемы БД, т.е. в реляционных СУБД таблиц), и массивыиндексов,являющихся специальными дополнительными конструкциями для ускорения доступа к данным основных информационных объектов. Информационные массивы в большинстве СУБД состоят из одной или нескольких так называемыхстраниц,каждая из которых содержит совокупность некоторых единичных элементов, называемыхфизическими записями.В результате, единичным элементом внутренней схемы баз данных АИС является физическая запись, в большинстве случаев совпадающая по смыслу с логической записью, т. е. в реляционных СУБД с табличной строкой.
Способы организации записей в страницах (расположение, добавления, корректировка, удаление) составляют физические структурыданных, которые образуют третий (низший) уровень представления информации в информационной системе (см. рис. 1.4).
Важным компонентом внутренней структуры является каталог БД,в котором размещается системная информация по логической структуре БД, включающая описание основных информационных объектов (имена, структура, параметры, связи) и ограничения целостности данных. Организация системной информации БД определяется особенностями конкретной СУБД, а сам каталог может входить непосредственно в файлы данных (область описателей данных) или составлять отдельный информационный массив.
Как уже отмечалось, в состав автоматизированного банка данных АИС помимо самой базы данных входит и прикладной компонент,образуемый совокупностью интерфейсных элементов представления, ввода и обработки данных, типовых запросов и процедур обработки данных, а также «событий» и «правил», отражающих правила и специфику предметной области АИС (так называемые «правила бизнеса»). Соответственно во внутренней схеме БД выделяется специальная область, в которой размещается информация по прикладному компоненту АИС.
Все три части внутренней структуры и их составные элементы (например, информационные массивы отдельных информационных объектов БД) могут размещаться в одном едином файле базы данных или в разных файлах. Во втором случае внутренняя схема БД определяется совокупностью и порядком расположения данных файлов.
2.3.1. Физические структуры данных
Страничная организация информационных массивов БД определяется общей спецификой доступа к данным больших объемов. Доступ к физическим записям во внешней памяти в большинстве СУБД осуществляется через считывание в оперативную память страниц файла данных, содержащих соответствующие записи. Непосредственная обработка записей производится в оперативной памяти, для чего СУБД образует и поддерживает, как уже отмечалось, специальные буферы,в которых временно размещаются страницы, содержащие обрабатываемые записи. После завершения обработки страница с соответствующими записями «выталкивается» из буфера и фиксируется в дисковом файле.
Аналогичным образом осуществляется размещение и доступ к индексным массивам. В итоге общий принцип организации доступа к данным во внешней памяти можно проиллюстрировать схемой, приведенной на рис. 2.11.
Физические структурыорганизации файлов данных подразделяютсяна линейныеинелинейные.
В линейных структурахв одну страницу файла базы данных объединяются записи-кортежи одной таблицы (информационного объекта), которые располагаются впоследовательном(линейном)порядкедруг за другом. Каких-либо ссылок, указателей на связи между записями не предусматривается.
Если не применяется специального порядка размещения записей в страницах (так называемая «расстановка» записей), то при добавлениизаписей в большинстве случаев в линейных структурах каждая новая запись помещается непосредственно за последней записью. Если страница файла данных заполняется, то для соответствующей таблицы выделяется дополнительная страница.
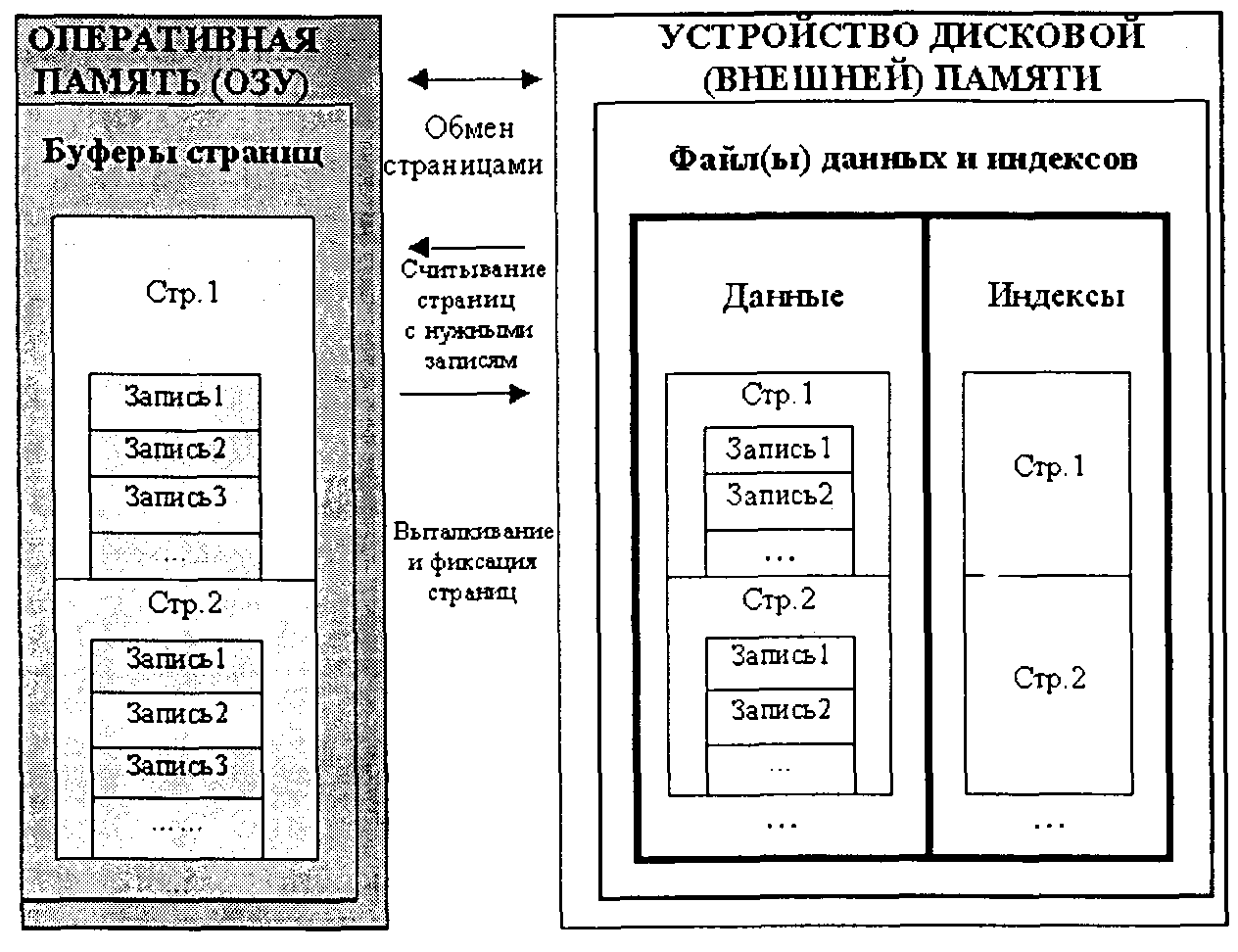
Рис. 2.11. Общий принцип организации внутренней схемы базы данных
Удалениезаписей в линейных структурах может производиться двумя способами. Впервом способепри удалении записи сразу же осуществляется автоматическое перезаписывание на новых позициях всех строк-записей, лежащих за удаляемой, с целью уплотнения и ликвидации появляющихся пустых мест. Подобный подход обеспечивает максимальную эффективность использования дискового пространства, но вызывает существенные накладные расходы при любых операциях по удалению записей. Поэтомудругим,достаточно распространеннымспособомявляется простое «вычеркивание» удаляемой записи без перезаписывания всех записей, лежащих за удаляемой, с соответствующим появлением пустых мест в страницах файла данных. Ведение базы данных в этом случае может быть организовано так, чтобы при превышении общего объема пустых мест в странице выше определенного значения (скажем, больше 30%) специальный компонент СУБД автоматически производил дефрагментацию страниц, устраняя пустые места по ранее удаленным записям. В некоторых СУБД запуск данной процедуры предоставляется непосредственно самому пользователю (администратору) для периодического уплотнения (сжатия) файла базы данных.
При корректировкахзаписей могут возникать случаи, когда новое значение изменяемого поля корректируемой записи может потребовать больше (меньше) дискового пространства, ранее занимаемого под старое значение данного поля. Решение этой проблемы приводит к двум разновидностям линейных структур файлов баз данных.
Первая разновидностьоснована на подходе, позаимствованном изструктуры текстовых файлов.Текстовый файл состоит из последовательно расположенных строк символов (набора байтов, определяющих номера символов строки в соответствии с кодовой таблицей). Строки имеют различную длину и отделяются друг от друга символом возврата каретки. Строка в данном случае является физической записью, а доступ к ней осуществляется по ее номеру kпутем последовательного считывания (продвижения) k-1предшествующих строк-записей (см. рис. 2.12).

Рис. 2.12. Линейная структура текстового файла
Если при корректировке какого-либо поля требуется больше (меньше) дискового пространства, то файл расширяется (уплотняется) с автоматическим перезаписыванием на новых позициях всех строк, лежащих за корректируемой. Такой подход, так же, как и первый подход при удалениях записей, обеспечивает максимальную эффективность использования дискового пространства, но не дает возможности быстрого прямого доступа к нужной строке, так как местоположения записей постоянно меняются.
* Точнее говоря, перезаписываются все записи соответствующей страницы. Если она переполняется, то перезаписываются записи и следующей страницы, и т. д.
Другим подходом к организации линейных структурдля решения проблем корректировки данных является выделение для каждой записи одинакового дискового пространства, исходя из максимально возможного заполнения строк по установленным типам полей.
Такой подход применяется в широко используемых для создания «настольных информационных систем» (системы «рабочего стола») СУБД куста dBASE (dBase, FoxPro, Clipper),которые создают и оперируют базами данных в формате так называемых dbf-файлов.Структура dbf-файла состоит из трех частей* — заголовка, блока описания структуры базы и информационной части (см. рис. 2.13). В заголовке последовательно представлены поля, которые определяют тип файла базы данных (с memo-полями или без них), дату последнего изменения, номер последней записи, смещение, с которого начинается информационная часть (записи), размер каждой записи. Блок описания структуры размещается после заголовка до информационной части и состоит из последовательности элементов, каждый из которых описывает определенное поле логической структуры (схемы) базы данных. Структура описания поля содержит последовательное описание имени поля, типа поля (числовое, текстовое, дата и т. д.), длины поля и заканчивается специальным символом для отделения описания одного поля от другого. Информационная часть состоит из последовательности групп байтов одинаковой длины без специальных разделителей, каждая из которых собственно и выражает содержимое конкретной физической записи.
* Спенс Р. Сliрреr. Руководство по программированию. Версия 5.01 / Пер. с англ — Мн.: Tивали, 1994-480 с (с.428).

Рис. 2.13. Линейная структура dbf-файла
Такой способ организации данных обеспечивает прямой доступ к любой записи, так как ее положение (смещение) однозначно вычисляется по ее номеру и параметрам полей. Вместе с тем эффективность использования дискового пространства при таком подходе невысокая, так как в полях записей хранятся и пустые значения (т. е. физически занимают место). Тем не менее простота и эффективность доступа в таких линейных структурах файлов баз данных обусловили их популярность в тех случаях, когда объем данных невелик и вопросы эффективности использования дискового пространства не существенны.
В нелинейных структурахзаписи одного информационного объекта необязательно располагаются друг за другом на одной странице файла данных, но обязательно содержатспециальные указателина следующую запись объекта(односвязные списки)или на связанные записи других информационных объектов(многосвязные списки, древовидные структуры).Соответственно физические записи в нелинейных структурах включают помимо информационных полей одно или несколькополей указателей,где размещаются адреса связанных записей (см. рис. 2.14).
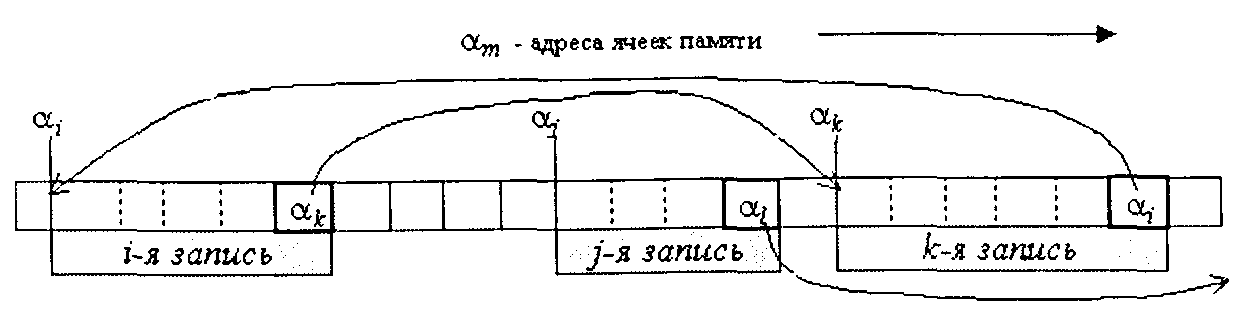
Рис. 2.14. Нелинейная структура данных ни примере односвязного списка (поля указателей выделены жирными рамками)
Непосредственная адресация* связанных записей обеспечивает в большинстве случаев более эффективный,чем в линейных структурах,доступ к данным.Однако расплатой за это являютсясущественно большиеисложныепо сравнению с линейными структурамизатратыипроцедуры преобразования(перетряски) файла базы данных при любыхоперациях добавления, удаления и корректировки записей,так как помимо проблем определения мест размещения записей и появления пустых мест в файле данных добавляется проблема перенастройки указателей на связанные записи после изменения данных.
* Реализуется в виде прямой или косвенной адресации. При прямой адресации в указателях размещаются физические адреса начала связанных записей. При косвенной адресации в указателях находятся номера связанных записей, физические адреса которых отыскиваются по специальному справочнику, в который ставятся на учет физические адреса всех новых записей.
Образование страниц физических записей файлов данных осуществляется на основе той или иной стратегии минимизации расходов на доступ к записям и расходов на операции их добавления, удаления и корректировки, и существенным образом зависит от типа конкретной нелинейной структуры. Одной из таких стратегий является минимизация расходов на доступ к записям, связанным на логическом уровне отношением «Один-ко-многим», что обусловлено широкой распространенностью таких отношений в огромном количестве предметных областей АИС. Данная стратегия основывается на использовании иерархических древовидных структур.
Общая схема этой стратегии такова. Для записей информационного объекта на стороне «Один» образуется страница файла данных, в которую последовательно (как в линейных структурах) помещаются соответствующие записи. При появлении в базе данных связанных записей для каждой записи из страницы объекта на стороне «Один» образуются «подчиненные страницы» для размещения соответствующих связанных записей объекта на стороне «Многие». В свою очередь, подчиненные записи сами могут иметь свои подчиненные записи, для которых создаются соответствующие страницы, и т. д. (см. рис. 2.15, а.
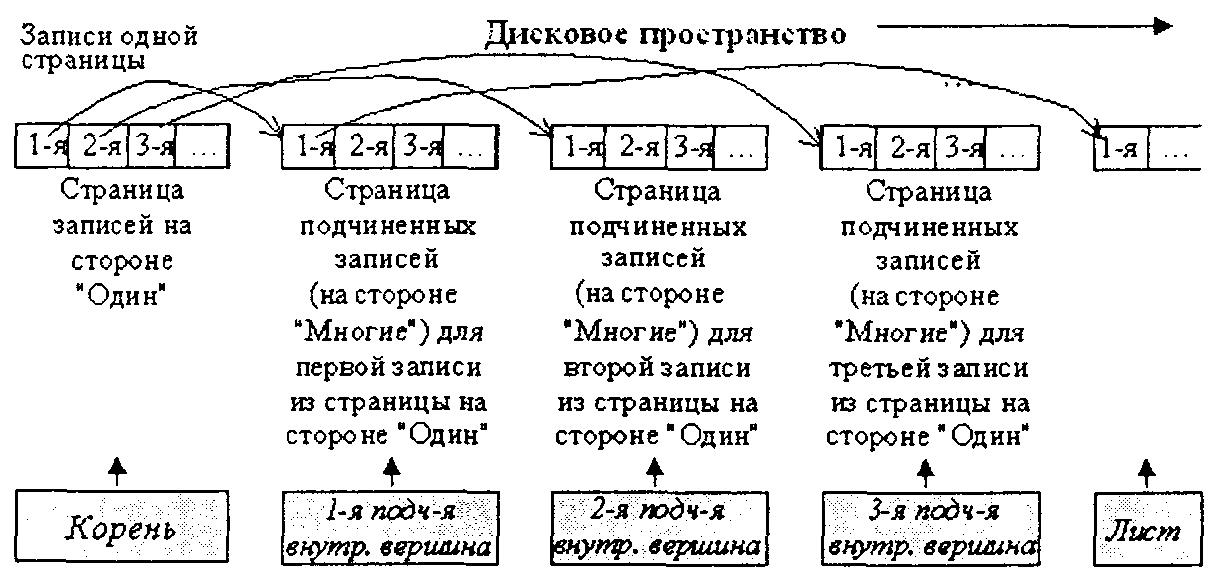
Рис. 2.15. а. Пример нелинейной древовидной иерархической структуры данных
Если в процессе ведения базы данных какая-либо страница переполняется, то для нее образуется связанная страница-продолжение на основе техники односвязного списка.*
* В конце каждой страницы выделяется специальное поле-указатель на возможное продолжение страницы (т.н. цепной список) помимо того, что каждая запись страницы сама содержит поле-указатель на страницу подчиненных записей.
При таком подходе действительно обеспечивается эффективная обработка связанных записей, так как осуществляется не единичное, а сразу страничное их считывание в буферы оперативной памяти. Временные затраты на поиск и обработку записей в буферах оперативной памяти существенно меньше затрат на считывание данных из «медленной» внешней памяти и блоковое (страничное) считывание обеспечивает существенный выигрыш в расходах на доступ и обработку связанных записей.
Однако во многих предметных областях АИС отношения между информационными объектами могут порождать ситуации наличия у определенных записей на стороне «Многие» сразу нескольких разных предков на стороне «Один» (см., например, рис. 2.3), что не вписывается в рамки подобных древовидных иерархических структур. Решение таких проблем обычно осуществляется через введение избыточности (дублирования) данных по связанным записям или другими способами.
Для формализованного описания нелинейных структур применяют аппарат теории графов, в рамках которого подобные иерархические древовидные структуры называются деревьями.*На рис. 2.15, б приведено условное изображениекорневого дерева,соответствующего иерархической нелинейной структуре данных на рис. 2.15, а, а также термины и понятия, связанные с ним. Вершины (узлы) дерева по отношению друг к другу могут бытьпредкамиилипотомками.Предок может иметь несколько потомков, но каждый потомок имеет только одного предка. Вершины, имеющие общего предка, называютсябратьями.Вершины, имеющие потомков, называютсявнутренними.Внутренняя вершина, не имеющая предков, называетсякорнем дерева.Вершины, не имеющие потомков называютсялистьями.Все внутренние вершины корневого дерева упорядочиваются по уровнямиерархии. Уровень узла определяется количеством предков до корня дерева. Количество уровней называетсявысотойдерева.
* Деревомназывается связный неориентированный граф без циклов (см., например Лекции по теории графов/ Емелнчев В. А., Мельников О. И., Сарванов В.И., Тышкевич Р.И.—М.: Наука, 1990, или Асанов М.О. Дискретная оптимизация: Учебное пособие. —Екатеринбург: УралНАУКА, 1998.
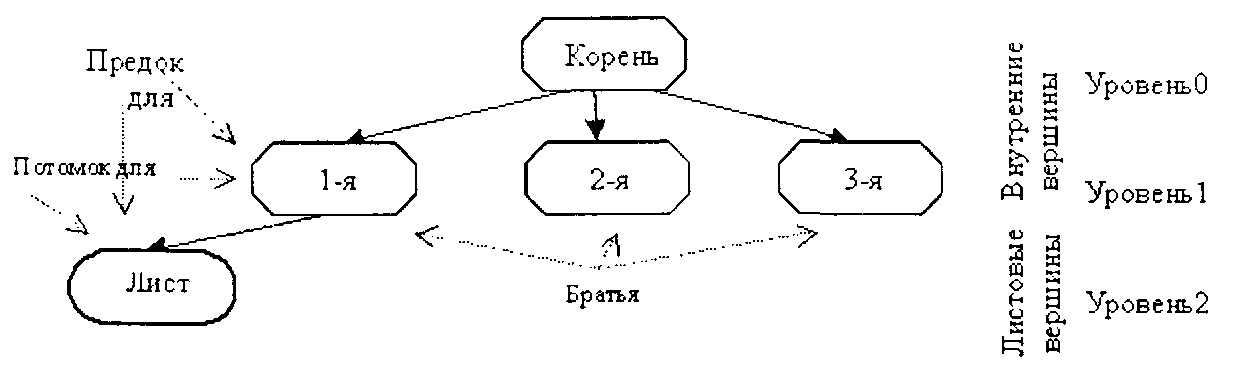
Рис. 2.15, 6. Условное изображение средствами теории графов нелинейной древовидной иерархической структуры
Еще одним важным параметром деревьев является максимально возможное количество потомков у одного предка. Данный параметр называется степеньюдерева. Деревья степени больше двух называютсясильноветвистыми.И наконец, важным в практическом плане для нелинейных структур данных является понятиесбалансированностидерева. Различаютсбалансированность по степени вершин,когда каждая внутренняя вершина может иметь количество потомков, ограниченное определенной и одинаковой для всех вершин величиной{арностьдерева) исбалансированность по высоте,когда путь (количество вершин) от корня до любого листа дерева одинаков или различается не более чем на единицу.
Развитый математический аппарат теории графов позволил разработать для древовидных структур данных оптимальные по определенным критериям операции обхода(поиска нужной записи),включения(добавления новой записи) иисключения (удаления записи) с целью минимизации расходов как по доступу, так и по изменению данных. Хорошая алгоритмизируемость этих операций предопределила широкое использование нелинейных древовидных структур в схемах физической организации данных, обеспечиваемых СУБД.