


Chapter 7: Database Design and Development
Creating Database Tables
Let’s start to create the tables for our intranet application. Tables can be thought of as the drawers in a filing cabinet: just as we could separate different information into different drawers within our filing cabinet, we can break information about employees, departments, and help desk requests into different tables. Tables can also be compared to spreadsheets, as they have rows and columns, but they have many other powerful features. They know what kinds of data they’re allowed to store, they can relate to data contained in other tables, and they can be searched and manipulated with a very powerful language called SQL (which you’ll learn about in Chapter 8).
You can organize the tables in your database using either Visual Web Developer or SQL Server Management Studio, depending on your preference. While SQL Server Management Studio is more powerful, both tools can be used for basic tasks such as creating database tables.
In just a minute, we’ll dive in and create our first table. Before we do, it’s worth giving some thought to how many tables our application will need, and exactly what they’ll contain. We can think of tables as lists of entities. Entities are the rows or records in our table, and would include the employees Zak Ruvalcaba and Cristian Darie. Drawing our tables and their entities on paper is a great way to plan the logical design of the database. The logical design shows what kinds of data our database will need to store, and outlines the relationships that we want to exist between specific pieces of data.
However, unlike a typical spreadsheet file, the tables defined in the logical design do not usually represent the way we’ll store the data in the database. This is taken care of in the physical design phase, in which we create a practical blueprint that allows us to improve database speed, enable relationships between different tables, or implement other advanced features—basically, to optimize our database in various ways.
Your database’s design has important consequences in terms of the way your application works, and how easy it is to extend, so it’s important to take the logical and physical design phases seriously. Let’s take a look at an example, so you can see what I mean.
Let’s say that, in addition to a name, username, and telephone number, you wanted to keep track of the departments in which employees work at Dorknozzle.
258

Creating Database Tables
To achieve this, it might seem logical simply to add a column to the Employees table we discussed above; Figure 7.6 shows how this would look.
Figure 7.6. The Employees table
It looks pretty good, right? Well, it’s okay in theory. However, if you went ahead and implemented this structure in your database, you’d likely end up in trouble, because this approach presents a couple of potential problems:
Every time you insert a new employee record, you’ll have to provide the name of the department in which that employee works. If you make even the slightest spelling error, then, as far as the database is concerned, you have a new department. Now, I don’t know about you, but I’d be pretty upset if my employee record showed me as the only person working in a department called “Enineering.” And what if Dorknozzle Sr decides to rename one of the departments? You might try to update all the affected employee records with the new department name, but, even if you miss just one record, your database will contain inconsistent information. Database design experts refer to this sort of problem as an update anomaly.
It would be natural for you to rely on your database to provide a list of all the departments in the company, so you could, for example, choose to view a list of employees in a particular department. But if, for some reason, you deleted the records of all the employees in that department (don’t ask me why—your human resource issues aren’t my problem!), you’d remove any record that the department had ever existed (although, if you really did have to fire everyone, that might be a good thing…). Database design experts call this a delete anomaly.
These problems—and more—can be dealt with very easily. Instead of storing the information for the departments in the Employees table, let’s create an entirely new table for our list of departments. Similarly to the Employees table, the new
Departments table will include a column called Department ID, which will identify each of our departments with a unique number. We can use those de-
259
Chapter 7: Database Design and Development
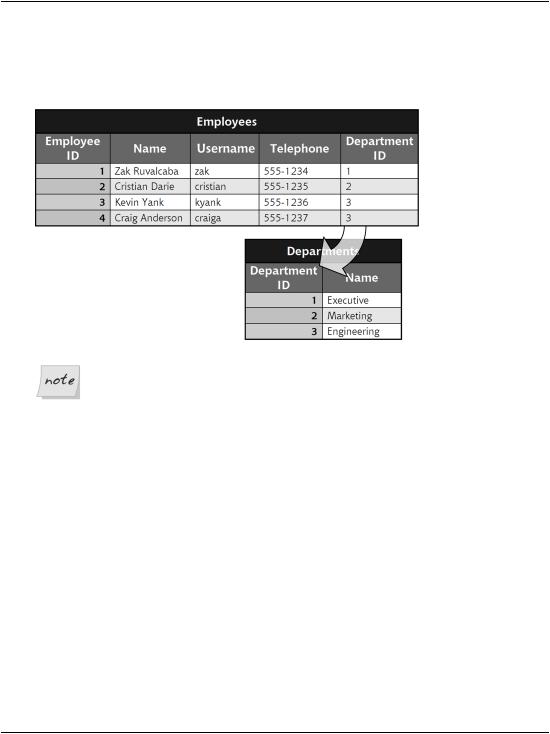
partment IDs in our Employees table to associate departments with employees. This new database layout is shown in Figure 7.7.
Figure 7.7. The Employees table with a new Department ID field
Database Design ... and Implementation
As this example has shown, the way you’d naturally draw your database design on paper, and the best way to implement the design in practice, can be two different things. However, keep in mind that there are no absolute rules in database design, and expert database designers sometimes bend or break rules to meet the requirements of particular circumstances.
What these tables show are four employees and three departments. The Department ID column of the Employees table provides a relationship between the two tables, indicating that Zak Ruvalcaba works in department 1, while Kevin Yank and Craig Anderson work in department 3. Notice also that, as each department appears only once in the database, and appears independently of the employees who work in it, we’ve avoided the problems outlined above.
However, the most important characteristic of this database design is that, since we’re storing information about two types of entities (employees and departments), we’re using two tables. This approach illustrates an important rule of thumb that we must keep in mind when designing databases:
Each type of entity about which we want to be able to store information should be given its own table.
260

Creating Database Tables
With this rule in mind, we can sit back and think about the Dorknozzle application we want to build, as described in Chapter 5. We need to think of the design in terms of the entities that we want to track, and come up with a preliminary list of tables. You’ll become more comfortable with this kind of task as you gain experience in database design, but it’s worth giving it a try on your own at this stage. When you’re done, compare your list to the one below, and see how you did!
Employees
This table keeps track of our company’s employees, each of which is associated with a department.
Departments
This table lists the departments in our company.
Help Desk Problem Reports
This table stores the problem reports that have been filed at Dorknozzle’s employee help desk. A category, subject, and status will be associated with each problem report.
Help Desk Categories
The categories that are available for help desk items (“Hardware,” “Software,” etc.) are stored in this table.
Help Desk Subjects
The subjects that are available for help desk items (“Computer crashes,” “My chair is broken,” etc.) are stored in this table.
Help Desk States
This table stores the various states in which a help desk item can exist (“open” or “closed”).
Breaking down and analyzing the items of information that need to be saved is the first step in determining the database’s design—this process represents the logical design phase that I mentioned earlier. Through this process, we work to build a high-level definition of the data that needs to be saved. This definition can then be transformed into a physical design structure, which contains the details required to implement the database.
As you analyze the data that needs to be stored, you may come across items that we overlooked when we designed the site in Chapter 5, such as help desk item categories, subjects, and states, which aren’t obvious entities in our application’s current design. However, remember that whenever you predict that your database
261