


Working with Files in Groovy
2.Running this script displays the following output:
100.0 A 200.0 B 300.0 C 400.0 D
How it works...
The recipe's code uses Grape (see the Simplifying dependency management with Grape recipe in Chapter 2, Using Groovy Ecosystem) to fetch the necessary dependencies:
Apache POI and POI OOXML, the latter required to deal with the post-2007 Excel files. The GrabExclude explicitly excludes the xml-apis library to avoid conflicts with the Groovy XML parser. Please note that the code imports classes from the org.apache.poi.xssf, the package used to access the newer Excel format. For the older format (pre-2007), we would have imported classes from the org.apache.poi.xssf package.
The script creates an XSSFWorkbook instance from the Workbook1.xlsx file and iterates on all the sheets found in the document. For each sheet, we use two nested closures (one for the rows and one for the current row's cells) to traverse the cells that have content and print the value on the console.
See also
ff The Simplifying dependency management with Grape recipe in Chapter 2, Using Groovy Ecosystem
ff http://poi.apache.org/
Extracting data from a PDF
The ubiquity of PDF files is due to the ability of almost every PC, Mac, and smart device to open and process this format. Electronic documents are often exchanged as PDF because they cannot be easily altered and are, by default, read-only.
Many organizations use PDF files to distribute reports, bank statements, and invoices. Being able to read such documents and extract the information they provide it's an invaluable tool in the belt of a Groovy programmer.
This recipe focuses on mining information from a PDF file.
 162
162
www.it-ebooks.info
Chapter 4
Getting ready
As for ZIP files (see the Reading data from a ZIP file recipe), Groovy doesn't have any class to deal with PDF files. Java too doesn't offer any built-in feature to read or write PDFs. Therefore, we are left to resorting to a third-party library. A Google search for Java read PDF yields numerous results with links to various libraries.
In this recipe, we will use iText, the most popular PDF library for the Java ecosystem. iText is a very powerful library for generating PDF files, but it also has a very simple API for mining the text inside the PDF file.
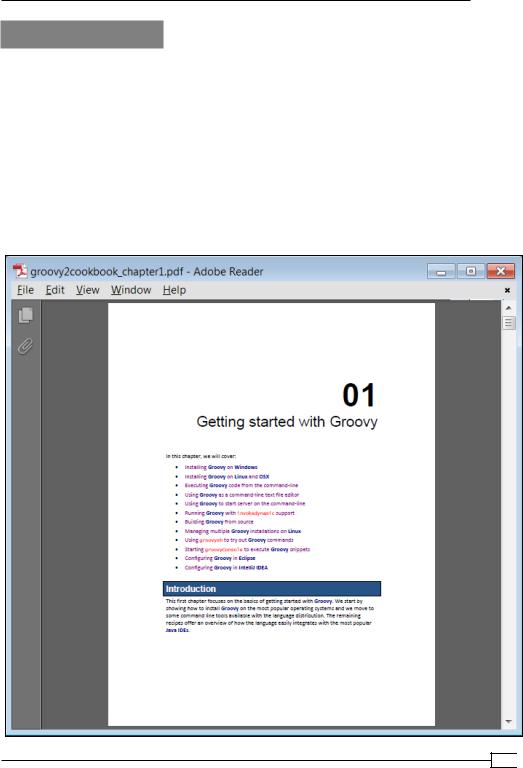
For demonstration purposes, we are going to use a PDF version of Chapter 1, Getting Started with Groovy of this book (a version of the file is attached to the code distribution) located in
the groovy2cookbook_chapter1.pdf file:
163
www.it-ebooks.info
Working with Files in Groovy
How to do it...
The Groovy code that follows shows you how to open a PDF file and dump the contents of the pages of a PDF file in the console.
1.First of all, we need to @Grab the iText library and declare all imported classes that we are going to make use of:
@Grab('com.itextpdf:itextpdf:5.3.2') import com.itextpdf.text.pdf.parser.* import com.itextpdf.text.pdf.*
2.After that, we can construct objects that help to achieve our final target:
def pdf = new PdfReader('groovy2cookbook_chapter1.pdf') def maxPages = pdf.numberOfPages + 1
def parser = new PdfTextExtractor()
3.And now, all that is left is to iterate through all the pages and extract the text:
(1..<maxPages).each { pageNumber ->
println parser.getTextFromPage(pdf, pageNumber)
}
4.Output should be as follows:
01
Getting started with Groovy
In this chapter, we will cover:
?Installing Groovy on Windows
?Installing Groovy on Linux and OSX
...
How it works...
The previous script does some interesting stuff. First, we use Grape (see the Simplifying dependency management with Grape recipe in Chapter 2, Using Groovy Ecosystem) to fetch the latest version of iText from a Maven repository (v5.3.2), through the Grab annotation. Then an instance of the com.itextpdf.text.pdf.PdfReader class is created for reading the PDF document. PdfReader can be constructed with different arguments, but we chose String for simplicity. After instantiating PdfReader, we get the number of pages of the
PDF file we intend to analyze. Again, to get the number of pages, it's a simple call to the getNumberOfPages method of PdfReader.
 164
164
www.it-ebooks.info

Chapter 4
Finally, we loop through all the pages and, for each page, we call getTextFromPage from the com.itextpdf.text.pdf.parser.PdfTextExtractor class. The method returns the text found in the page which is printed on the console.
There's more...
Extracting text from a PDF file is relatively easy in Groovy (and Java), but interpreting the structure of a PDF file can be a very daunting task as PDF files have a layout-oriented structure rather than a content-oriented one. If you have to cope with PDF documents that have a nonstandard structure (for example, columns or tables), you may want to write your own strategy for text extraction. The getTextFromPage method of the PdfTextExtractor class accepts instances of the TextExtractionStrategy interface.
iText has some implementations of the interface, such as SimpleTextExtractionStrategy, which stores all the snippets in the order they occur in the stream; but it is smart enough to detect which text portions should be combined into a single word or separated with a space character.
There is also a LocationTextExtractionStrategy interface that allows you to extract text only from certain area of a PDF file. The next script is a modified version of the previous one and shows you how to use LocationTextExtractionStrategy combined with
FilteredTextRenderListener. We define a small rectangular area from which the text is extracted. In this case, it's the area of the chapter's title. The part of the code that does the text extraction changes as we are passing the strategy to the getTextFromPage method and we only execute for the first page:
@Grab('com.itextpdf:itextpdf:5.3.2') import com.itextpdf.text.pdf.parser.* import com.itextpdf.text.pdf.* import com.itextpdf.text.Rectangle
def rect = new Rectangle(0, 550, 1000, 800)
def pdf = new PdfReader('groovy2cookbook_chapter1.pdf') def parser = new PdfTextExtractor()
def strategy = new FilteredTextRenderListener( new LocationTextExtractionStrategy(),
new RegionTextRenderFilter(rect))
println parser.getTextFromPage(pdf, 1, strategy)
The output should be as follows:
01
Getting started with Groovy
165
www.it-ebooks.info
Working with Files in Groovy
Another thing that you may face when parsing the PDF files is dealing with non-English texts. iText does a good job extracting text data for you, but in order to get proper result you need to know which encoding was used in the PDF file for the text you want to extract. For example, for saving Russian text encoded with the KOI8-R charset, you can use the following snippet:
new File('output.txt').withWriter('KOI8-R') { writer -> (1..<maxPages).each {
writer << parser.getTextFromPage(pdf, it)
}
}
This code saves the extracted text into the output.txt file using the specified encoding.
See also
ff http://itextpdf.com/
 166
166
www.it-ebooks.info