

statistika_проц_22
.pdfТаблица 3.2
Распределение населения РФ по величине среднедушевых денежных доходов в 2004–2007 гг.
(в процентах к итогу)
|
2004 |
2005 |
2006 |
2007 |
Все население |
100,0 |
100,0 |
100,0 |
100,0 |
в том числе со среднедушевыми |
|
|
|
|
денежными доходами в месяц, руб. |
|
|
|
|
Äî 2000,0 |
12,3 |
7,1 |
4,3 |
2,6 |
2000,1–4000,0 |
28,1 |
21,9 |
16,2 |
11,9 |
4000,1–6000,0 |
21,1 |
20,3 |
17,7 |
14,9 |
6000,1–8000,0 |
13,4 |
14,8 |
14,7 |
13,6 |
8000,1–10000,0 |
8,4 |
10,3 |
11,2 |
11,3 |
10000,1–15000,0 |
10,0 |
13,9 |
17,1 |
19,1 |
15000,1–25000,0 |
5,2 |
8,6 |
12,7 |
16,5 |
Свыше 25000,0 |
1,5 |
3,1 |
6,1 |
10,1 |
Источник: http://www.gks.ru/bgd/regl/b08_11/IssWWW.exe/Stg/d01/07-09.htm
собой, подразделяют на факторные (независимые) и результативные (зависимые). Результативные признаки изменяются под воздействием факторных признаков. Например, затраты на производство — факторный (независимый) признак, под воздействием которого изменяется выручка, как результативный (зависимый) признак. По результатам аналитической группировки можно определить направление связи между признаками. Так, если с увеличением (уменьшением) факторного признака растут (снижаются) значения результативного признака, т. е. движение признаков однонаправлено, то связь называют прямой. Если же движение признаков разнонаправлено, т. е. с увеличением (уменьшением) факторного признака снижаются (растут) значения результативного признака, то связь называют обратной.
Особенностью аналитической группировки является то, что в качестве группировочного признака всегда выбирается факторный признак, а каждая выделенная группа характеризуется средними значениями результативного признака. Пример аналитической группировки, представленный в таблице 3.3, позволяет утверждать, что между ставкой кредитования и средней суммой выданного кредита существует обратная связь.
51

Таблица 3.3
Группировка зависимости суммы выданных кредитов от размера ставки кредитования банка N (условные данные)
|
|
Сумма выданных кредитов, |
||
Группы кредитов по |
Количество |
|
ìëí ðóá. |
|
|
|
В среднем |
||
величине ставки |
выданных |
|
|
|
|
|
по указанной |
||
кредитования, % |
кредитов |
Всего |
|
|
|
процентной |
|||
|
|
|
|
|
|
|
|
|
ставке |
Äî 9 |
45 |
485 |
|
10,7778 |
9–11 |
29 |
318 |
|
10.9655 |
11–13 |
20 |
257 |
|
12,85 |
13–15 |
14 |
180 |
|
12,8571 |
Свыше 15 |
9 |
130 |
|
14,4444 |
Итого |
117 |
1370 |
|
11,7094 |
Необходимо отметить, что вследствие многообразия реальных связей между объектами социально-экономического явления его полная характеристика возможна только в том случае, если применяется система признаков (система показателей). Подобный комплексный подход позволяет выявить реальные взаимосвязи, взаимоотношения отдельных сторон процесса и отобразить процесс развития анализируемого явления.
Если группировка произведена по одному признаку, то она называется простой. Так, в таблице 3.3 произведена группировка по одному признаку — ставке кредитования.
Если же разделение совокупности на группы производится по двум и более признакам, то группировку называют сложной. Сложная группировка может быть выполнена в виде многомерной или комбинационной группировки. Многомерная группировка основана на измерении сходства или различий между единицами совокупности. Таким образом, многомерная группировка осуществляется не последовательно по отдельным признаком, а одновременно по комплексу признаков. Единицы, отнесенные к одной группе, имеют между собой меньше различий, чем единицы, отнесенные к другой группе. Нахождение этих групп осуществляется методами кластерного анализа при помощи таких специализированных пакетов программ, как Statistica, SPSS, SAS и ряда других. Частным случаем многомерной группировки является комбинационная группировка, при
52

которой группы, выделенные по одному признаку, подразделяются на группы по другому признаку и т.д., то есть в основании группировки лежат несколько признаков, взятых в комбинации.
|
|
Таблица 3.4 |
|
Внешнеторговый оборот России в 2006 г. |
|||
|
|
|
|
Внешнеторговые операции |
Âèä |
Объем операций, |
|
внешнеторговой |
|||
России |
ìëðä. äîëë. ÑØÀ |
||
операции |
|||
|
|
||
Со странами дальнего |
экспорт |
261,1 |
|
зарубежья |
импорт |
138,6 |
|
Итого оборот со странами дальнего зарубежья |
399,7 |
||
Со странами СНГ |
экспорт |
43,4 |
|
|
импорт |
25,2 |
|
Итого оборот со странами СНГ |
|
68,7 |
|
Всего |
экспорт |
304,5 |
|
|
импорт |
163,9 |
|
Итого внешнеторговых операций |
|
468,4 |
|
Составлено по источнику: Россия 2007: Стат. справочник/Росстат. — М., 2007. — С. 47.
Âтаблице 3.4 по первому признаку — признаку страны выделены две группы — операции со странами дальнего зарубежья и операции со странами СНГ. По второму признаку — признаку направления операций также выделены два признака — экспорт и импорт.
Âходе проведения экономического анализа часто приходится проводить перегруппировку данных по новым границам. Как правило, массив первичных данных при этом является недоступным.
Âэтом случае приходится осуществлять вторичную группировку, в виде образования новых групп на основе ранее сгруппированных данных, без использования массива первичных данных. Вторичная группировка может быть осуществлена двумя методами: методом объединения первоначальных интервалов или методом долевой перегруппировки.
Пример 3.1. Рассмотрим реализацию этих методов на примере, исходные данные для которого приведены в таблице 3.5.
53

|
Таблица 3.5 |
Распределение супермаркетов сети |
|
по объему среднедневной выручки |
|
|
|
Средний размер дневной выручки |
Количество супермаркетов |
супермаркетов, тыс. руб. |
|
Äî 100 |
12 |
100–200 |
25 |
200–300 |
30 |
300–400 |
20 |
400–500 |
10 |
500–600 |
8 |
Итого |
105 |
Решение
Метод объединения первоначальных интервалов используется в том случае, когда границы старых и новых групп совпадают. Перегруппируем данные, образовав новые интервалы: 0–200, 200–400, 400–600. Так как границы старых и новых интервалов совпадают, очевидно, что в первый «новый» интервал будут отнесены первый и второй «старые» интервалы, во второй «новый» интервал попадают третий и четвертый «старые» интервалы и т.д. При объединении интервалов суммируются и единицы наблюдения, прежде отнесенные к тому или иному интервалу. Результаты перегруппировки представлены таблице 3.6.
Таблица 3.6
Распределение супермаркетов сети по объему среднедневной выручки (вторичная группировка)
Средний размер дневной выручки |
Количество супермаркетов |
супермаркетов, тыс. руб. |
|
0–200 |
37 |
200–400 |
50 |
400–600 |
18 |
Итого |
105 |
Метод долевой перегруппировки основывается на предпосылке равномерности распределения единиц наблюдения внутри границ интервальных групп. Предположим, что необходимо образовать новые интервалы: 0–120, 120–240, 240–360, 360–480, 480–600.
В первый вторичный интервал полностью войдет первый интервал первичной группировки и часть второго интервала, который
54
разбивается на два отрезка: 100–120 и 120–200. Найдем долю, которая составляет длина отрезка 100–120 в первичном интервале 100–
200 êàê 120 - 100 = 1 = 0,2 . Таким образом, из второго первичного
200 - 100 5
интервала в первый вторичный интервал войдут 5 единиц (0,2½25), т.е. первый вторичный интервал будет содержать 17 супермаркетов(12+5). Второй «новый» интервал будет содержать 32 единицы, образовавшиеся как сумма оставшейся части второго первичного интервала — 20 единиц (25-5) и части третьего первичного интер-
вала — 12 единиц ( |
240 – 200 |
= |
2 |
= 0,4 , и далее 0,4½30). Следующие |
||
300 – 200 |
|
5 |
|
|||
|
|
|
|
|||
три интервала будут образованы с использованием такой же техники.
Таблица 3.7
Распределение супермаркетов сети по объему среднедневной выручки (вторичная группировка с использованием метода долевой перегруппировки)
Средний размер дневной выручки, тыс. руб. |
Количество супермаркетов |
0–120 |
17 |
120–240 |
32 |
240–360 |
30 |
360–480 |
16 |
480–600 |
10 |
Итого |
105 |
Метод долевой перегруппировки применяется также в тех слу- чаях, когда приходится сравнивать несколько групп данных, имеющих разные границы группировки. В этом случае одна из группировок выбирается в качестве базовой, а все остальные перегруппировываются в соответствии с ее границами.
В статистической практике широко применяются классификации, которые следует отличать от группировок. Классификация — устойчивое (стандартное) разграничение объектов определенных совокупностей на группы по качественным признакам, разработанное органами государственной и международной статистики. Наиболее известными являются классификации отраслей экономики, основных фондов, видов экономической деятельности и т.д. Несмотря
55

на то что классификации, как правило, действуют в течение длительного времени, при появлении новых классов или групп признаков в классификацию могут быть внесены изменения.
3.3.Ряды распределения: виды, правила построения
èграфическое изображение
Результаты группировки можно представить в виде статисти- ческих рядов распределения. Ряд распределения — это упорядо- ченное распределение единиц совокупности на группы по изучаемому признаку. В зависимости от группировочного признака разли- чают атрибутивные и вариационные ряды.
Атрибутивными рядами распределения называют ряды, построенные по качественным признакам. Примером атрибутивных рядов являются распределения населения по полу, национальности, статусу занятости, образованию и т.д.
Вариационными рядами распределения называют ряды, построенные по количественным признакам. Например, распределение населения по возрасту, сотрудников по стажу работы и уровню заработной платы, домохозяйств — по уровню доходов и расходов и т.д.
Вариационный ряд состоит из двух элементов: вариантов и частот. Под вариантами понимают конкретные значения признака, которые он принимает в вариационном ряду. Частоты ( fi ) — это численности отдельных вариантов или каждой группы вариационного ряда, то есть это числа, показывающие, как часто встреча- ются те или иные варианты в ряду распределения. Накопленные частоты (vi ) показывают число единиц совокупности, у которых значение варианта не больше данного. Сумма всех частот называется объемом совокупности ( n ). Помимо частот в вариационном ряду распределения могут рассчитываться частости ( wi ), представляющие собой частоты, выраженные либо в долях единицы,
либо в процентах относительно объема совокупности ( nfi ). Накоп-
ленные частости ( wi* ) рассчитываются как отношение накопленной частоты к числу единиц совокупности и характеризуют долю единиц совокупности со значением не больше данного варианта.
В зависимости от характера вариации вариационные ряды подразделяются на дискретные и непрерывные. Дискретный вариационный ряд характеризует распределение единиц совокупности по
56
дискретному признаку, т. е. признаку, принимающему только дискретные значения, число которых составляет счетное множество. Например, дискретный вариационный ряд может быть построен в случае группировки домохозяйств по числу детей, работающих членов семьи, иждивенцев.
Пример 3.2. Имеются следующие данные о числе детей в 60 семьях:
0,2,1,3,4,1,1,1,1,2,2,3,4,0,0,5,2,0,1,2,0,3,2,2,2,3,5,1,0,1,
1,1,2,3,1,1,1,0,0,2,0,3,1,0,4,4,2,1,0,1,2,1,1,0,3,2,1,1,1,0.
Решение
Для того чтобы построить вариационный ряд, ранжируем (упорядочим) исходные данные:
0,0,0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,
1,1,2,2,2,2,2,2,2,2,2,2,2,2,2,3,3,3,3,3,3,3,4,4,4,4,5,5.
Затем подсчитаем число семей, в которых вариационный признак ( xi ) — число детей, имеет одинаковое значение, т. е. найдем частоту ( fi ) и оформим результаты подсчетов в виде ряда распределения, записанного в таблице:
Группы семей по числу детей ( xi ) |
Число семей ( fi ) |
|
|
0 |
11 |
1 |
21 |
2 |
13 |
3 |
7 |
4 |
4 |
5 |
2 |
Итого |
60 |
Это — дискретный вариационный ряд, так как значения признака могут принимать конечное число отдельных значений.
В случае непрерывной вариации, когда величина варьирующего признака может принимать в определенных пределах любые значения, отличающиеся друг от друга на сколь угодно малую величину, целесообразно строить интервальные вариационные ряды.
Значения вариант в интервальных вариационных рядах могут быть
57
как дробными, так и целыми. Значения варьирующего признака в этом случае задаются в виде интервалов. Каждый интервал имеет нижнюю границу (наименьшее значение признака в интервале) и верхнюю границу (наибольшее значение признака в интервале). Величина интервала представляет собой разность между его верхней и нижней границами. Если интервал имеет обе границы, его называют закрытым. Первый и последний интервалы могут быть открытыми. В этом случае, первый интервал не имеет нижней границы, а последний — верхней. Такие интервалы могут быть условно закрыты. Для этого предполагается, что величина первого интервала равна величине второго, а величина последнего равна величине предпоследнего интервала. Далее от верхней границы первого интервала отнимают величину второго интервала и полу- чают нижнюю границу первого интервала, а к нижней границе последнего интервала прибавляют величину предпоследнего и получают верхнюю границу последнего интервала.
Интервальные вариационные ряды могут также строиться на основе дискретных рядов в случае, когда значительное число вариантов дискретного ряда имеют небольшую частоту появления относительно всего объема совокупности.
При построении интервального вариационного ряда важно определить величину интервала. Для этого используют формулу Стерджесса:
k = |
|
xmax − xmin |
, |
(3.1) |
|
|
|||
1 |
+ 3,322 lg N |
|
||
ãäå xmin — минимальное значение признака в совокупности, xmax — максимальное значение признака в совокупности, N — объем совокупности.
Для уточнения представления об интервальных вариационных рядах рассчитывают абсолютные и относительные плотности. Абсолютная плотность распределения — это частота, приходящаяся на единицу длины интервала. Абсолютная плотность интервала рас- считывается по формуле:
f(a)i |
= |
fi |
. |
(3.2) |
|
||||
|
|
ki |
|
|
Относительная плотность распределения — частость, приходящаяся на единицу длины интервала. Относительная плотность интервала может быть рассчитана как:
58

f(o)i |
= |
wi |
. |
(3.3) |
|
||||
|
|
ki |
|
|
Пример 3.3. В результате статистического опроса получены данные о заработной плате 30 специалистов коммерческих банков (тыс. руб.):
22,45,36,17,24,39,40,44,55,72,77,56,27,41,40,
31,33,18,55,64,67,70,34,21,20,47,30,29,47,51
Решение
Сделать какие-либо выводы из исходных данных не представляется возможным. Строить дискретный вариационный ряд также нерационально, так как он будет иметь большое число значений с частотами, равными единице. Более правильно построить интервальный вариационный ряд. Для этого воспользуемся формулой Стерджесса и определим величину интервала
k = |
|
77 −17 |
= |
|
60 |
≈ 10. |
|
+ 3,322lg30 |
10 |
||||
1 |
|
|
||||
При расчете величины интервала целесообразно округлять знаменатель до целого. В противном случае, при построении интервального ряда верхняя граница последнего интервала может не соответствовать максимальному значению признака в исходной совокупности.
Учитывая, что минимальное значение признака 17, образуем первый интервал, прибавив к минимальному значению величину интервала 10, то есть нижняя граница первого интервала 17, а верхняя 27, второй интервал соответственно 27–37 и т.д. Таким образом, получим интервалы 17–27, 27–37, 37–47, 47–57, 57–67, 67–77.
Ранжируем исходные данные: 17,18,20,21,22,24,27,29,30,31,33,34,36,39,40, 40,41,44,45,47,47,51,55,55,56,64,67,70,72,77
Подсчитаем частоты. При подсчете возникает ситуация, в которой вариант (например 27) попадает на границу интервалов и может быть отнесен как к более раннему интервалу, так и к следующему за ним. В этом случае следует отнести его к интервалу, на
59
верхней границе которого он находится. Таким образом, 27 относится к первому интервалу. Результаты построения интервального вариационного ряда запишем в виде таблицы:
Распределение специалистов коммерческих банков по величине заработной платы
Величина заработной платы специалистов |
Число специалистов, чел. |
коммерческих банков, тыс. руб. |
|
17–27 |
7 |
27–37 |
6 |
37–47 |
8 |
47–57 |
4 |
57–67 |
2 |
67–77 |
3 |
Итого |
30 |
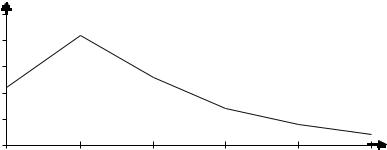
Вариационный ряд можно изобразить графически. Дискретный вариационный ряд можно изобразить в виде полигона распределения. Полигон распределения строится в прямоугольной системе координат, при этом, на оси абсцисс откладывают значения вариант, а на оси ординат частоты или частости. Полученные точки соединяют отрезками, в результате чего получается ломаная линия, которая и будет полигоном распределения. Построим полигон распределения по данным примера 3.2.
|
25 |
|
|
|
|
|
|
20 |
|
|
|
|
|
семей |
15 |
|
|
|
|
|
|
|
|
|
|
|
|
число |
10 |
|
|
|
|
|
5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
0 |
1 |
2 |
3 |
4 |
5 |
|
|
|
количество детей |
|
|
|
Рис. 3.1. Полигон распределения
60