

6.2. Экспоненциальное сглаживание
Предположим,
что модель временного ряда имеет вид:
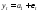 ,
где
,
где ;
;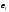 — случайные неавтокоррелированные
отклонения с нулевым математическим
ожиданием и дисперсией
— случайные неавтокоррелированные
отклонения с нулевым математическим
ожиданием и дисперсией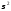 .
.
Для экспоненциального сглаживания ряда используется рекуррентная формула
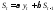 ,
(6.1)
,
(6.1)
где St — значение экспоненциальной средней в моментt;
α — параметр сглаживания, α = сonst, 0 < α < 1; β = 1 – α.
Если последовательно использовать эту рекуррентную формулу, то экспоненциальную среднюю St можно выразить через предшествующие значения уровней временного ряда.
При
n → ∞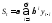 . Таким образом, величинаSt
оказывается взвешенной суммой
всех членов ряда.
. Таким образом, величинаSt
оказывается взвешенной суммой
всех членов ряда.
Причем веса отдельных уровней ряда убывают по мере их удаления в прошлое соответственно экспоненциальной функции (в зависимости от «возраста» наблюдений). Именно поэтому величина St названа экспоненциальной средней.
Например, пусть α = 0,3. Тогда вес текущего наблюдения yt будет равен α = 0,3, вес предыдущего уровняyt–1 будет соответствовать α × β = 0,3 × 0,7 = 0,21; для уровняyt–2 вес составит α × β2 = 0,147; дляyt–3 – α × β3 = 0,1029 и т.д.
При высоком значении α дисперсия экспоненциальной средней незначительно отличается от дисперсии ряда. С уменьшением α дисперсия экспоненциальной средней сокращается, возрастает ее отличие от дисперсии ряда. Тем самым, экспоненциальная средняя начинает играть роль «фильтра», поглощающего колебания временного ряда.
Таким образом, с одной стороны, следует увеличивать вес более свежих наблюдений, что может быть достигнуто повышением α, с другой стороны, для сглаживания случайных отклонений величину α нужно уменьшить. Эти два требования находятся в противоречии. Поиск компромиссного значения параметра сглаживания α составляет задачу оптимизации модели.
Автор
метода простого экспоненциального
сглаживания Р.Г. Браун предложил следующую
формулу расчета α: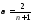 ,
,
где n — число уровней временного ряда, вошедших в интервал сглаживания.
Пределы изменения α установлены эмпирическим путем и изменяются в пределах:
0,1 ≤ α ≤ 0,3.
Однако, следует учитывать, что в этом случае параметр α полностью зависит от числа наблюденийn.
Часто на практике при решении конкретных задач параметр α применяется равным: α = 0,1; 0,15; 0,2; 0,25; 0,3.
Иногда поиск этого значения параметра осуществляется путем перебора. В этом случае в качестве оптимального выбирается то значение α, при котором получена наименьшая дисперсия ошибки.
При расчете экспоненциальной средней в момент времени t всегда требуется значение экспоненциальной средней в предыдущий момент времени, поэтому на первом шаге должно быть определено некоторое значениеS0 , предшествующееS1. Часто на практике в качестве начального значенияS0 используется среднее арифметическое значение из всех имеющихся уровней временного ряда или из какой-то их части. Вес, приписываемый этому значению, уменьшается по экспоненциальной зависимости по мере удаления от первого уровня. Поэтому для длинных временных рядов влияние неудачного выбораS0 погашается.
При использовании экспоненциальной средней для краткосрочного прогнозирования предполагается, что модель ряда имеет вид:
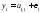 ,
,
где
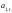 — варьирующий во времени средний
уровень ряда.
— варьирующий во времени средний
уровень ряда.
Прогнозная модель определяется равенством:
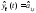 ,
,
где
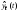 — прогноз, сделанный в моментt
на τ
единиц времени
(шагов) вперед;
— прогноз, сделанный в моментt
на τ
единиц времени
(шагов) вперед;
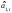 —оценка
—оценка
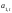 ,
,
Единственный
параметр модели
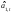 определяется
экспоненциальной средней:
определяется
экспоненциальной средней: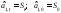 .
.
Выражение (6.1.) можно представить по-другому, перегруппировав члены:
 .
.
Величину (yt – St–1) можно рассматривать как погрешность прогноза. Тогда новый прогноз St получается в результате корректировки предыдущего прогноза с учетом его ошибки. В этом и состоит адаптация модели.
Экспоненциальное сглаживание является примером простейшей самообучающейся модели. Вычисления чрезвычайно просты, выполняются итеративно, причем массив прошлой информации уменьшен до единственного значения St–1.
Пример 6.1. Рассчитайте экспоненциальную среднюю для временного ряда индекса потребительских цен в Кемеровской области (таблица 6.1). В качестве начального значения экспоненциальной средней возьмите среднее значение из 5 первых уровней ряда. Расчеты проведите для двух различных значений параметров адаптации α:
α = 0,1; α = 0,5.
Таблица 6.1.