

Распределение знаков отклонений
|
виды тенденции |
Длина благоприятной тенденции, τ |
Частота, f |
|
-- |
0 |
|
|
-+- |
1 |
|
|
-++- |
2 |
|
|
-+++- |
3 |
|
|
… |
… |
|
При этом две первые графы таблицы: вид тенденции и длина благоприятной тенденции существуют априори, и исследователь только частотой определяет наличие того или иного вида тенденции в исследуемом временном ряду.
Длина же благоприятной тенденции (τ) определяется числом плюсов между двумя минусами в ряду динамики «+» и «-».
3. На основе данных таблицы определяется средняя длина благоприятной тенденции по формуле вида:
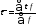 ,
,
где: τ — длина благоприятной тенденции;
f — частота повторения благоприятной тенденции.
Средняя длина благоприятной тенденции показывает, сколько в среднем в рассматриваемом временном ряду, наблюдалось совершение благоприятной тенденции.
На основе полученной средней длины благоприятной тенденции τ определяется показатель, характеризующий интенсивность прерываний этой благоприятной тенденции (λ), который определяется по формуле:
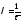 .
.
Данный показатель характеризует, сколько в среднем раз за рассматриваемый период времени, совершалось прерывание благоприятной тенденции.
Вероятность благоприятной тенденции определяется на основе следующей модификации закона распределения Пуассона:
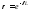 ,
,
где: р — вероятность совершения благоприятной тенденции;
λ — интенсивность прерываний благоприятной тенденции;
L — период упреждения (число лет сохранения благоприятной тенденции).
Пример 7.1.
Построить прогноз по ряду динамики урожайности картофеля Кемеровской области на основе распределения Пуассона (таблица 7.2).
Таблица 7.2.
Расчетная таблица для определения знаков отклонений
|
Год |
Урожайность картофеля |
Знаки отклонений |
|
2000 |
135 |
- |
|
2001 |
135 |
- |
|
2002 |
134 |
- |
|
2003 |
120 |
- |
|
2004 |
122 |
+ |
|
2005 |
106 |
- |
|
2006 |
116 |
+ |
|
2007 |
113 |
- |
|
2008 |
139 |
+ |
|
2009 |
140 |
+ |
|
2010 |
145 |
+ |
|
2011 |
153 |
+ |
Построенный по этим данным ряд распределения знаков отклонений имеет вид (таблица 7.3.):
Таблица 7.3.
Распределение знаков отклонений
|
виды тенденции |
Длина благоприятной тенденции, τ |
Частота, f |
|
-- |
0 |
3 |
|
-+- |
1 |
2 |
|
-++++ |
4 |
1 |
На
основе данных таблицы 7.3 определяется
средняя длина благоприятной тенденции:
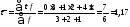 .
.
Интенсивность
прерываний благоприятной тенденции
(λ) составила:
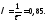
Таким
образом, вероятность благоприятной
тенденции в 2012 году составит:
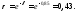 Таким образом, с вероятностью 43% можно
утверждать, что урожайность картофеля
в 2012 году возрастет по сравнению с 2011
годом.
Таким образом, с вероятностью 43% можно
утверждать, что урожайность картофеля
в 2012 году возрастет по сравнению с 2011
годом.
8. Метод экспертных оценок
8.1. Методы и модели экспертных оценок
При решении многих практических задач часто оказывается, что факторы определяющие конечные результаты, не поддаются непосредственному измерению. В этих случаях применяется процедура ранжирования.
Под ранжированием будем понимать процедуру расположения факторов аi (i=1, 2,…,n) в порядке их существенности: на первом месте стоит самый существенный, следом за ним менее существенный, но самый важный из оставшихся, и т.д. Это означает, что каждому фактору аi следует поставить в соответствие некоторое целое число хi – его ранг. Составить ранжированную последовательность можно с помощью специалистов – экспертов.
Если эксперт не в состоянии указать порядок следования для двух или нескольких объектов, либо он присваивает разным объектам один и тот же ранг. То в таком случае, объектам приписывают стандартизированные ранги. Стандартизированный ранг равен среднему значению от суммы мест объектов с одинаковыми рангами деленной на натуральное число, которым выражен ранг.
Когда
ранжирование производится несколькими
экспертами, то результаты опроса m
экспертов относительно n
факторов сводятся в матрицу размерности
 ,
которая называется матрицей опроса
(табл. 8.1). Здесьxij
– ранг j-го
фактора, данный i-м
экспертом.
,
которая называется матрицей опроса
(табл. 8.1). Здесьxij
– ранг j-го
фактора, данный i-м
экспертом.
Затем, при обработке матриц опроса переходят к преобразованным рангам по формуле:
 . (8.1)
. (8.1)
Таблица 8.1