

9.3 Мова програмування Асемблер-86
Вхідний контроль:
Що входить до поняття архітектура мікропроцесорів?
В чому полягає різниця між мовами програмування високого і низького рівнів?
Як можуть будуть подані дробові числа у обчислювальній системі?
У яких кодах подаються числа зі знаком у обчислювальній системі?
Наведить регістрову модель 16-розрядного МП фірми Intel.
Які сегменти існують у пам’яті МПС, побудованної на МП фірми Intel?
Які способи адресування операндів МП фірми Intel Ви знаєте?
Що називається стеком і як його організовано?
Кожна мікропроцесорна система має свою власну мову програмування – мову машинних команд (машинну мову) і функціонувати може безпосередньо лише під керуванням програми, яка написана на цій мові. Машинна мова є сукупністю двійкових кодів всіх операцій, котрі може виконувати певний процесор. Машинна мова є незручною для широкого використання, тому що потребує досить великих витрат часу для написання і налагодження таких програм. Більш широке розповсюдження находять мови програмування, які не співпадають з машинною мовою і є зручнішими за неї при використанні. Усі мови програмування можливо розподілити на дві групи: мови високого і низького рівня (машинно-орієнтовані мови), що відображує ступінь близькості цих мов до машинної.
Мова Ассемблер – це машинно-орієнтована мова, яка дозволяє використовувати усі структурні особливості мікропроцесорної системи, що пов’язані з апаратними можливостями, набором машинних команд, складом периферійного обладнання тощо. Мова Асемблер – це символічне представлення машинної команди у вигляді її мнемонічного зображення. Програмування на асемблері вимагає знання способів подання і обробки даних на рівні машинних команд, що забезпечується знанням різних систем числення та архітектури МПС. Мова Асемблер поєднує у собі переваги машинної мови і деякі особливості мов високого рівня. Асемблер є найбільш ефективною мовою програмування при розв’язанні задач розробки системного програмного забезпечення, розробки програм для обміну даними з нестандартним периферійним обладнанням (драйвери), програмуванням систем реального часу для керування технологічними процесами і обладнанням, забезпечення роботи інформаційно-обчислювальних систем та ефективного використання можливостей (робота у захищеному режимі) і ресурсів МПС.
Мова Асемблер мікропроцесорів фірми Intel є досить розвинутою і гнучкою. До складу мови Асемблер-86 входять більше 100 базових команд, відповідно до яких генерується понад 3800 машинних команд; близько 20 директив, призначених для розподілення пам’яті, ініціалізації змінних, умовного асемблювання тощо. Також у ній передбачено використання засобів структурування даних, що є характерним для мов програмування високого рівня.
Всі команди мови Асемблер можливо розподілити по групах, відповідно їх функціональному призначенню: пересилання даних, арифметичні операції, логічні операції і зсуви, передачі керування, обробки рядків даних і команди керування станом центрального процесора.
Сукупність команд і директив, що представляють текст програми, називаються початковим модулем. Початкові модулі створюються за допомогою текстового редактора і можуть зберігатися на будь-якому носії, у вигляді початкового файлу. Цей файл може мати будь-яку назву і розширення .asm. Асемблер перетворює початковий модуль у об’єктний модуль. Ця операція називається трансляцією, а програма, яка її виконує – транслятором. На етапі створення об’єктного модуля виконується перетворення команд асемблера на машинні команди. У результаті роботи транслятора створюються: об’єктний модуль – файл, який має розширення .obj, файл лістингу, який має розширення .lst і файл перехрестних посилань з розширенням .crf. Файл лістингу вміщує код асемблера початкової програми, для кожної команди якої вказано машинний код і зміщення у кодовому сегменті, крім того до цього файлу входять таблиці з інформацією про мітки і сегменти, які використовуються у програмі і повідомлення про синтаксичні помилки. Імена файлів призначає програміст, вони можуть співпадати, а можуть бути різними.
Після створення об’єктного модуля він оброблюється за допомогою програми – укладача, яка генерує завантажувальний модуль. Це файл, який має розширення .exe і який може виконуватися МПС. Програма-укладач в завантажувальному модулі об’єднує об’єктні модулі, що входять в програму і підключає, при необхідності, бібліотечні модулі і замінює відносні адреси комірок пам’яті на абсолютні, з урахуванням області пам’яті, у яку модуль буде завантажено для виконання. Бібліотечні модулі – це об’єктні файли, які містять найбільш поширені програми. Ім’я завантажувального модуля також призначає програміст. Блок-схему алгоритму підготовки програми на мові Асемблер для її виконання показано на рис. 9.8.
Текст програми на мові Асемблер складається з операторів (речень) чотирьох типів:
команди, які є символічними аналогами машиних команд МПС;
макрокоманди – конструкції, які при трансляції програми замінюються на послідовність відповідних команд;
директиви – інструкції транслятору по виконанню певних дій;
коментарі – пояснення по виконанню команди або фрагмента програми, використовуються для документування і кращого розуміння змісту програми; коментар ігнорується асемблером, тому він може бути написаний на будь-якій мові, і відокремлюється символом ; від іншої частини речення.
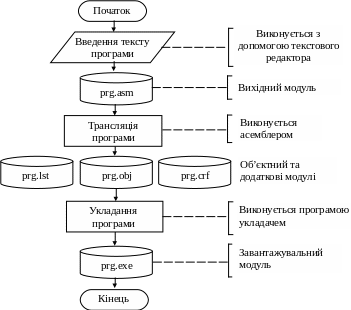
Рисунок 9.8 – Блок-схема підготовки програми для її виконання
Довжина речення становить 131 символ, усі інші ігноруються. Речення повинно розташовуватися у межах одного рядка, переносити речення на інший рядок не дозволяється. Речення асемблера формуються із найпростіших конструкцій мови – лексем, синтаксично нероздільних послідовностей допустимих символів алфавіту асемблера, які мають значення для транслятора. У якості символів алфавіту асемблера використовуються:
усі літери латинського алфавіту, при цьому заголовні та прописні літери є еквівлентні;
цифри від 0 до 9;
спеціальні і розподілювальні символи, до яких відносяться: ?, @, $, _, &, [ ], ( ), < >, { }, +, –, /, *, %, !, “ “, \, =, #,^ і деяки недруковані символи.
До лексем відносяться: ідентифікатори, рядки символів, цілі числа двійкової, шістнадцяткової або десяткової систем числення.
Ідентифікатор – це послідовність символів, яка визначена програмістом і використовується для іменування об’єктів програми (міток , змінних , назв операцій тощо). Ідентифікатор може складатися з одного або кількох символів, але починатися може лише літерою. Крапка може бути лише першим символом ідентифікатора. Інші спеціальні символи використовувати у ідентифікаторах не дозволяється. Довжина ідентифікатора становить до 255 символів, але транслятор сприймає лише 32 перших символа, інші ігноруються.
Ідентифікатори розділяються на службові слова і імена. До службових слів відносяться ідентифікатори, значення яких однозначно визначено (назви регістров, команд і таке інше). Імена – це символічні назви, які користувач призначає певним об’єктам програми (змінним, коміркам пам’яті тощо).
Рядком символів може бути будь-яка послідовність символів, в якості яких можливо використовувати літери і спеціальні символи, окрім символа повернення каретки та перенесення рядка. Рядок символів обов’язково брати у лапки.
Так як мікропроцесор може працювати з різними сегментами, то для завантаження і роботи програми необхідно задати сегменти і особливості їх використання. Це робиться за допомогою директиви SEGMENT, яка має вигляд:
{Ім’я сегменту} |
SEGMENT |
{Тип вирівнювання} |
{Тип комбінування} |
{Клас сегменту} |
{Тип розміру} |
Програма |
{Ім’я сегмента} |
END |
Розглянемо окремі поля цієї директиви.
Тип вирівнювання – повідомлення програмі-укладачу про адресу початку сегменту. При правильному розміщенні програма виконується швидше. Можливі значення:
BYTE – вирівнювання не виконується. Початкова адреса сегменту може бути будь-якою;
WORD – сегмент починається з адреси, яка є кратна 2, при цьому молодший значний біт фізичної адреси дорівнює 0. Виконується вирівнювання по межі слова;
DWORD – сегмент починається з адреси, яка є кратна 4. Виконується вирівнювання по межі подвійного слова;
PARA – сегмент починається з адреси, яка є кратна 16, при цьому остання шістнадцяткова цифра фізичної адреси дорівнює 0Н. Виконується вирівнювання по межі параграфа;
PAGE – сегмент починається з адреси, яка є кратна 256. Виконується вирівнювання по межі сторінки;
MEMPAGE – сегмент починається з адреси, яка є кратна 4 кбайт.
За умовчанням тип вирівнювання має значення PARA.
Тип комбінування — повідомлення програмі-укладачу про об’єднання при виконанні сегментів різних модулів програми, які мають однакові імена. Можливі значення:
PRIVATE – сегмент не об’єднується з іншими сегментами;
PUBLIC – об’єднуються усі сегменти з однаковими іменами. Сегмент, що отримаємо, буде цілий і безперервний, а усі адреси будуть формуватися від його початку;
COMMON – усі сегменти з однаковими іменами розміщуються за однією адресою. Таким чином, усі сегменти будуть перекриватися і сумісно використовувати пам’ять;
AT xxxx – розміщує сегмент за абсолютною адресою параграфа, адреса котрого задається виразом хххх.
STACK – визначення сегмента стека. Усі сегменти, що мають однакові імена, об’єднуються таким чином, що їх адреси розраховуються відносно вмісту регістра SS
Клас сегмента – повідомлення про відповідний порядок включення сегментів при складанні програми з сегментів різних модулів. Програма-укладач з’єднує усі сегменти, що мають однаковий клас. Рекомендується об’єднувати сегменти з однаковим функціональним призначенням (наприклад, сегменти коду програми) Клас сегмента – це рядок, який береться у лапки, наприклад, сегмент коду «CODE».
Тип розміру сегмента – задає розмір сегмента і порядок формування фізичної адреси в ньому, тому що дані можуть бути 16- або 32-розрядними. Може приймати такі значення:
USE16 – формування фізичної адреси у такому сегменті виконується тільки з 16-розрядним зміщенням. Розмір такого сегмента 64 кбайт.
USE32 – формування фізичної адреси у такому сегменті виконується тільки з 32-розрядним зміщенням. Розмір такого сегмента 4 Гбайт.
Для призначення сегментам конкретного функціонального призначення і закріплення їх за сегментними регістрами використовується директива ASSUME, яка має вид:
-
ASSUME
Назва сегментного регістра;
Ім’я сегмента
Для простих програм, що мають по одному сегменту для коду, даних і стека, у найбільш поширених трансляторах TASM i MASM для спрощення директив сегментування введено директиву вказівки моделі пам’яті MODEL, котра частково керує розміщенням сегментів. Ця директива зв’язує сегменти, які при використанні спрощених директив сегментування мають наперед визначені імена з сегментними регістрами. Обов’язковим параметром цієї директиви є модель пам’яті. У табл. 9.1 наведено назви і значення параметрів директиви MODEL.
У цій таблиці поняття near і far характеризують віддаленість об’єкту від місця використання. Якщо об’єкт розташовано у сегменті разом з кодом і звернутися до нього можливо за допомогою двобайтового зміщення, то це відповідає типу near (близький перехід). При цьому команда модифікує лише вміст вказівника команд ІР. В іншому випадку об’єкт розміщується у іншому сегменті (тип far) і для звернення до нього необхідно надати чотирьохбайтний вказівник – сегмент:зміщення. При цьому буде модифіковано вміст двох регістрів.
Таблиця 9.1 – Назви і параметри моделей пам’яті
Модель |
Тип коду |
Тип даних |
Призначення моделі |
TINY |
near |
near |
Код і дані поєднано в одну групу з ім’ям DGROUP. Використовується для створення програм з розширенням .com |
SMALL |
near |
near |
Код займає один сегмент, дані об’єднано у одну группу з ім’ям DGROUP. Ця модель, звичайно, використовується для створення програм на ассемблері. |
MEDIUM |
far |
near |
Код займає декілька сегментів, по одному на кожен програмний модуль, що об’єднується. Усі посилання на передачу керування – типу far. Дані поєднано у одній групі. Усі посилання на них – типу near. |
COMPACT |
near |
far |
Код знаходиться у одному сегменті. Дані можуть бути у різних сегментах. Посилання на них типу far. |
LARGE |
far |
far |
Код займає декілька сегментів, по одному на кожен програмний модуль, що об’єднується. Усі посилання типу – far. |
Опис простих типів даних. Для правильного опису і обробки даних їх необхідно описати, для чого використовуються спеціальні директиви резервування і ініціалізації даних, котрі є вказівками транслятору на виділення певного обсягу пам’яті для розміщення даних певної довжини. Ці директиви мають вид:
db – резервування пам’яті для даних довжиною 1 байт;
dw – резервування пам’яті для даних довжиною 2 байта;
dd – резервування пам’яті для даних довжиною 4 байта;
df – резервування пам’яті для даних довжиною 6 байт;
dq – резервування пам’яті для даних довжиною 8 байт;
dt – резервування пам’яті для даних довжиною 10 байт.
Нижче приведено приклад використання директив для керування програмою на мові Асемблер.
MODEL SMALL ; тип моделі пам’яті, що буде
; використовуваться
STACK 256 ; визначення сегмента стека
DATA SEGMENT ; визначення сегмента даних
DATA ENDS
CODE SEGMENT ; Визначення сегмента коду
ASSUME CS:CODE, DS:DATA, ES:DATA ; Закріплення сегментних
; регістрів
Програма
CODE ENDS ; кінець коду програми
END ; закінчення
Контрольні запитання:
Які особливості мови Асемблер забезпечують її використання?
Які файли формуються у результаті роботи програми – транслятора?
Чому виконання асемблерної програми можливо лише після роботи програми – укладача?
Які файли використовує програма – укладач для формування завантажувального модуля?
Які оператори (речення) можуть входити до тексту програми на асемблері?
Які моделі пам’яті Ви знаєте? Чим відрізняються поняття near і far?
Які директиви використовуються для опису простих типів даних?