

2.4.2. Модифицированный имитационным моделированием метод экспоненциального сглаживания
Для прогнозирования характеристик образцов техники, математическое описание которых имеет вид
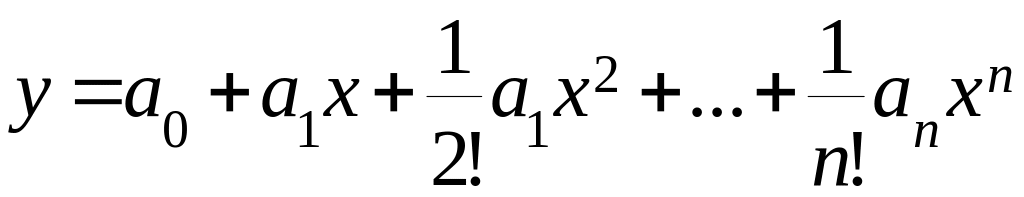 , (2.4.10)
, (2.4.10)
целесообразно применять метод экспоненциального сглаживания. Сложившаяся практика использования этого метода предполагает ограничение числа членов ряда Тейлора
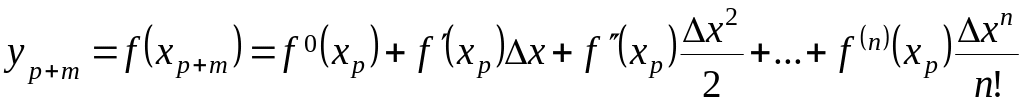 ,
,
(2.4.11)
аппроксимирующего
выражение (2.4.10), несколькими
членами
![]() .
.
В зависимости (2.4.11)
![]() –
-тая
производная функции по переменной в
точке
–
-тая
производная функции по переменной в
точке
![]() ;
;
![]() ;
;
![]() – число наблюдений;
– число наблюдений;
– значение величины шага упреждения.
Для условий, когда ошибки прогнозирования не удовлетворяют заданным требованиям, можно осуществить анализ их источников. Известно [4], что точность прогнозной задачи можно определить по зависимости
![]() (2.4.12)
(2.4.12)
где 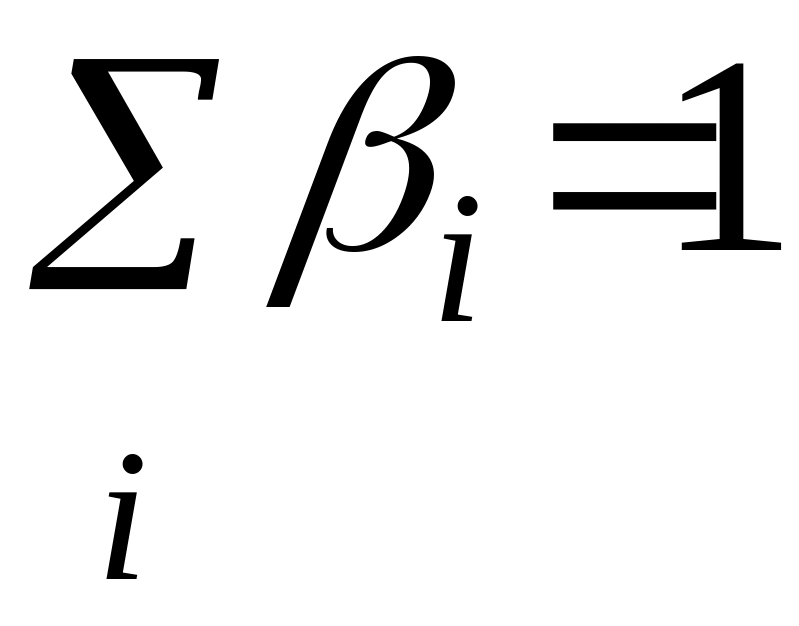 ;
;
![]() – погрешность,
обусловленная приближенностью исходной
информации;
– погрешность,
обусловленная приближенностью исходной
информации;
![]() – погрешность, связанная с методом
прогнозирования;
– погрешность, связанная с методом
прогнозирования;
![]() – погрешность,
вызванная неточностью вычислений;
– погрешность,
вызванная неточностью вычислений;
![]() – нерегулярная
погрешность, обусловленная вероятностью
непредсказуемых в настоящее время
событий, влияющих на характер изменения
прогнозируемой величины.
– нерегулярная
погрешность, обусловленная вероятностью
непредсказуемых в настоящее время
событий, влияющих на характер изменения
прогнозируемой величины.
Одной из наиболее
весомых является методическая ошибка,
зависящая от числа членов разложения.
В работах [1], [2] приводятся аналитические
зависимости для выполнения параметров
аппроксимирующего многочлена при
![]() .
Вывод таких зависимостей для
.
Вывод таких зависимостей для
![]() .
представляет значительные трудности.
Кроме того, любое увеличение числа
членов выражения (2.4.11) влечет за собой
потребность увеличения объема исходных
данных, необходимых для определения
оценок начальных значений коэффициентов
.
представляет значительные трудности.
Кроме того, любое увеличение числа
членов выражения (2.4.11) влечет за собой
потребность увеличения объема исходных
данных, необходимых для определения
оценок начальных значений коэффициентов
![]() (методом наименьших квадратов или в
более общем случае методом максимального
правдоподобия), далее предлагается
модификация метода экспоненциального
сглаживания, основанная на принципах
группового учета аргументов. Сущность
метода заключается в том, что математическая
модель объекта прогнозирования
(методом наименьших квадратов или в
более общем случае методом максимального
правдоподобия), далее предлагается
модификация метода экспоненциального
сглаживания, основанная на принципах
группового учета аргументов. Сущность
метода заключается в том, что математическая
модель объекта прогнозирования
![]() ,
,
называемая в соответствии с терминологией работы [1] его «полным описанием», заменяется набором «частных описаний» вида
![]() .
.
По принятому
критерию, значение которого вычисляется
для каждого «частного описания», из
множества
![]() отбирается некоторое число, называемое
«свободой выбора», наиболее регулярных
описаний, образующих подмножество
отбирается некоторое число, называемое
«свободой выбора», наиболее регулярных
описаний, образующих подмножество
![]() .
Вычисленные значения промежуточных
аргументов
.
Вычисленные значения промежуточных
аргументов
![]() принимаются в качестве аргументов
«частных описаний» следующего уровня
фильтрации, то есть
принимаются в качестве аргументов
«частных описаний» следующего уровня
фильтрации, то есть
![]()
Аналогичная
процедура повторяется до тех пор, пока
величина критерия фильтрации уменьшается
или увеличивается в зависимости от
его содержания (при этом исходная
информация делится на две выборки:
обучающую и проверочную). Для практических
расчетов в качестве такого критерия
рекомендуется принимать среднеквадратическую
ошибку аппроксимации модели на проверочной
выборке, которая, как установлено в
работе [10], при увеличении числа уровней
фильтрации, а, следовательно, сложности
модели, достигает экстремального
значения. Сложность модели (измеряется
числом ее членов), соответствующая
экстремальному значению критерия,
является оптимальной. На последнем
уровне фильтрации фиксируется «частное
описание», значение которого минимально.
На предпоследнем уровне выбираются
«частные описания», являющиеся аргументами
последнего уровня, и т. д. Так как «частные
описания» являются функцией двух
аргументов, их коэффициенты легко
определяются по небольшому количеству
исходных данных. Исключая промежуточные
переменные
![]() можно получить модель исследуемых
характеристик объекта прогнозирования
в виде аналога «полного описания»
можно получить модель исследуемых
характеристик объекта прогнозирования
в виде аналога «полного описания»
![]() ,
,
где в общем случае
![]() .
.
Как известно,
особые трудности при увеличении числа
членов в разложении Тейлора связаны с
получением аналитических зависимостей
для определения вектора коэффициентов
![]() .
Из работы [2] следует,
.
Из работы [2] следует,
что
![]() ,
,
где ![]() – вектор-столбец размером
– вектор-столбец размером
![]() сглаженных
значений процесса
сглаженных
значений процесса
![]() ;
;
– вектор-столбец
размером
![]() неизвестных коэффициентов
неизвестных коэффициентов
![]() ;
;
– матрица размером
![]() ,
элементы которой, соответствующие
-той
строке и
,
элементы которой, соответствующие
-той
строке и
![]() -му
столбцу, вычисляются по зависимости
-му
столбцу, вычисляются по зависимости
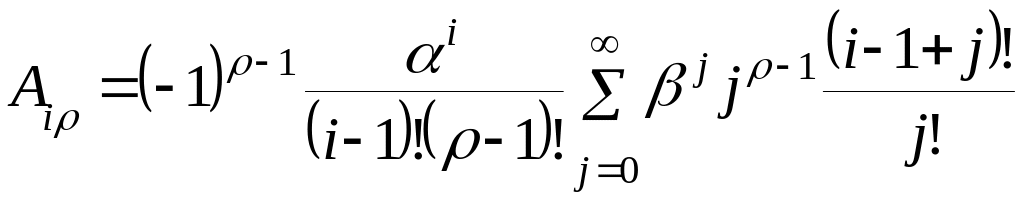 . (2.4.13)
. (2.4.13)
В связи с тем, что
сглаженные значения процесса
![]() могут быть определены по зависимости
могут быть определены по зависимости
![]()
вектор выражается зависимостью
![]() . (2.4.14)
. (2.4.14)
Анализ зависимости (9.33) показывает, что наибольшую сложность вызывает вычисление суммы бесконечного ряда, представляющего собой произведение степеней показательной функции и отношения факториалов, которое можно упростить путем несложных преобразований:
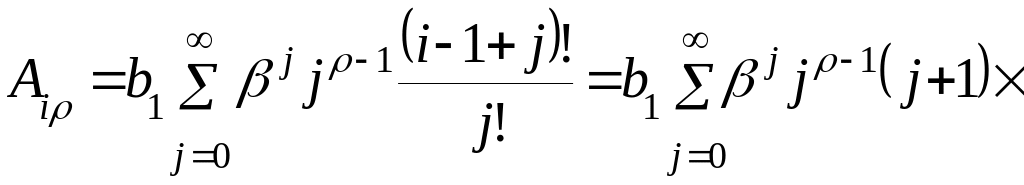
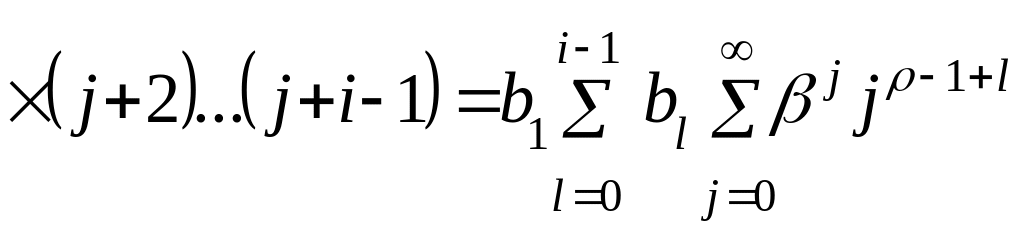 ,
(2.4.15)
,
(2.4.15)
где 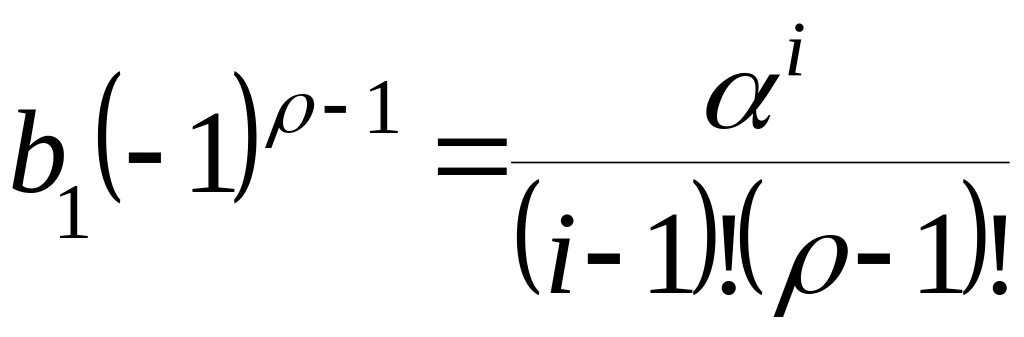 ;
;
![]() – коэффициенты многочлена с переменной
– коэффициенты многочлена с переменной
![]() .
.
С учетом, что при
![]() ряд (2.4.15) вырождается в бесконечно
убывающую геометрическую прогрессию
со знаменателем
ряд (2.4.15) вырождается в бесконечно
убывающую геометрическую прогрессию
со знаменателем
![]() ,
сумма которой равна
,
сумма которой равна
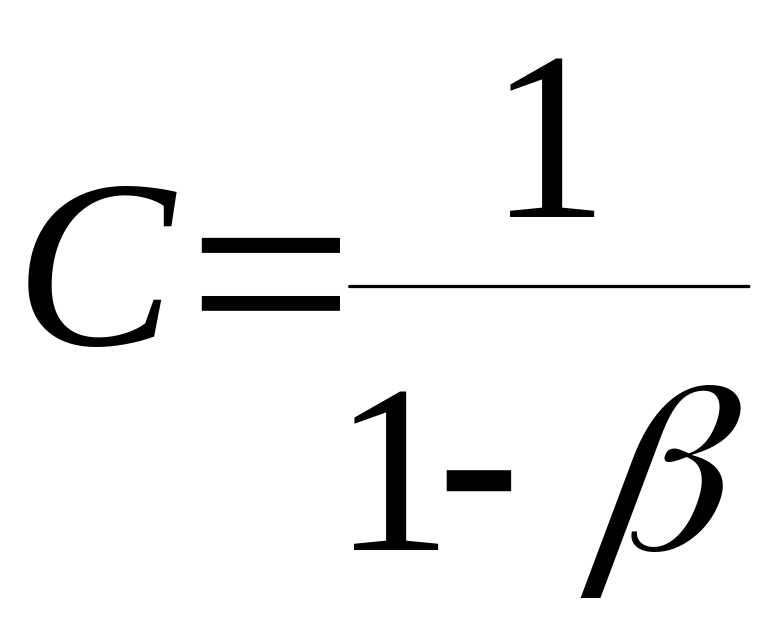 ,
,
сумма любого ряда вида (2.4.15) может быть вычислена по рекуррентной зависимости
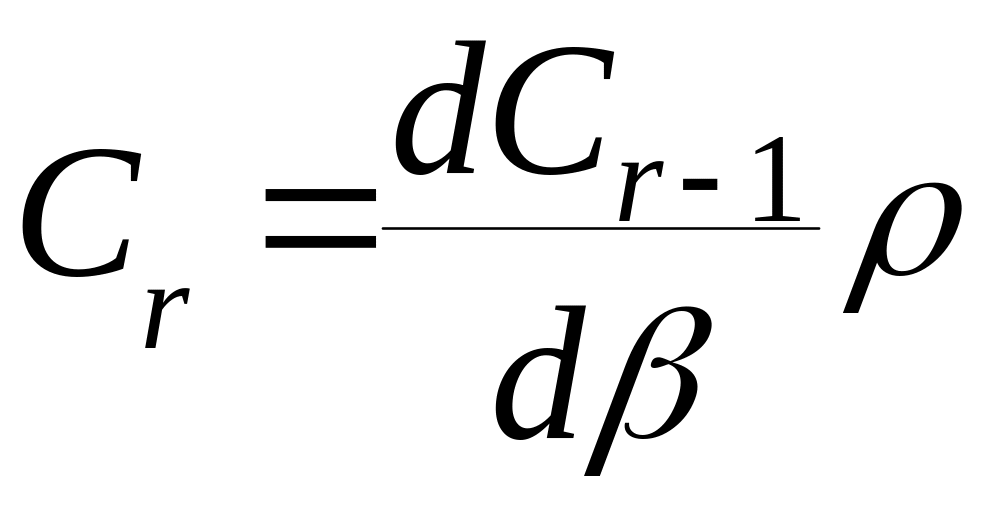 ,
(2.4.16)
,
(2.4.16)
где ![]() .
.
Расчеты по формуле
(2.4.16) при машинной реализации алгоритма
можно осуществлять только численным
дифференцированием, использование
которого нецелесообразно. Поэтому
вычисление элементов матрицы
рекомендуется выполнять на ЭВМ по
зависимости (2.4.13) с заданной точностью
при ограниченном значении
.
Получив, таким образом, элементы матрицы
и вычислив обратную матрицу
![]() ,
вектор коэффициентов
определяется по формуле (2.4.14). Далее, не
нарушая общности рассуждений, заметим,
что в качестве частных описаний
целесообразно использовать зависимость
вида
,
вектор коэффициентов
определяется по формуле (2.4.14). Далее, не
нарушая общности рассуждений, заметим,
что в качестве частных описаний
целесообразно использовать зависимость
вида
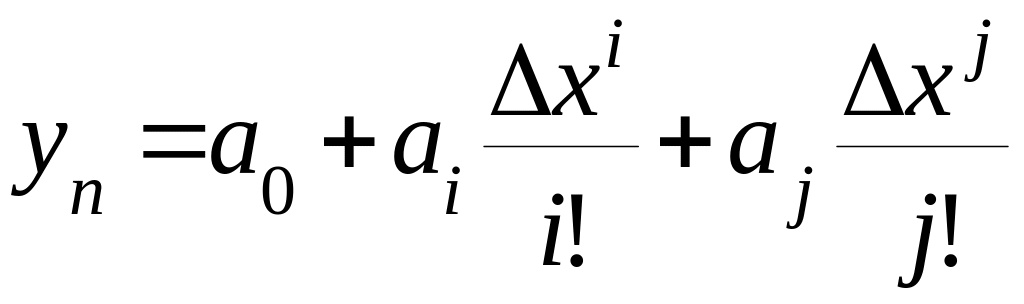 .
.
Блок-схема алгоритма прогнозирования, составленного в соответствии с изложенными положениями, изображена на рис. 2.15.
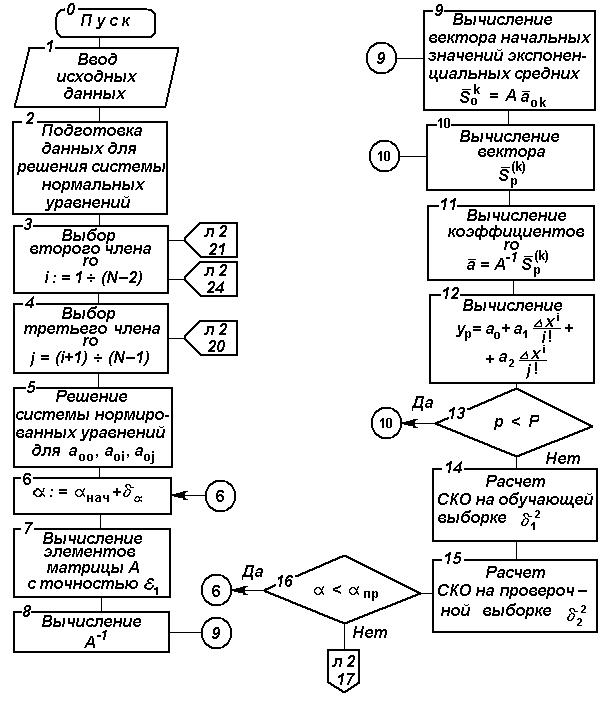
Рис. 2.15. Блок-схема алгоритма прогнозирования по методу модифицированного экспоненциального сглаживания
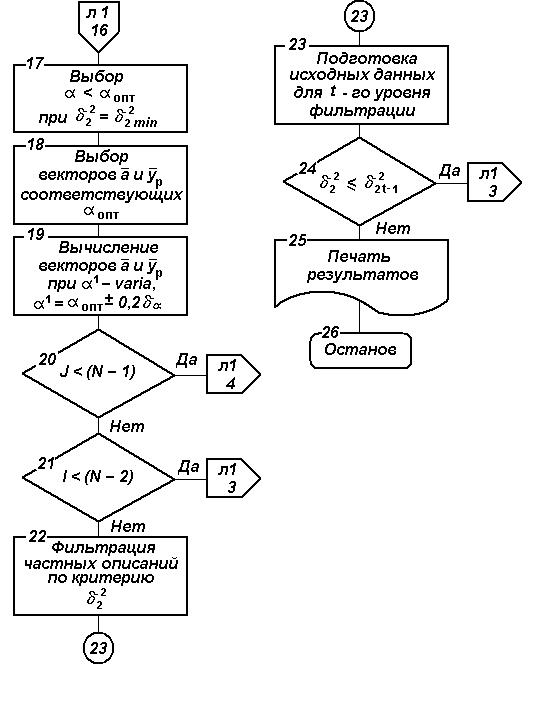
Рис. 2.15. Блок-схема алгоритма прогнозирования по методу
модифицированного экспоненциального сглаживания (продолжение)
Автоматический подбор вида экстраполируемой функции
Методы экстраполяции в прогнозировании основаны на выявлении основной тенденции и проведении на ее базе необходимых расчетов. Поэтому выбор правильной формы связи между фактором-функцией и фактором-аргументом является важным этапом. Для прогнозирования применяются различные формы связи: линейная, параболическая, степенная, показательная и др. Но эти формы имеют жесткую, раз и навсегда заданную структуру. В связи с этим при прогнозировании во многих случаях целесообразно использовать так называемые функции с гибкой структурой (ФГС), форма которой может изменяться и автоматически приспосабливаться к изучаемому процессу. Функция с гибкой структурой характеризует не только зависимость одного фактора от другого, но и собственно тенденцию развития каждого фактора. Заманчивая идея метода автоматического получения вида и параметров аппроксимирующей функции принадлежит Н. К. Куликову. Однако на пути практической реализации метода имеется немало трудностей, например при решении систем трансцендентных уравнений, которые возникают в процессе поиска параметров ФГС или при вычислении соответствующих производных в случае табличного способа задания функции. Очевидно, по мере преодоления трудностей практической реализации функции с гибкой структурой будут занимать все более заметное место в арсенале экстраполяционных методов прогностики. Особую роль в развитии метода следует отвести ЭВМ, что способствует разработке новых эффективных алгоритмов, пригодных для решения задач прогнозирования на основе ФГС. Два частных случая использования ФГС рассматриваются далее.
Известно [1], [2], [3], что любой процесс можно представить в
![]() ,
(2.4.17)
,
(2.4.17)
где ![]() – исходный процесс (функция одного
переменного);
– исходный процесс (функция одного
переменного);
– приближенная модель процесса (описание с помощью ФГС);
![]() – остаток (некоторая
функция точности приближения).
– остаток (некоторая
функция точности приближения).
В наиболее общем виде ФГС для одного аргумента записывается в виде [1], [2]
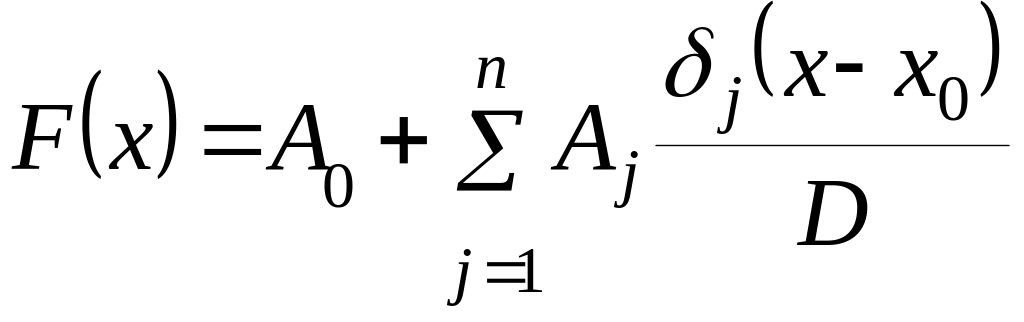 ,
(2.4.18)
,
(2.4.18)
где – некоторое фиксированное натуральное число;
![]() – начальное
значение фактора-аргумента на
рассматриваемом интервале;
– начальное
значение фактора-аргумента на
рассматриваемом интервале;
![]() – постоянные
действительные параметры;
– постоянные
действительные параметры;
![]() – специальный
(степенной) определитель
-того
порядка;
– специальный
(степенной) определитель
-того
порядка;
![]() – функция, получаемая
из определителя заменой строки
на соответствующие функции
– функция, получаемая
из определителя заменой строки
на соответствующие функции
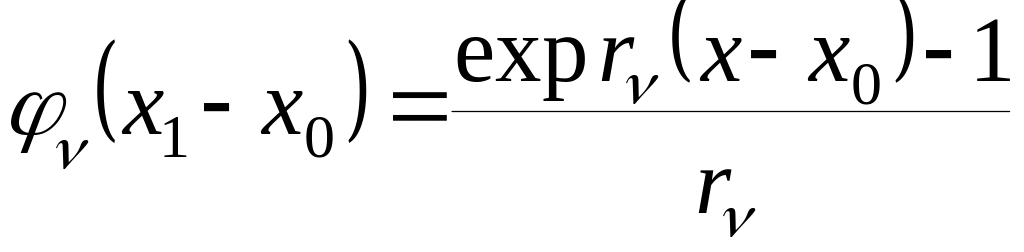 ,
,
![]()
При
![]() функция с гибкой структурой имеет вид
функция с гибкой структурой имеет вид
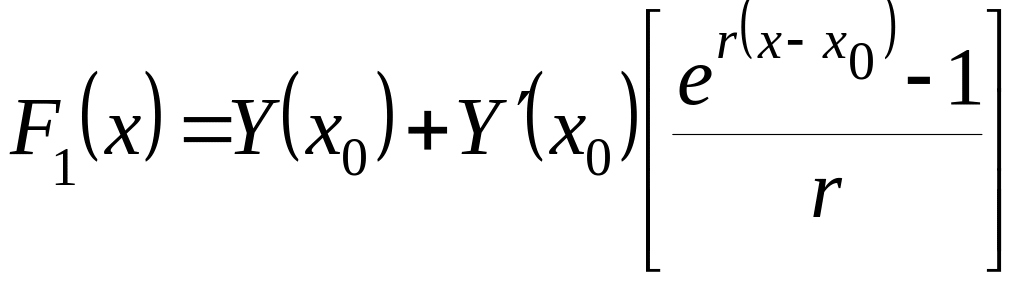 ,
(2.4.19)
,
(2.4.19)
где ![]() – начальное значение функции
– начальное значение функции
![]() и ее производной в точке
и ее производной в точке
![]() ;
;
– корень специального
уравнения
![]() ,
в рассматриваемом случае
,
в рассматриваемом случае
![]() .
.
Нахождение
параметров функции
![]() связано с минимизацией базисной
функции
связано с минимизацией базисной
функции
![]() . (2.4.20)
. (2.4.20)
Далее представляется логичным определить порядок расчета параметров ФГС. В том случае, когда имеется всего один фактор, базисная функция имеет вид
![]() (2.4.21)
(2.4.21)
При
на рассматриваемом отрезке функция
![]() равна нулю, и если проинтегрировать
выражение (2.4.21) для того, чтобы избавиться
от производных, можно получить
равна нулю, и если проинтегрировать
выражение (2.4.21) для того, чтобы избавиться
от производных, можно получить
![]() .
(2.4.22)
.
(2.4.22)
Подставляя в это
уравнение значение начальной точки,
легко установить, что величина первой
производной связана со значением
величины
![]() и
и
![]() соотношением
соотношением
![]() .
(2.4.23)
.
(2.4.23)
Если проинтегрировать уравнение (2.4.22) еще раз, то можно записать выражение вида
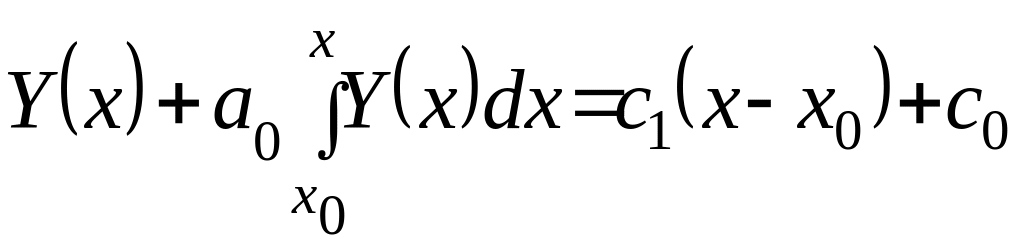 .
(2.4.24)
.
(2.4.24)
При условии, что
,
определяется
![]() .
Тогда уравнение (2.4.24) целесообразно
представить следующей зависимостью:
.
Тогда уравнение (2.4.24) целесообразно
представить следующей зависимостью:
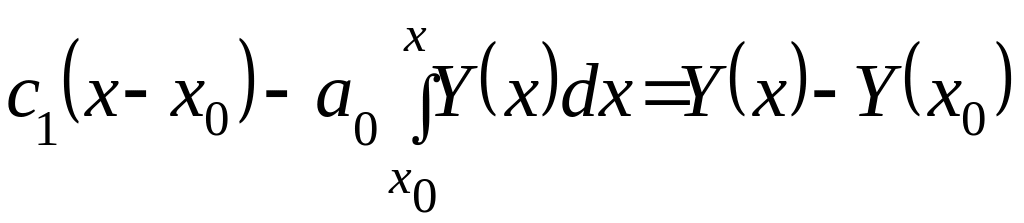 .
(2.4.25)
.
(2.4.25)
Из этого уравнения видно, что оно содержит неизвестные величины. Теперь значение интеграла можно вычислить, так как функция УМ задана таблицей, а для определения и можно образовать систему двух уравнений с двумя неизвестными на основе уравнения (2.4.25). Это нетрудно сделать, если подставить в (2.4.25) значение еще двух точек, взятых из временного ряда. Тогда
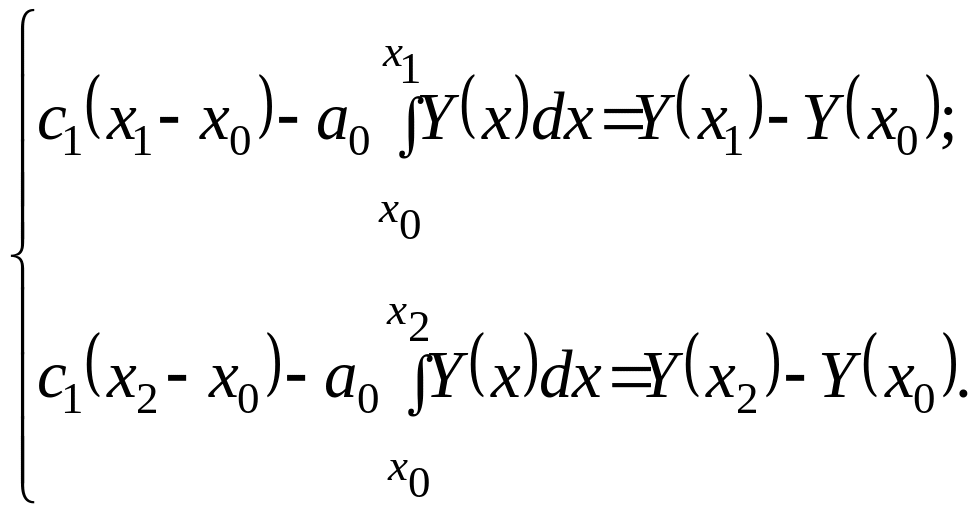 (2.4.26)
(2.4.26)
После вычисления
данных интегралов находятся неизвестные
коэффициенты
и
.
Затем определяется значение первой
производной путем подстановки в
уравнение (2.4.23)
,
и
![]() .
Корень базисного уравнения равен
параметру
со знаком минус. Вычисленные параметры
подставляются в формулу ФГС (2.4.19) для
получения математического выражения
формы связи между
и
.
.
Корень базисного уравнения равен
параметру
со знаком минус. Вычисленные параметры
подставляются в формулу ФГС (2.4.19) для
получения математического выражения
формы связи между
и
.
В качестве примера применения функции с гибкой структурой для прогнозирования в военном деле рассматривается задача по определению вида зависимости между коэффициентом выпуска серийных образцов условных технических систем и объемом задач, выполняемых с помощью данных образцов. Эта зависимость в дальнейшем используется для получения прогноза. Исходные данные представлены в табл. 2.1.
Таблица 2.1
|
0,597 |
0,597 |
0,608 |
0,618 |
0,615 |
0,618 |
0,631 |
|
31,2 |
32,3 |
33,4 |
34,3 |
34,5 |
35,5 |
37,8 |
Из этой таблицы выбираются значения трех опорных точек, одна из которых (начальное значение) должна лежать в середине ряда с тем, чтобы полученная функция одинаково точно приближала данное как в конце, так и в начале ряда. Следовательно,
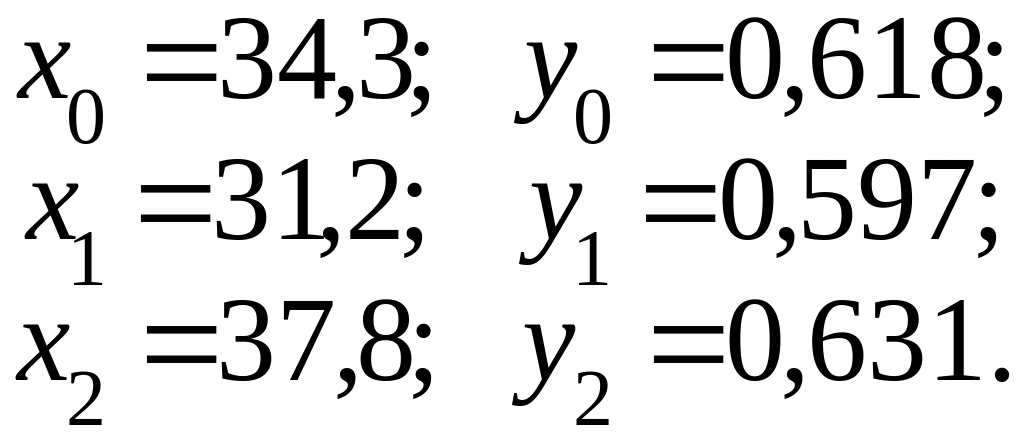
Определяются коэффициенты уравнения (2.4.26):
![]()
Следующий шаг – переход к вычислению необходимых интегралов (рис.2.16).
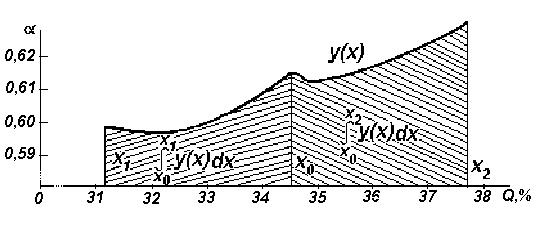
Рис. 2.16. Определение необходимых интегралов для ФГС
Интеграл вида
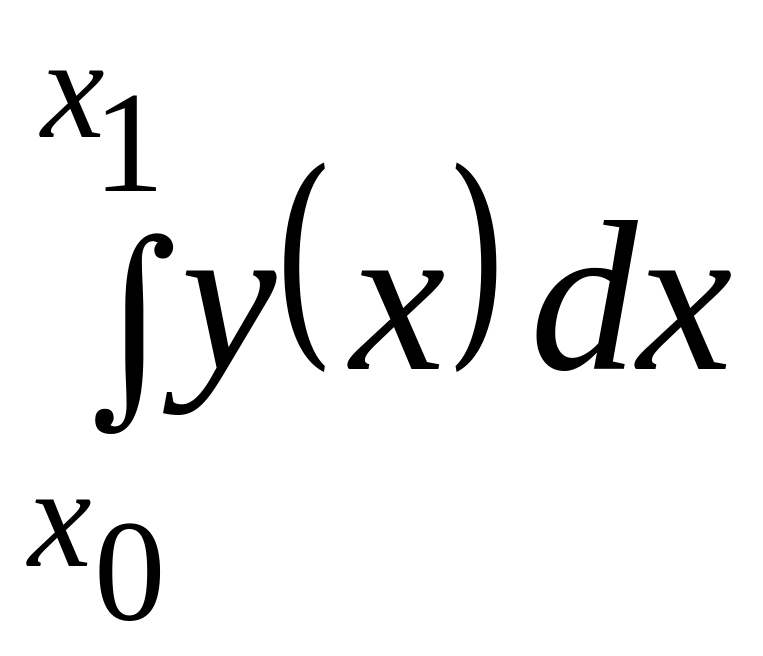 есть
площадь, ограниченная графиком и
значениями
,
равными 34,3 и 31,2. Так как верхний предел
интеграла меньше нижнего, то значение
интеграла отрицательное. Площадь,
ограниченная значениями
равными 34,3 и 31,2, будет складываться из
площадей трех трапеций:
есть
площадь, ограниченная графиком и
значениями
,
равными 34,3 и 31,2. Так как верхний предел
интеграла меньше нижнего, то значение
интеграла отрицательное. Площадь,
ограниченная значениями
равными 34,3 и 31,2, будет складываться из
площадей трех трапеций:
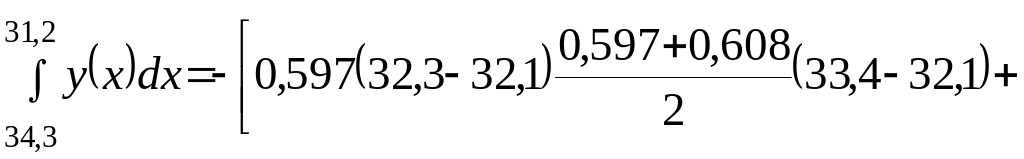

Значение
интеграла
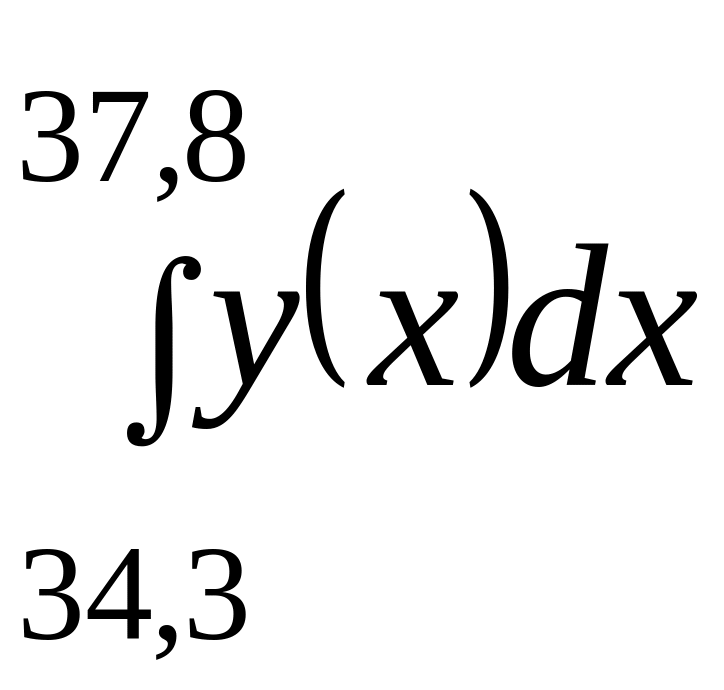 будет
будет
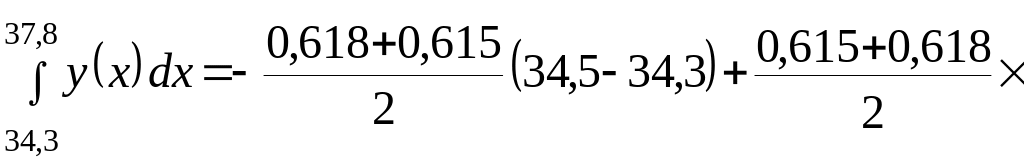
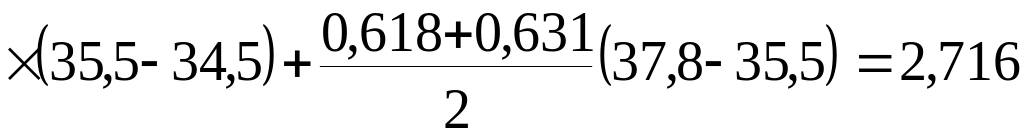
Полученные коэффициенты подставляются в систему уравнений (2.4.26):
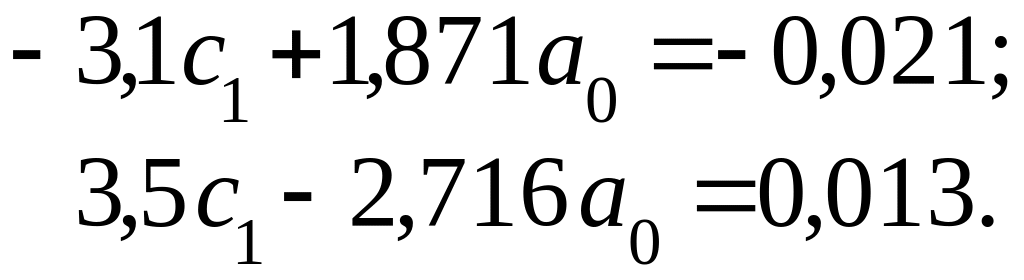
Решая эту систему, определяются
![]() .
.
Затем находится значение первой производной в начальной точке путем подстановки в уравнение (2.4.23) вычисленных коэффициентов и .
Тогда
![]() .
.
Для базисное уравнение имеет вид
или
![]() .
.
Таким образом, получены все параметры. Подставив в уравнение функции с гибкой структурой значение первой производной и значение , можно получить

![]() .
.
Подстановкой
вместо
его перспективного значения на
определенный год определяется
ожидаемая величина коэффициента выпуска.
Необходимо отметить, что основной
задачей при использовании ФГС для
прогноза является определение корней
базисного уравнения
![]() ,
значения которых зависят от коэффициентов
,
значения которых зависят от коэффициентов
![]() .
Последние должны определяться из
принципа оптимальной аппроксимации,
заключающегося в минимизации остатка
и установлении таких значений коэффициентов
.
Последние должны определяться из
принципа оптимальной аппроксимации,
заключающегося в минимизации остатка
и установлении таких значений коэффициентов
![]() ,
для которых значение остатка в каждой
точке таблицы исходных данных не
превышает некоторой заданной величины
(ошибки аппроксимации). При машинной
реализации метода, базирующегося на
применении ФГС, необходимо принимать
допущение о дифференцируемости функции
,
для которых значение остатка в каждой
точке таблицы исходных данных не
превышает некоторой заданной величины
(ошибки аппроксимации). При машинной
реализации метода, базирующегося на
применении ФГС, необходимо принимать
допущение о дифференцируемости функции
![]() раз, с учетом которого можно записать,
что
раз, с учетом которого можно записать,
что
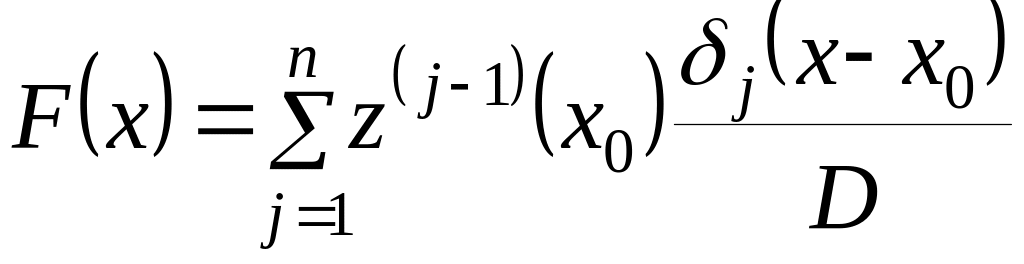 ;
(2.4.27)
;
(2.4.27)
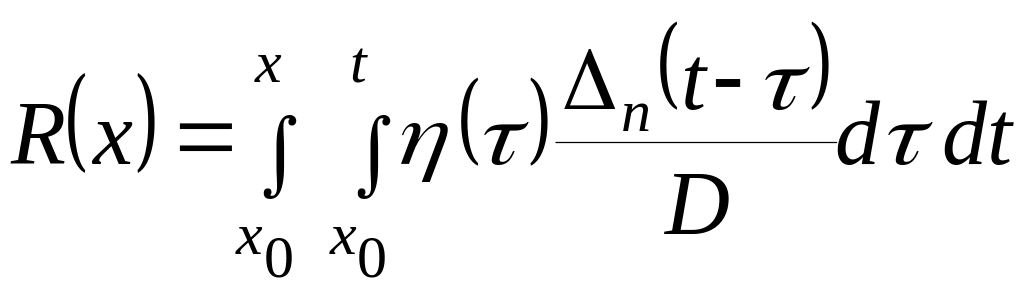 ,
(2.4.28)
,
(2.4.28)
где ![]() – значение производной функции
– значение производной функции
![]()
![]() порядка в точке
;
порядка в точке
;
![]() – выражение,
получаемое из определителя
– выражение,
получаемое из определителя
 (2.4.29)
(2.4.29)
заменой последней
строки определителя на функции
вида
![]() ,
,
![]() ;
;
![]() .
(2.4.30)
.
(2.4.30)
Значения коэффициентов
определяются в результате решения
уравнения (9.50) путем приравнивания его
к нулю. В связи с тем, что производные
![]() неизвестны, переходят к системе
линейных алгебраических уравнений [1],
[2] вида
неизвестны, переходят к системе
линейных алгебраических уравнений [1],
[2] вида
![]() ,
(2.4.31)
,
(2.4.31)
где 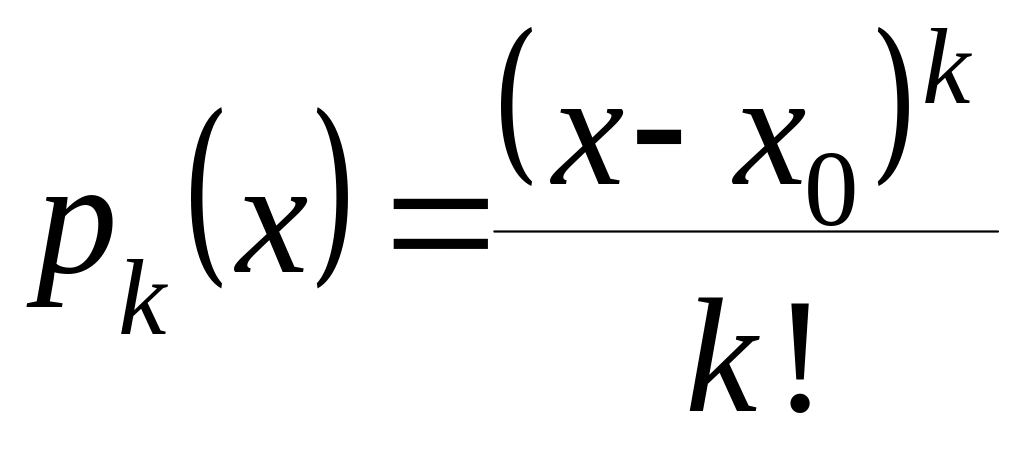 ,
,
![]() ;
;
![]() – постоянная
интегрирования;
– постоянная
интегрирования;
![]() ;
;
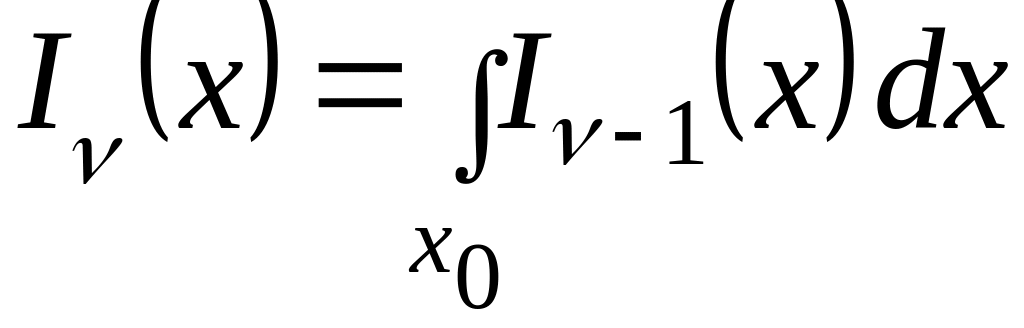 ,
,
![]() ,
;
,
;
![]() ;
;
![]() .
.
Результатом решения
этой системы является определение
коэффициентов
,
что позволяет по базисному уравнению
вычислить параметры
.
Неизвестные
![]() как следует из (2.4.18), (2.4.27), равны значениям
производных функций в точке
,
то есть
как следует из (2.4.18), (2.4.27), равны значениям
производных функций в точке
,
то есть
![]() .
.
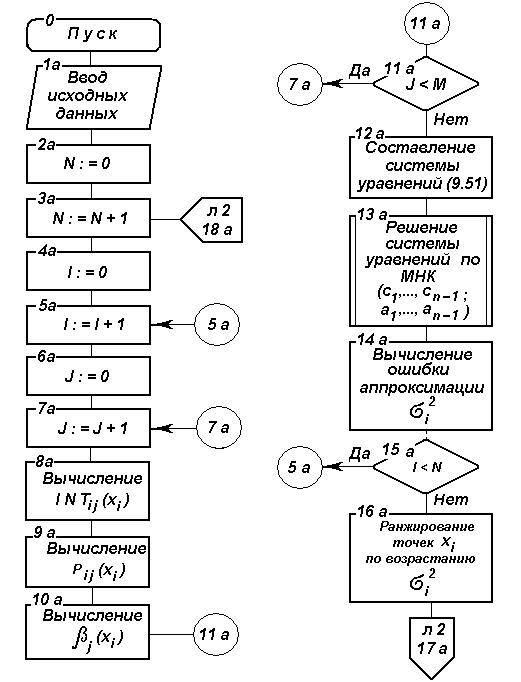
Рис.2.17. Блок-схема алгоритма параметрического прогнозирования
на основе ФГС
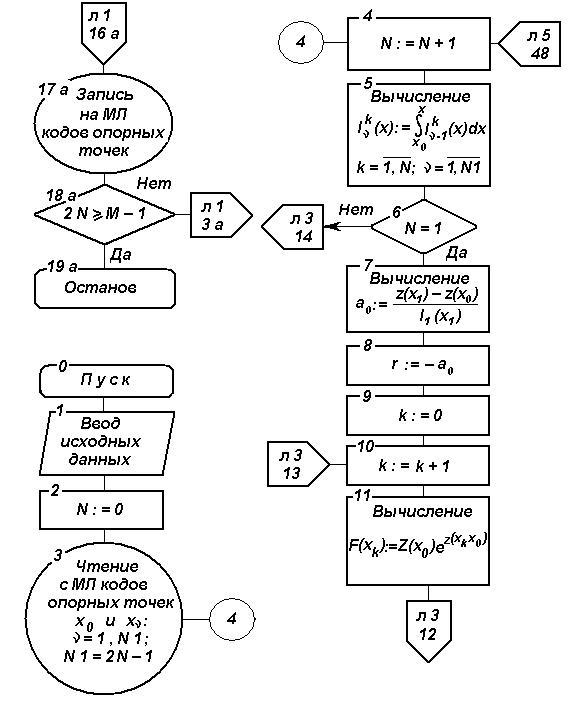
Рис. 2.17. Блок-схема алгоритма параметрического прогнозирования
на основе ФГС (продолжение)
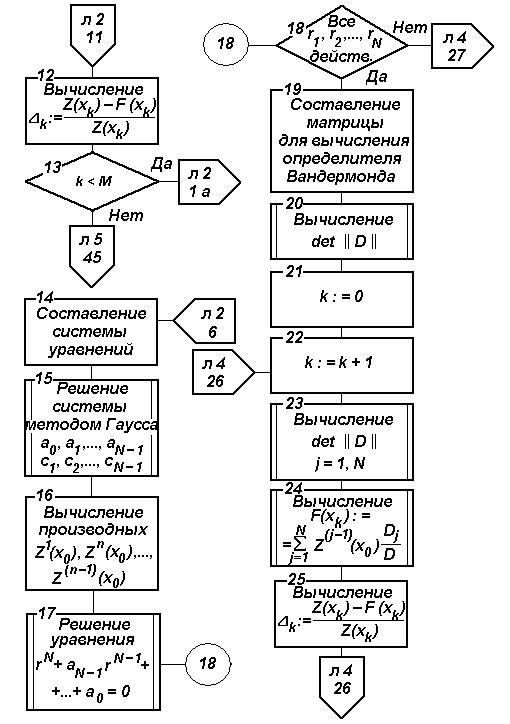
Рис. 2.17. Блок-схема алгоритма параметрического прогнозирования
на основе ФГС (продолжение)
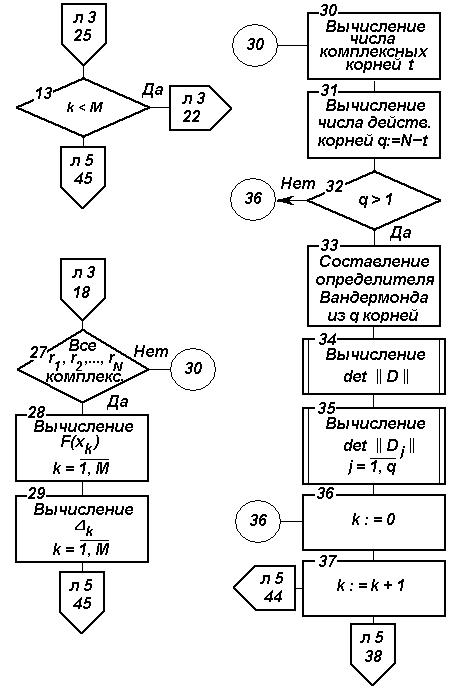
Рис. 2.17. Блок-схема алгоритма параметрического прогнозирования
на основе ФГС (продолжение)
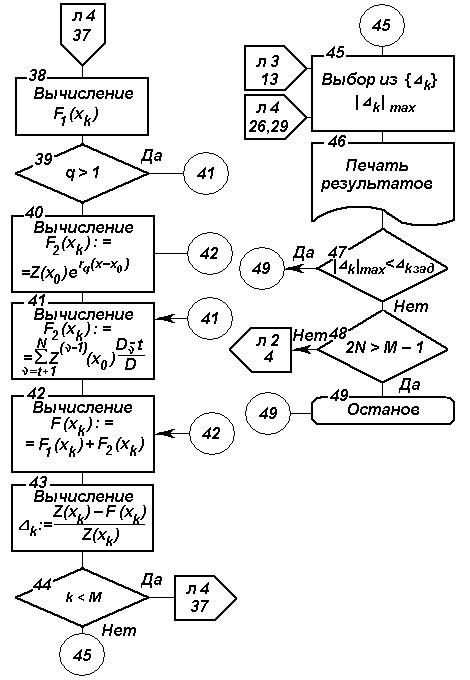
Рис. 2.17. Блок-схема алгоритма параметрического прогнозирования
на основе ФГС (продолжение)
На основе изложенного разработан алгоритм параметрического прогнозирования, блок-схема которого изображена на рис. 2.17.
Согласно работам
[1], [2] можно утверждать, что ошибка
аппроксимации в значительной степени
зависит от системы опорных точек
и
![]() ,
которые необходимо выбрать для вычисления
коэффициентов при неизвестных
,
которые необходимо выбрать для вычисления
коэффициентов при неизвестных
![]() и
и
![]() и свободных членов системы уравнений
(9.51). Поэтому в рамках алгоритма
имеется специальная процедура выбора
системы опорных точек (блоки 1–19),
использование которой обеспечивает
минимальную ошибку аппроксимации. Смысл
этой процедуры сводится к следующему:
и свободных членов системы уравнений
(9.51). Поэтому в рамках алгоритма
имеется специальная процедура выбора
системы опорных точек (блоки 1–19),
использование которой обеспечивает
минимальную ошибку аппроксимации. Смысл
этой процедуры сводится к следующему:
в качестве начальной точки последовательно выбирается каждая точка таблицы исходных данных (блоки 4а, 5а, 15а);
при зафиксированном значении
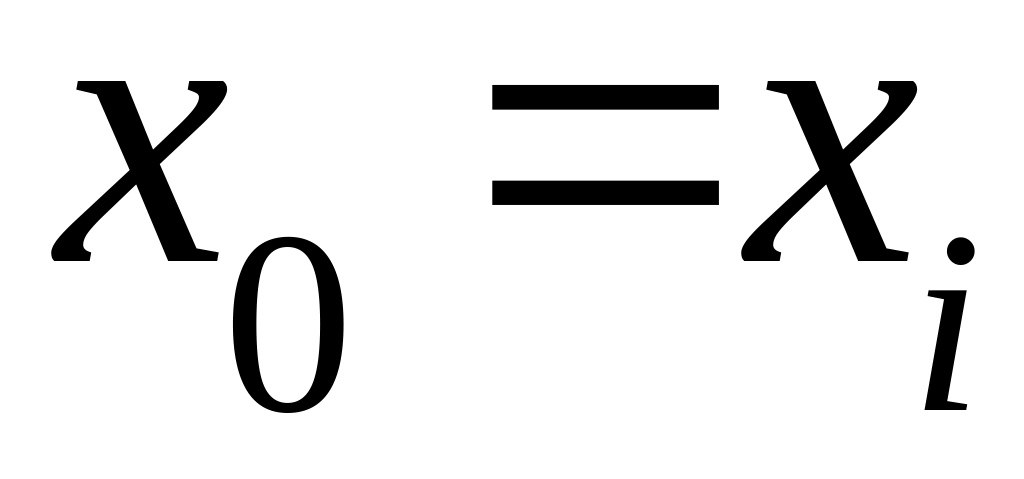 вычисляются значения
вычисляются значения
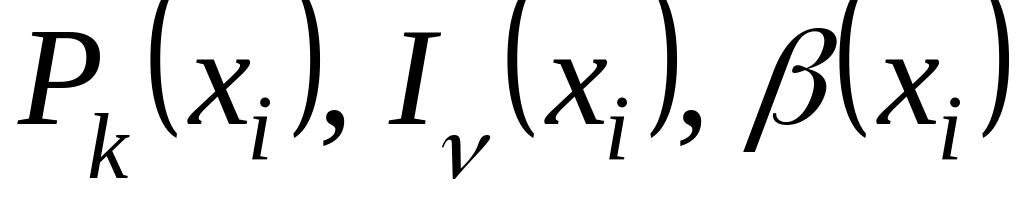 (блоки 6а–11а);
(блоки 6а–11а);составляется система уравнений (2.4.31) (блок 12а);
решается система уравнений (2.4.31) по МНК и определяются значения Си
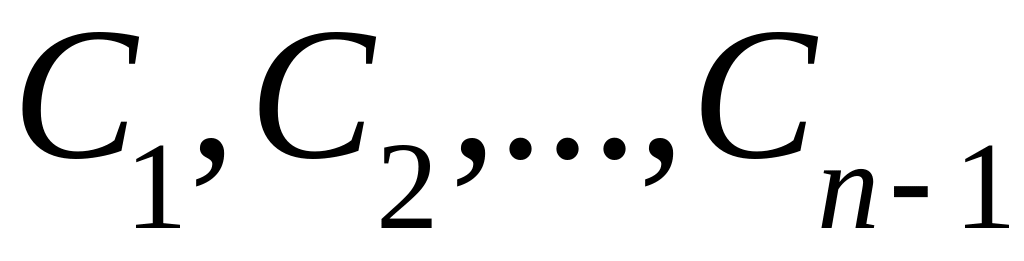 ,
(блок 13а);
,
(блок 13а);устанавливается структура модели, например в виде регрессионного уравнения
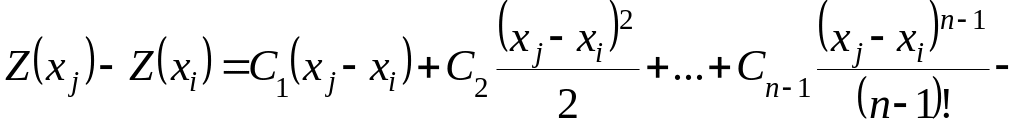
![]() (2.4.32)
(2.4.32)
параметры которого определены выше, и задают ошибку аппроксимации по
зависимости (блок 14а)
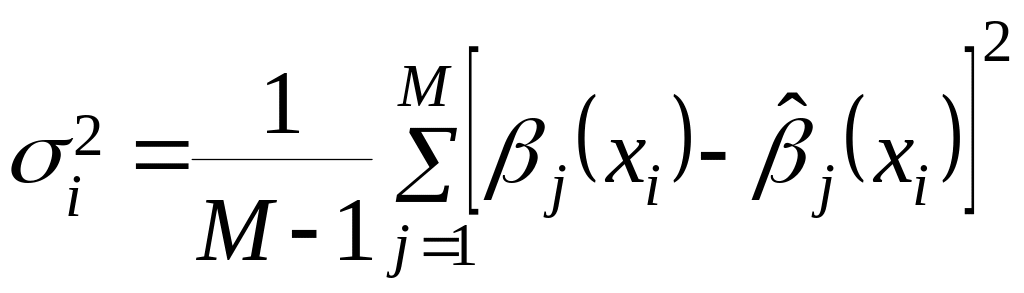 ,
(2.4.33)
,
(2.4.33)
где – число наблюдений над прогнозируемой характеристикой;
осуществляются ранжировка исходных данных по возрастанию
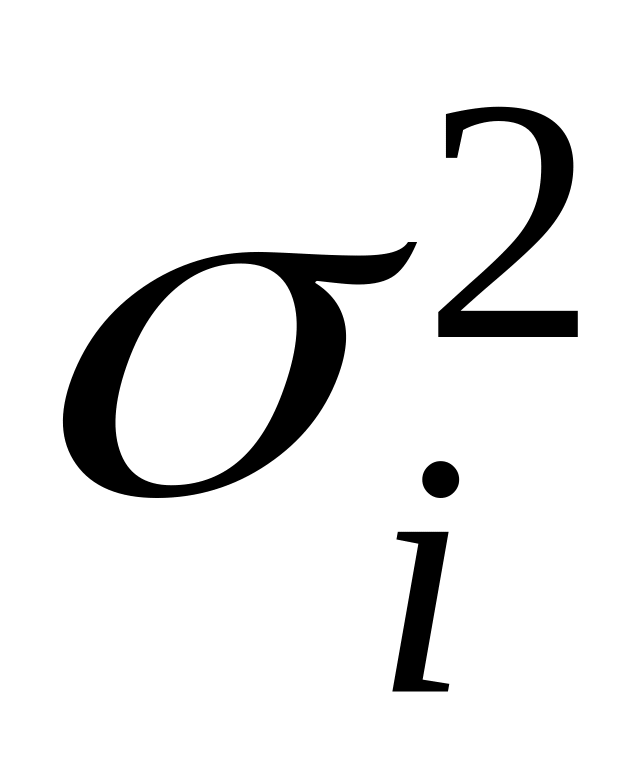 ,
выбор опорных точек по правилу (блок
16а)
,
выбор опорных точек по правилу (блок
16а)
![]()
![]()
и их запись;
описанная процедура повторяется для каждого значения (блоки 2а, За, 18а),
После выбора
опорных точек в алгоритме предусмотрены
операторы по подготовке к составлению
системы уравнений
![]() порядка. С этой целью по соответствующим
зависимостям методом численного
интегрирования (методом трапеций)
вычисляются
порядка. С этой целью по соответствующим
зависимостям методом численного
интегрирования (методом трапеций)
вычисляются
![]() ,
а также значения
,
а также значения
![]() и
и
![]() (блок 5). При этом
(блок 5). При этом
![]()
Если число членов
ФГС-модели
![]() ,
то значения параметров
,
то значения параметров
![]() функции
функции
![]() и относительного отклонения
и относительного отклонения
![]() функции
от
функции
от
![]() в
-той
точке
в
-той
точке
![]() рассчитываются в соответствии с
выражениями блоков 7–3. На основе выбора
из множества
рассчитываются в соответствии с
выражениями блоков 7–3. На основе выбора
из множества
![]() значения
значения
![]() и сравнения его с заданным
(блоки 45, 47), принимается решение либо
продолжать усложнять модель, либо
удовлетвориться достигнутой сложностью.
При
и сравнения его с заданным
(блоки 45, 47), принимается решение либо
продолжать усложнять модель, либо
удовлетвориться достигнутой сложностью.
При
![]() осуществляется составление системы
уравнений
порядка вида (9.51) (блок 14) и решение
ее методом Гаусса относительно
параметров
осуществляется составление системы
уравнений
порядка вида (9.51) (блок 14) и решение
ее методом Гаусса относительно
параметров
![]() и постоянных интегрирования
(блок 15). В блоке 16 осуществляется
вычисление параметров
по зависимостям
и постоянных интегрирования
(блок 15). В блоке 16 осуществляется
вычисление параметров
по зависимостям
![]() (2.4.34)
(2.4.34)
Вычисление корней базисного уравнения производится методом Ньютона с использованием стандартной программы (блок 17). Поскольку в общем случае корни уравнения могут быть действительными, комплексными или действительными и комплексными, в блоках 18, 27 производится их анализ с целью определения дальнейшей расчетной схемы. При условии, что все корни действительные, функция принимает вид
 ,
(2.4.35)
,
(2.4.35)
где – степенной определитель -го порядка (2.4.29), значение которого вычисляется методом перекрестного умножения (блоки 19, 20);
![]() – определитель,
получаемый из (2.4.29) заменой
-той
строки на функции
– определитель,
получаемый из (2.4.29) заменой
-той
строки на функции
![]() – блок 23;
– блок 23;
![]() – вычисленная
ранее производная.
– вычисленная
ранее производная.
Значение функции в каждой точке и ее отклонения вычисляются в блоках 21, 22, 24-26. При подстановке значений , и зависимость (2.4.35) принимает вид суперпозиции экспоненциальных законов, параметрами которых являются аргументы прогнозирующих зависимостей.
Если все корни комплексные, то имеет вид
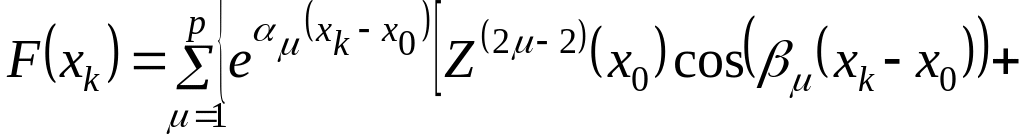
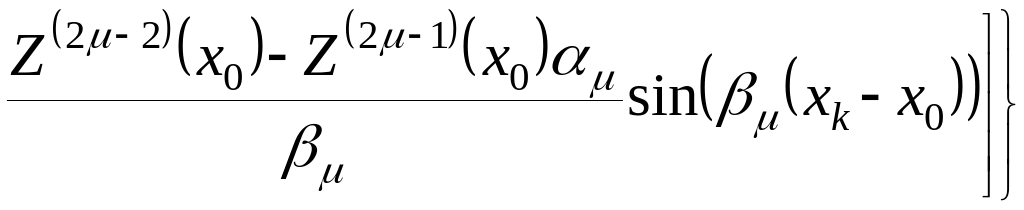 ,(2.4.36)
,(2.4.36)
где ![]() – нечетное натуральное число);
– нечетное натуральное число);
![]() –
действительная часть корня;
–
действительная часть корня;
![]() ;
;
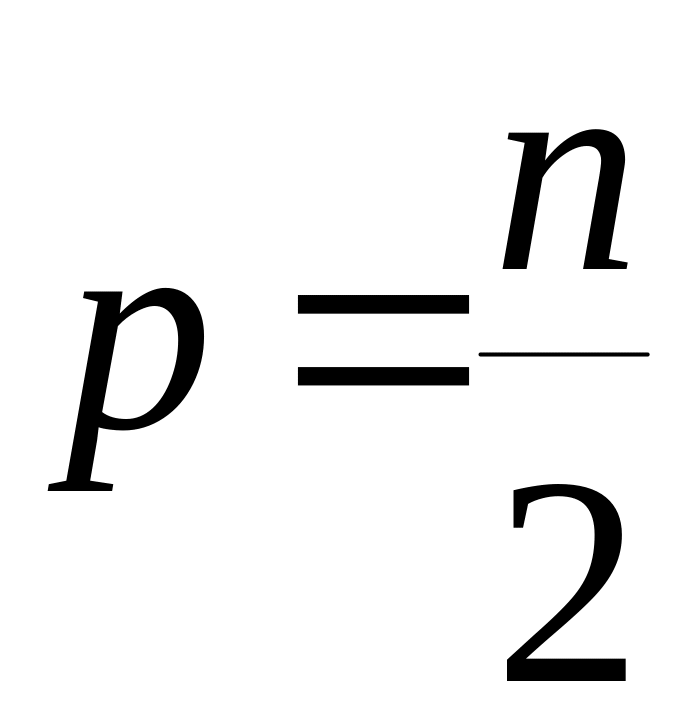 .
.
Значения функции
и ее отклонения
вычисляются в блоках 28, 29. Если в результате
анализа устанавливается, что
корней
![]() комплексные, а
корней
комплексные, а
корней
![]() действительные, то
принимает вид
действительные, то
принимает вид
![]() ,
,
где
![]() вычисляется по
зависимости (2.4.36) с использованием
корней
вычисляется по
зависимости (2.4.36) с использованием
корней
![]() блок 38);
блок 38);
![]() при
при
![]() вычисляется по зависимости (2.4.35) с
использованием корней
вычисляется по зависимости (2.4.35) с
использованием корней
![]() (блоки 33, 34, 35, 41), при
(блоки 33, 34, 35, 41), при
![]() – в соответствии с блоками 32, 39, 40.
Значения функции
и ее отклонения
от
вычисляются в блоках 36, 37, 42, 43, 44. Результаты
расчетов выводятся на печать. После
вычисления функции
и
в каждом из приведенных случаев
выбирается максимальное значение
отклонения
– в соответствии с блоками 32, 39, 40.
Значения функции
и ее отклонения
от
вычисляются в блоках 36, 37, 42, 43, 44. Результаты
расчетов выводятся на печать. После
вычисления функции
и
в каждом из приведенных случаев
выбирается максимальное значение
отклонения
![]() ,
которое сравнивается с заданным
(блоки 45, 47).
,
которое сравнивается с заданным
(блоки 45, 47).
По результатам сравнения принимается решение о наращивании сложности модели либо о его прекращении. В блоке 48 осуществляется проверка достаточности числа наблюдений для заданной сложности модели.