


Completing the search |
485 |
|
|
Figure 12.4
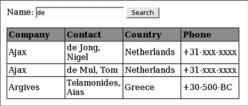
The search results are displayed from the Ajax live search.
page. Finally, we take the result we obtained from the transformToFragment() method and append it to the element. The newly formatted search results are now displayed to the user.
This code introduced some new concepts to us, including the XSLTProcessor object, which allows us to combine arbitrary XML and XSLT files. The Mozilla and Firefox browsers require us to use more DOM methods to combine the two documents. Internet Explorer, on the other hand, required only a single line of code to transform the XML document. The overall end result is exactly the same: they both show our results formatted according to the XSLT file.
Now that the client-side code is finished, we can save our documents and run a test of our live search. Enter some text into the textbox, and click the search button. The results should appear in the table format shown in figure 12.4.
As you can see, we have finished building our XSLT document and were able to run a successful search. The table displayed in figure 12.4 is rather dull since it has no formatting. That means the only thing that we have left to do is style our results table to make it more visually appealing. To do that, we need to use Cascading Style Sheets (CSS).
12.5 Completing the search
Now that we have combined our XML and XSLT documents to get our results, we need to enhance the style of the search results by applying CSS to our elements. Styling the elements will make it easier for the users to read the results. The first step in improving the user experience is to apply our CSS rules to the HTML elements.
12.5.1Applying a Cascading Style Sheet
We introduced Cascading Style Sheets in chapter 2. A Cascading Style Sheet will make the results look professional with a minimum amount of effort on our part, separating the presentation of the results from the document structure and from the transformation logic. Along the way, if the manager or client hates the colors, we can make the changes quickly and easily. If we’re on a large project with
Completing the search |
487 |
|
|
Figure 12.5
The search results are displayed from the Ajax live search with CSS applied to the elements.
applying the stylesheet properties, we save our document and run the same search again. Our new formatted table is shown in figure 12.5.
As you can see, the table has a structured format that was easily created by applying CSS properties to our table elements. If we wanted to add more functionality to our stylesheet, we could add class references to the XSLT file to make it even more flexible. CSS lets us customize the table any way we want, but we may want to improve the search in other areas as well.
12.5.2Improving the search
One of the benefits of Ajax is that it’s easy to pass information back to the server. This project was a simple exercise for creating a search utilizing Ajax and XSLT to display a formatted results table with a minimum amount of effort. We can make the live search as sophisticated as we want. Let’s look at some ways to improve it.
Including new features
The search form we created uses a single textbox and a single submit button to perform the search. We can easily adapt this search to use multiple parameters, such as additional search parameters with the contact name or country. All we have to do is send the additional parameters back to the server and have the server-side code check for them. That means the users can have additional ways to look for information, making the form more useful.
We could add other Ajax features to this script, such as the double combination script, as we did in chapter 9. This would help reduce the possibilities from which the user can choose. We can implement techniques from chapter 10 with the type-ahead suggest, too.
Supporting Opera and Safari
If you recall, we have a problem with Opera and Safari not supporting either the transformNode() method or the XSLTProcessor object. We have two options for supporting Opera and Safari. The first one is to use Ajax to send the files to a server-side page for processing. The server-side code can combine the XML and

488CHAPTER 12
Live search using XSLT
XSLT documents. We would then fetch the result of the transformation using a single ContentLoader object, rather than fetching the XML data and the XSLT stylesheet independently. This is not the best solution since we have to use two round-trips to perform the transformation.
Our second option is to submit the entire page back to the server without the use of Ajax. The server in this case would handle the submission and combine the XML and XSLT documents on the server as we would do traditionally. This approach is better because it lets all users use the search. If a person is using an early version of a browser that does not support the XMLHttpRequest object, then that user can use the form. If we used the Ajax-only technique, the people without the ability to use Ajax would not be able to retrieve the two files for processing. Our second approach gives them the ability to use the form since Ajax is not required. In order to add this functionality, we need to make two changes to the LoadXMLXSLTDoc() function, as shown in listing 12.10. We must alter the first if statement to include a check for the XSLT processor. Then we must add an else statement to force the submit back to the server.
Listing 12.10 Altering LoadXMLXSLTDoc to support Opera and Safari
function LoadXMLXSLTDoc(urlXML,urlXSL,elementID){ var reqXML;
var reqXSL;
if (window.XMLHttpRequest && window.XSLTProcessor){ //...do Mozilla client XSLT
}else if (window.ActiveXObject){ //...do Internet Explorer client XSLT
}else{
document.Form1.onsubmit = function(){return true;} document.Form1.submit();
}
}
In listing 12.10, we remove the onsubmit event handler inside the else branch of the conditional check so that we submit the form to the server. Without removing the onsubmit handler, the form would not submit back to the server.
The server-side page then has to do all of the processing and put the element on the form. In return, we get a fast response for those users who can combine XSLT with JavaScript, and we do not alienate the users who do not support Ajax or the XSLTProcessor. Remember that Ajax is giving us the benefit of not having to re-render the entire page, which can lose the current state of the page. We do not have to worry about the scroll position, form values, and so on. Since