

Refactoring 491
location.href.split("?")[0] + "?q=" + document.Form1.user.value + "'>Save Search</a>";
document.getElementById("spanSave").innerHTML = strLink;
The code in listing 12.11 generates a dynamic link to our current search page and adds the querystring parameter q with the value of the textbox. The querystring parameter is what allows us to remember the search. This new link is then added to the span on the page so the user can select the link and send it to others or bookmark it by clicking on the link and setting it to their favorites for future use. In listing 12.12, we obtain the querystring value from the URL when the page loads and then perform the search automatically so the results are shown.
Listing 12.12 Obtaining the querystring value and performing the search
window.onload = function(){
var strQS = window.location.search; var intQS = strQS.indexOf("q="); if(intQS != -1){
document.Form1.user.value = strQS.substring(intQS+2); GrabNumber();
}
}
We add a handler for the onload event to our window object that will execute a function when the page is loaded. We check to see if our querystring value is in the URL; if it is, we obtain the value. The querystring value is placed inside the textbox, and then the GrabNumber() function is executed automatically to build the results table. Adding this code lets us bookmark the search pages and have the search results appear when we come to the page, instead of having to type in the value each time. This makes our Ajax project even more user-friendly.
12.6 Refactoring
It’s time to take our XSLT live search to the next level by—you know the drill— componentizing! We need to take this nifty script and refactor it until we have an object-oriented reusable component. So let’s start with the client-side XSLT processing. This example is different than all the others in the sense that it handles all the DOM manipulation aspects of response handling with XSLT. So let’s start there. We should be able to refactor our XSLT processing in such a way that we can use it with other components—not just the live search. Once we do that, we’ll

492CHAPTER 12
Live search using XSLT
focus on refactoring the live search in such a way that it can be quickly added to any page as an easy-to-use pluggable component.
12.6.1An XSLTHelper
We’ve gone through a lot of trouble to learn the ins and outs of XSLT processing on the client side. For example, we’ve noticed that there are completely different APIs for doing XSLT processing on the client based on whether we’re targeting an IE browser or a Mozilla-based browser. And each API has its own set of quirks and peculiarities. So, it would be a shame for us not to encapsulate that hardearned knowledge so that our colleagues who come behind us don’t have to go through the same pains to do some seemingly simple XSLT transformations. Therefore, let’s do just that by creating an XSLTHelper object to encapsulate all of our XSLT concerns.
All XSLT processing typically requires two sources of information: the XML document to transform and the XSL document to provide the transformation rules. With that in mind, let’s write a constructor for our helper that will give us a way to store that state:
function XSLTHelper( xmlURL, xslURL ) { this.xmlURL = xmlURL;
this.xslURL = xslURL;
}
The constructor is probably one of the simplest you’ve seen in this book yet. It stores the URLs for the documents we just noted: the XML data document and the XSLT transformation document. But before we get too giddy about the simplicity of it all, we need to think about an API to support graceful degradation. You’ll note that our script conditionally performs only XSLT processing if the browser supports it. So if we’re writing a helper, it would be nice for the helper to provide an API to tell the client whether or not it can perform XSLT operations. However, instantiating some object with XSLT in its name just to find out whether XSLT is supported doesn’t seem right. The solution to this conundrum is an API function that’s not scoped to the prototype object but rather to the constructor function itself. We can think of this function much like a static method in the Java world. The intent is that a client should be able to write code that looks something like this:
XSLTHelper.isXSLTSupported();
rather than having to instantiate an object like this:

Refactoring 493
var helper = new XSLTHelper( 'phoneBook.xml', 'transformation.xsl' );
var canDoThis = helper.isXSLTSupported();
So let’s accommodate our inquisitive users with a pseudo-static method, which is expressed as follows:
XSLTHelper.isXSLTSupported = function() {
return (window.XMLHttpRequest && window.XSLTProcessor ) || XSLTHelper.isIEXmlSupported();
}
XSLTHelper.isIEXmlSupported = function() { if ( ! window.ActiveXObject )
return false;
try { new ActiveXObject("Microsoft.XMLDOM"); return true; }
catch(err) { return false; }
}
There’s nothing new here. The logic is identical to the logic defined earlier; we’ve just encapsulated that knowledge about how to detect XSLT support. I’m sure someone will thank us for this. So now we can get on to the business of fleshing out the rest of the XSLTHelper API.
Let’s keep things simple. How about saying that we’ll have a single method for clients of our class to call to perform XSLT processing? Our helper will have ancillary methods to separate the responsibilities of all the internal logic, but we’ll provide a single API for our clients to use. The semantics will be as follows:
var helper = new XSLTHelper ( 'phoneBook.xml', 'transformation.xsl' );
helper.loadView( 'someContainerId' );
In this example usage, the phoneBook.xml document should be transformed into HTML by the transformation.xsl document, and the resulting HTML should be placed within the element whose ID is someContainerId. Let’s further specify that the parameter to loadView() can be either a string representing the ID of an element or the element itself. We’ll internally figure out what we’re dealing with and react accordingly. And, by the way, if the client doesn’t care to reuse the helper instance, we can express all this with a single line of code:
new XSLTHelper('phoneBook.xml', 'transformation.xsl').loadView('someContainerId');
Now that we’ve defined our API and its semantics, let’s implement it as shown in listing 12.13.


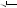 xsltProcessor.importStylesheet(this.xslStyleSheet); var fragment = xsltProcessor.
xsltProcessor.importStylesheet(this.xslStyleSheet); var fragment = xsltProcessor.