

3.10. Форма звіту за результатами регресійного аналізу
Існують різні форми звіту за результатами регресійного аналізу, але тут ми застосуємо ту, що належить до нашого ілюстрованого прикладу:
= (6,4138) (0,0357) = 0,9621 t = (3,8128) (14,2405) df = 8 5/11/1)
p
= (0,002571)
(0,000000289)
|
(3.10.1) |
У виразах (3.10.1) числа в дужках у другому рядку являють собою стандартні помилки коефіцієнтів регресії, числа в дужках у третьому рядку оцінки величин t:
|
|
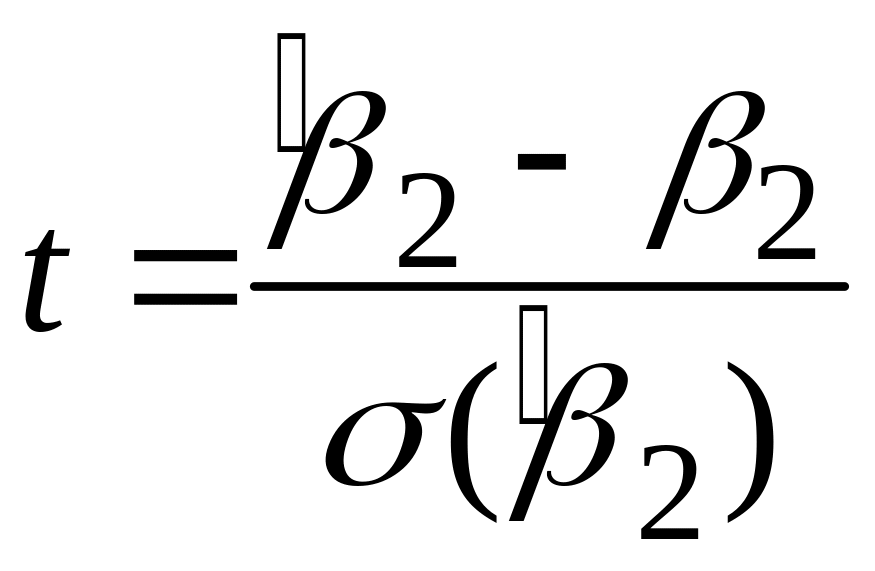 ,
,
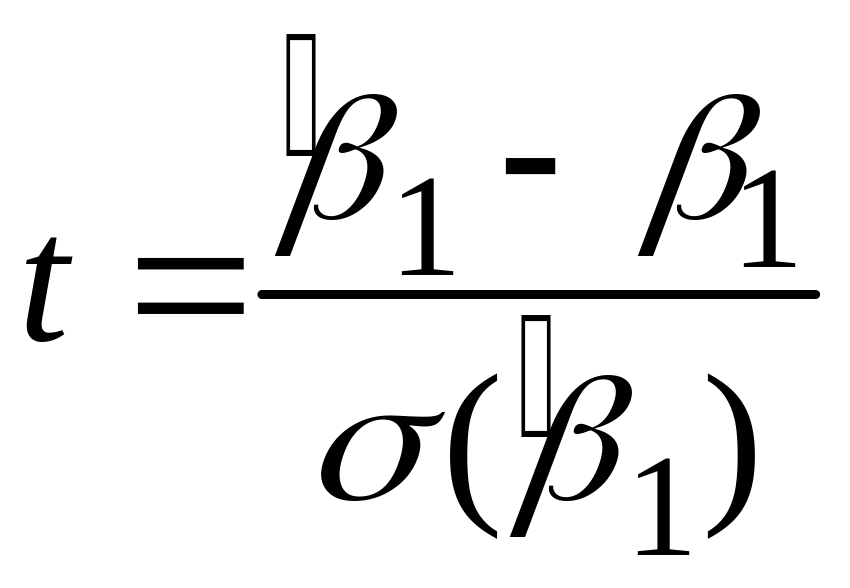
у
припущенні нульової гіпотези про те,
що 1=0
і
2=0
(3,8128 = 24,4545/6,4138; 14,2405 = 0,5091/0,0357), а числа у
третьому рядку
обчислена ймовірність. Так, для 8 df
імовірність отримання величини
![]() дорівнює 0,0026, а ймовірність отримання
дорівнює 0,0026, а ймовірність отримання
![]()
близько 0,0000003.
близько 0,0000003.
Шляхом
подання імовірності р
оцінюваних коефіцієнтів ми можемо
відразу бачити точний рівень значимості
кожної оцінюваної величини t.
Так, при нульовій гіпотезі Н0:
1
= 0, точна імовірність (тобто величина
р)
отримання величини
приблизно дорівнює 0,0026. Отже, якщо ми
відкидаємо цю нульову гіпотезу,
імовірність того, що ми допускаємо
помилку 1
становить
26 випадків із 10 000, що насправді дуже
мало. У практичних задачах можна сказати,
що істинне значення
![]() .
Ще більше це стосується схильності до
покупки 2.
.
Ще більше це стосується схильності до
покупки 2.
Як
ми раніше згадували
![]() .
При нульовій гіпотезі
величина F=202,87
(1 df
чисельник, 8 df
знаменник), а t=14,24
(8
df);
відповідно до теорії (14,24)2=202,87.
.
При нульовій гіпотезі
величина F=202,87
(1 df
чисельник, 8 df
знаменник), а t=14,24
(8
df);
відповідно до теорії (14,24)2=202,87.
3.11. Обчислення результатів регресійного аналізу
У вступі нами була описана загальна схема економетричного моделювання:
Економічна теорія.
Математична модель теорії.
Економетрична модель теорії.
Дані.
Проведення оцінки параметрів економетричної моделі.
Перевірка гіпотез.
Прогнозування.
Використання моделі для прийняття рішень або з політичною метою.
Зараз, після подання результатів регресійного аналізу нашої моделі “споживання дохід” у вигляді (3.11.1), природно задати питання про адекватність цієї моделі. Наскільки «добре» вона підігнана до наявних даних? Для відповіді на це запитання нам потрібні деякі критерії.
По-перше,
чи відповідають знаки оцінених
коефіцієнтів теоретичним прогнозам
або наявному досвіду? Апріорі
,
схильність до покупки, повинна бути
позитивною. По-друге, якщо згідно з
теорією взаємозв’язок
повинен бути не тільки позитивним, але
й статистично значимим, чи виконується
це? Як ми зазначили в розд. 3, МРС –
схильність до покупки
є не тільки позитивною величиною, а й
статистично значимо відрізняється від
нуля. Ці ж зауваження стосуються й
коефіцієнта
.
По-третє, наскільки добре регресійна
модель пояснює зміну споживацьких
витрат? Для відповіді на це запитання
можна застосувати
.
У нашому випадку
![]() дуже високий, враховуючи, що максимальне
значення
є 1.
дуже високий, враховуючи, що максимальне
значення
є 1.
Таким
чином, вибрана нами модель для пояснення
характеру споживацьких витрат є цілком
прийнятною. Але перш ніж підвести межу,
цікаво з'ясувати, чи задовольнить модель
припущення CNLRM (classical normal linear regression model)
класичної лінійної моделі з нормальним
законом розподілу. Ми не звертатимемо
увагу на різні припущення, оскільки
модель є дуже простою. Але є одна гіпотеза,
яку ми хотіли б перевірити, а саме –
гіпотеза про нормальний розподіл
випадкової складової
![]() .
.
Пригадаємо, що використані раніше t- і F-тести припускали, що розподілена за нормальним законом розподілу. Інакше процедура перевірки не буде дійсна для малих або кінцевих вибірок.
Тест на нормальність
Хоча в літературі обговорюється ряд тестів перевірки на нормальність, обмежимося розглядом двох: 1) тест якості підгонки і 2) тест Jarque-Bera. Обидва ці тести використовують залишки і розподіл імовірності .
![]() тест
якості підгонки.
Цей тест проводять таким чином. Спочатку
ми отримуємо рівняння регресії, а також
залишки
,
підраховуємо стандартне відхилення
((
тест
якості підгонки.
Цей тест проводять таким чином. Спочатку
ми отримуємо рівняння регресії, а також
залишки
,
підраховуємо стандартне відхилення
((![]() ,
оскільки
).
Потім упорядковуємо залишки і розміщуємо
їх у різних групах (у нашому прикладі
ми розміщуємо їх у шести групах),
відповідних величині відхилення від
нуля. Для нашого прикладу ми одержуємо
такі дані (табл. 3.5).
,
оскільки
).
Потім упорядковуємо залишки і розміщуємо
їх у різних групах (у нашому прикладі
ми розміщуємо їх у шести групах),
відповідних величині відхилення від
нуля. Для нашого прикладу ми одержуємо
такі дані (табл. 3.5).
Таблиця 3.5