

5.7. R2 і скорегований r2
Коефіцієнт детермінації R2 є неспадна функція від кількості пояснювальних змінних або регресорів у моделі. При збільшенні кількості регресорів R2 майже неминуче зростає і ніколи не спадає. Інакше кажучи, додавання змінної Х до моделі не зменшить R2. Щоб переконатися в цьому, пригадаємо визначення коефіцієнта детермінації:
. |
(5.7.1) |
Величина
не залежить від кількості змінних Х
у
моделі, оскільки це просто
![]() .
Величина RSS
,
проте, залежить від кількості присутніх
у моделі регресорів. Зрозуміло, що при
зростанні кількості змінних Х
величина
повинна спадати (принаймні не зростати).
Отже, R2
зростатиме. Враховуючи це, при порівнянні
двох моделей регресії з однаковою
залежною змінною, але різною кількістю
змінних Х,
потрібно бути дуже обережними з наданням
переваги моделі з більш високим R2.
.
Величина RSS
,
проте, залежить від кількості присутніх
у моделі регресорів. Зрозуміло, що при
зростанні кількості змінних Х
величина
повинна спадати (принаймні не зростати).
Отже, R2
зростатиме. Враховуючи це, при порівнянні
двох моделей регресії з однаковою
залежною змінною, але різною кількістю
змінних Х,
потрібно бути дуже обережними з наданням
переваги моделі з більш високим R2.
Порівнюючи два коефіцієнти детермінації R2, потрібно обов’язково враховувати кількість регресорів Х, присутніх у моделі. Це можна зробити, якщо скористатися визначенням альтернативного коефіцієнта детермінації, обчислюваного за такою формулою:
|
(5.7.2) |
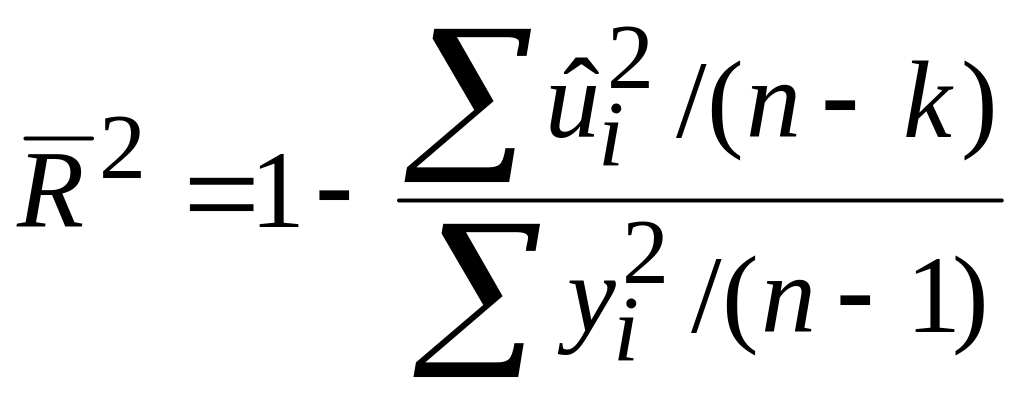 ,
,
де
k
– кількість параметрів у моделі (для
моделі з трьома змінними k=3).
Визначений таким чином коефіцієнт
детермінації називається скоректованим
R2
і позначається
![]() .
Термін «скорегований» позначає
скоректованість за кількістю степенів
вільності, пов’язаних із сумами
квадратів, що входять в (5.7.2).
має (N–k)
степенів вільності. У разі моделі з
трьома змінними ми знаємо, що
має (N–3)
степенів вільності.
.
Термін «скорегований» позначає
скоректованість за кількістю степенів
вільності, пов’язаних із сумами
квадратів, що входять в (5.7.2).
має (N–k)
степенів вільності. У разі моделі з
трьома змінними ми знаємо, що
має (N–3)
степенів вільності.
Рівняння (5.7.2) можна також переписати у вигляді
|
(5.7.3) |
де
– дисперсія залишків, а
![]() – вибіркова дисперсія Y:
– вибіркова дисперсія Y:
![]() .
.
Легко показати, що R2 і пов’язані між собою співвідношенням
|
(5.7.4) |
Цю
рівність можна отримати, якщо підставити
(5.7.1) у (5.7.2). Із (5.7.4) бачимо, що для k>1
![]() ,
а це означає, що при збільшенні змінних
Х
зростає меншою мірою, ніж R2.
Крім того,
може набувати й негативних значень,
тоді як
,
а це означає, що при збільшенні змінних
Х
зростає меншою мірою, ніж R2.
Крім того,
може набувати й негативних значень,
тоді як
![]() завжди позитивний. У прикладних задачах
у випадках, коли
виявляється негативним, його вважають
таким, що дорівнює нулю. Для розглянутого
нами прикладу кривої Філіпса маємо
завжди позитивний. У прикладних задачах
у випадках, коли
виявляється негативним, його вважають
таким, що дорівнює нулю. Для розглянутого
нами прикладу кривої Філіпса маємо
![]() ,
а
,
а
![]() .
.
Порівняння величин R2
У першу чергу дуже важливо відзначити, що при порівнянні моделей на основі значень коефіцієнтів детермінації, як нескоректованих, так і скоректованих, повинні бути однаковими об’єми вибірки N і одними й тими ж залежні змінні. Пояснювальні змінні можуть бути будь-якого вигляду. Так, для моделей
|
(5.7.5) |
|
(5.7.6) |
не
можна порівнювати підраховані
.
Причина полягає в тому, що за визначенням
визначає частину дисперсії залежної
змінної, поясненої за рахунок пояснювальних
змінних, отже, в (5.7.5)
виміряє частину в дисперсії
![]() ,
пояснену за рахунок Х2
і Х3,
а в (5.7.6) це частина в дисперсії
,
пояснена тими ж змінними. Зрозуміло, що
це різні речі. Раніше ми відзначали, що
змінювання
дає відносне змінювання Y,
тоді як змінювання Y
є
абсолютним змінюванням. Отже,
,
пояснену за рахунок Х2
і Х3,
а в (5.7.6) це частина в дисперсії
,
пояснена тими ж змінними. Зрозуміло, що
це різні речі. Раніше ми відзначали, що
змінювання
дає відносне змінювання Y,
тоді як змінювання Y
є
абсолютним змінюванням. Отже,
![]() не одне й те ж, що
не одне й те ж, що
![]() .
Тому коефіцієнти детермінації (5.7.5) і
(5.7.6) не можна порівнювати.
.
Тому коефіцієнти детермінації (5.7.5) і
(5.7.6) не можна порівнювати.
Якщо ми звернемося до функції попиту на каву (2.7.1):
, , |
|
що являє собою лінійну модель, і функції попиту (6.4.5):
(0,0152) (0,0494) F1,9=26,27 t = (51,0045) (–5,1251), |
|
що представляє Log-Lin – модель, то порівнювати їх коефіцієнти детермінації безпосередньо не можна. Як же все-таки порівнювати величини для моделей вигляду (3.7.1) і (6.4.5)? Покажемо це на прикладі функції попиту на каву.
Для порівняння коефіцієнтів детермінації, отриманих із моделей із різним видом залежної змінної, як, наприклад, у моделях (3.7.1) і (6.4.5), можна застосувати два способи.
1.
За відомим значенням
![]() у моделі (6.4.5) знаходимо
у моделі (6.4.5) знаходимо
![]() ,
а потім підраховуємо
між
і
за формулою (2.5.14):
,
а потім підраховуємо
між
і
за формулою (2.5.14):
|
|
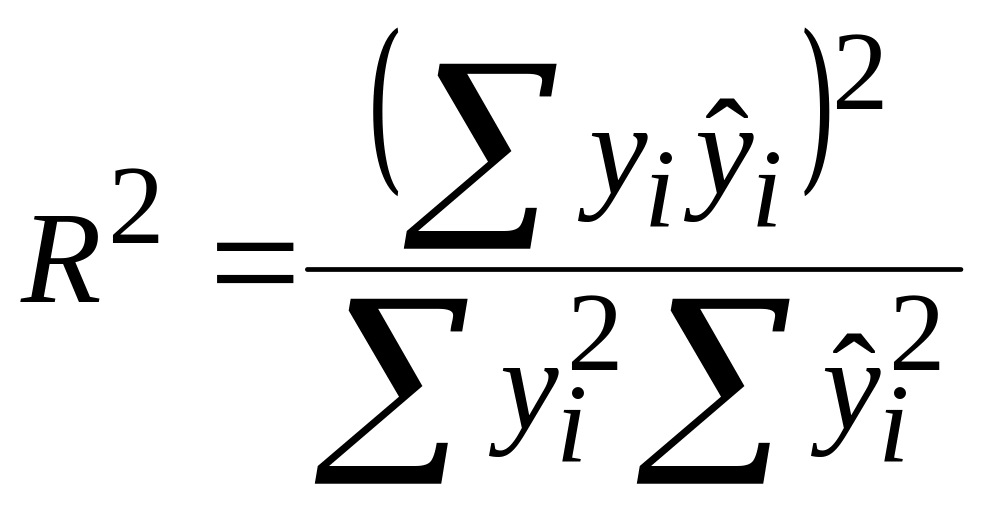 .
.Підрахований таким чином можна порівнювати з коефіцієнтом детермінації з моделі (6.4.5).
2.
Підраховуємо за відомими
з моделі (3.7.1)
і
![]() ,
обчислюємо
між ними. Цей коефіцієнт детермінації
можна порівнювати з
із моделі (6.4.5).
,
обчислюємо
між ними. Цей коефіцієнт детермінації
можна порівнювати з
із моделі (6.4.5).
Припустимо, що ми спочатку вирішили порівнювати величину лінійної моделі (3.7.1) з величиною подвійної логарифмічної моделі (6.4.5). Використаємо значення моделі (3.7.1) і знайдемо за ними , а потім за фактичними значеннями знайдемо . За отриманими значеннями і ми можемо підрахувати , наприклад, за формулою
. |
|
Використовуючи
дані, наведені в (5) і (6) стовпцях табл.
2.1, можна підрахувати за цією формулою
величину
.
Отримуємо
![]() .
Цю величину
вже можна порівняти зі значенням
.
Цю величину
вже можна порівняти зі значенням
![]() з подвійної логарифмічної моделі.
Порівняння цих величин виявляється на
користь логарифмічної моделі.
з подвійної логарифмічної моделі.
Порівняння цих величин виявляється на
користь логарифмічної моделі.
Якщо
ж ми хочемо порівняти величину
із подвійної логарифмічної моделі з
із лінійної моделі, то необхідно за
значеннями
з моделі (6.4.5) обчислити
![]() ,
а потім за цими значеннями і
обчислити
.
Використовуючи дані (4) і (1) стовпців
табл. 2.1, знаходимо
,
а потім за цими значеннями і
обчислити
.
Використовуючи дані (4) і (1) стовпців
табл. 2.1, знаходимо
![]() .
Це значення
вже можна порівнювати зі значенням
коефіцієнта детермінації з лінійної
моделі
.
Це значення
вже можна порівнювати зі значенням
коефіцієнта детермінації з лінійної
моделі
![]() .
Як і раніше, подвійна логарифмічна
модель має високий коефіцієнт детермінації.
.
Як і раніше, подвійна логарифмічна
модель має високий коефіцієнт детермінації.
На закінчення зробимо таке зауваження. Іноді дослідник прагне збільшити , тобто вибрати ту модель, яка має найвищий . Це не правильно, оскільки в регресійному аналізі нашою метою є не отримання за будь-яку ціну високого , а отримання надійних оцінок істинних коефіцієнтів популяцій регресії, що дають можливість зробити статистичні висновки. В емпіричному аналізі часто виникає ситуація, коли має високі значення, а при цьому деякі коефіцієнти регресії виявляються статистично незначущими або ж мають знак, протилежний очікуваному. Отже, дослідник повинен більше зосереджуватися на логічному або теоретичному зв’язку між пояснюваним і пояснювальними змінними та їх статистичній значущості. Якщо при цьому ми отримаємо високе значення , то тим краще. Однак, якщо малий, то це не означає, що наша модель обов’язково погана.