

6. Припущення нормальності розподілу залишків
Якби нашою єдиною метою було отримання точних оцінок параметрів моделі регресії за МНК, який не вимагає ніяких припущень про закон розподілу залишків, то отриманих результатів було б достатньо. Проте якщо метою дослідження є й отримання статистичних висновків, то нам необхідно зробити припущення про закон розподілу .
З
причин, детально розглянутих раніше,
ми знову припускаємо, що
підпадають під нормальний закон розподілу
з нульовим середнім і постійною дисперсією
![]() і
і
![]() .
При цьому припущенні виявляється, що
знайдені за МНК частинні коефіцієнти
регресії є найкращими лінійними
незміщеними оцінками. Крім того, оцінки
,
,
самі підкоряються нормальному закону
розподілу із середніми значеннями
,
,
і дисперсіями, визначуваними за формулами
(5.4.9), (5.4.11) і (5.4.14). Величина
.
При цьому припущенні виявляється, що
знайдені за МНК частинні коефіцієнти
регресії є найкращими лінійними
незміщеними оцінками. Крім того, оцінки
,
,
самі підкоряються нормальному закону
розподілу із середніми значеннями
,
,
і дисперсіями, визначуваними за формулами
(5.4.9), (5.4.11) і (5.4.14). Величина
![]() підкоряється закону розподілу
підкоряється закону розподілу
![]() з (n–3)
степенями вільності, а три оцінки
коефіцієнтів регресії розподілено
незалежно від
.
На підставі вищезазначеного можна
показати, що замінюючи
на її незміщену оцінку
у формулах для стандартних похибок,
кожна з величин
з (n–3)
степенями вільності, а три оцінки
коефіцієнтів регресії розподілено
незалежно від
.
На підставі вищезазначеного можна
показати, що замінюючи
на її незміщену оцінку
у формулах для стандартних похибок,
кожна з величин
|
(6.1) |
|
(6.2) |
|
(6.3) |
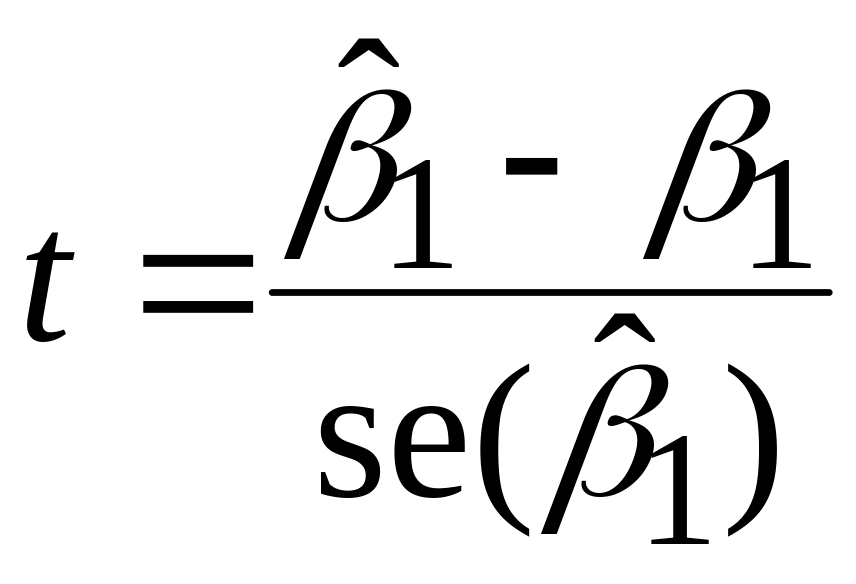 ;
;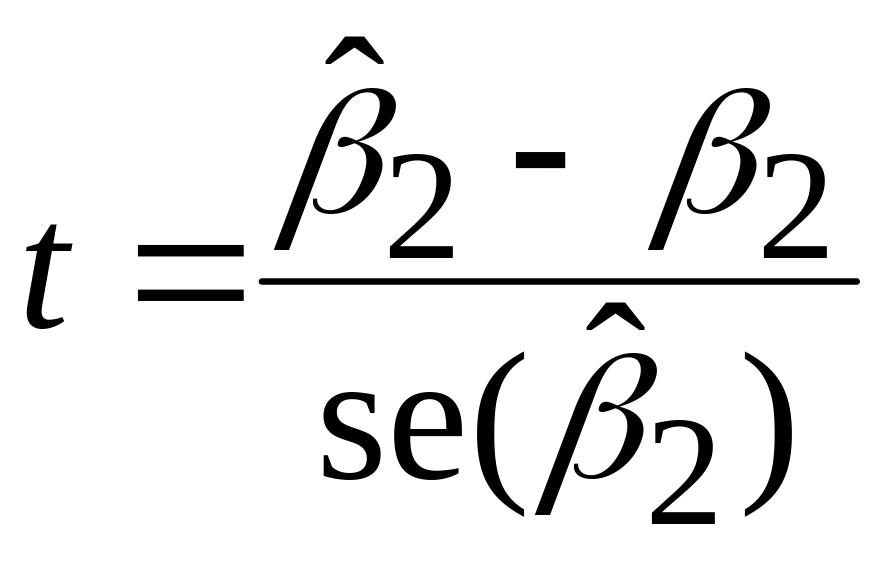 ;
;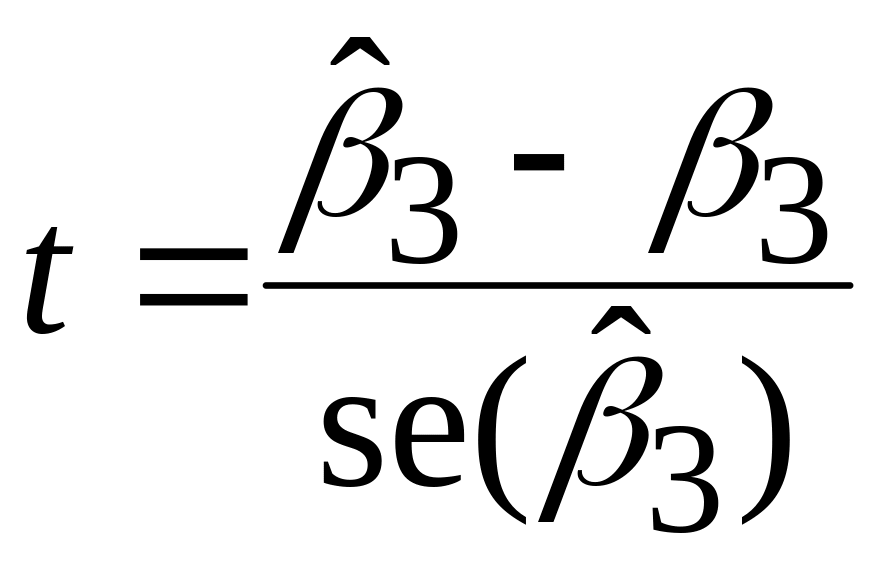
розподілена за законом t-розподілу з (n–3) степенями вільності.
Відзначимо, що кількість степенів вільності тепер складає (n–3), оскільки для обчислення і, отже, нам спочатку необхідно визначити три частинні коефіцієнти регресії. Унаслідок цього на суму квадратів залишків (RSS) накладаються три обмеження (за логікою в моделі з чотирма змінними кількість степенів вільності дорівнює n–4 і т.д.).
Таким чином, t-розподіл може бути застосований для побудови довірчих інтервалів, а також для перевірки статистичних гіпотез про значення істинних коефіцієнтів регресії. Аналогічно, розподіл може бути використаний для перевірки гіпотез про істинне значення . Для демонстрації описаного механізму звернемося до ілюстрованого прикладу.
Зв’язок між особистими витратами й особистими доходами в США в 1956 –1970 рр.
Припустимо, що ми хочемо досліджувати зміну особистих витрат в США за декілька минулих років. Скористаємося такою простою моделлю:
|
(6.4) |
де Y – особисті витрати;
Х2 – особистий дохід (після сплати податків);
Х3 – час, що виміряється в роках.
Рівняння (6.4) постулювало лінійний зв’язок між особистими доходами, доходами і часом або змінною тренда. У більшості випадків множинного регресійного аналізу, що включає дані тимчасових рядів, у модель вводять на додаток до інших пояснювальних змінних змінну тренда, що пояснюється такими причинами.
1. Нас може цікавити, як залежна змінна поводиться зі зміною часу. Наприклад, на графіках часто демонструється, скажімо, поведінка ВНП, зайнятості, безробіття, вартості акцій тощо за деякі послідовні інтервали часу. Вид цих графіків дозволяє визначити тенденцію зміни величини за часом, її зростання, спадання або відсутність певної тенденції. У подібному аналізі нас можуть не цікавити причини, що стоять за тенденцією зростання або спадання досліджуваної величини, а метою може бути просто опис даних, змінюваних у часі.
2. У багатьох випадках змінна тренда є заміною для основної змінної, що впливає на Y. Але ця основна змінна не дозволяє отримати дані, що описують її, або їх отримання пов’язане зі значними труднощами. Наприклад, у моделі виробництва подібною змінною є технологія. Ми чудово розуміємо її вплив, проте незрозуміло, як його виміряти. Отже, можна припустити, що технологія є деяка функція часу, що вимірюється хронологічно. У деяких ситуаціях можна вважати, що впливаюча на Y основна змінна настільки тісно пов’язана з часом, що зручніше ввести в модель сам час, а не цю змінну. Наприклад, у моделі (6.4) час Х3 може представляти населення. Витрати на споживання зростають зі зростанням населення, а саме населення може бути достатньо добре описане лінійною функцією часу.
4. Ще
однією підставою для введення змінної
тренда є бажання уникнути псевдокореляції.
Дані, що стосуються економічних тимчасових
рядів, таких як PCE і PDI, часто змінюються
в одному напрямі, відображаючи тенденцію
зростання або спадання. Отже, якщо
побудувати модель регресії PCE по
відношенню до PDI, то можна отримати
велике значення R2,
що може не відображати істинного зв’язку
між РСЕ і PDI, а просто бути наслідком
загального тренда. Щоб виключити
псевдоасоційованість між економічними
тимчасовими рядами, можна застосувати
кілька прийомів. В одному випадку,
припускаючи, що тимчасові ряди демонструють
лінійну тенденцію, можна ввести в модель
час або саму тенденцію, як це зроблено
в рівнянні (6.4). Унаслідок чого
в рівнянні (6.4) відображає істинний
зв’язок між РСЕ і PDI. В іншому випадку
можна здійснити процедуру детренда Y
(PCE) і X2
(PDI), а потім провести регресію за
отриманими після детренда змінними Y
і
X2,
припускаючи наявність лінійного етапу,
як це було виконано в розд. 5. Спочатку
проводимо регресію Y
за
X3
(час) і одержуємо залишки від цієї
регресії, скажімо
.
Потім проводимо регресію X2
за X3
і одержуємо залишки з цієї регресії,
наприклад
![]() .
Нарешті, проводимо регресію
за
,
які не піддаються впливу (лінійному)
часу. Кутовий коефіцієнт у цій регресії
відображатиме істинний зв’язок між Y
і
X2
і повинен, отже, дорівнювати коефіцієнту
.
Зрозуміло, що перший метод більш
придатний, оскільки він менш трудомісткий.
.
Нарешті, проводимо регресію
за
,
які не піддаються впливу (лінійному)
часу. Кутовий коефіцієнт у цій регресії
відображатиме істинний зв’язок між Y
і
X2
і повинен, отже, дорівнювати коефіцієнту
.
Зрозуміло, що перший метод більш
придатний, оскільки він менш трудомісткий.
Для перевірки моделі (6.4) скористаємося даними, наведеними в табл. 6.1
Таблиця 6.1