

Пример и методические указания к выполнению работы.
Требуется на основе данных предыдущей лабораторной работы №2«Парный корреляционно-регрессионный анализ»:
построить степенную модель связи ВВП с уровнем инвестиций на душу населения;
рассчитать индекс корреляции R и детерминации R2;
оценить значимость модели по F-критерию Фишера;
сравнить по средней ошибке аппроксимации
 и F-критерию
Фишера качество двух моделей, выбрать
лучшую;
и F-критерию
Фишера качество двух моделей, выбрать
лучшую;По модели лучшего качества построить прогноз, дать его точечную и интервальную оценку с уровнем доверия 95%.
1). Построим степенную модель вида: .
Данная модель является нелинейной по параметрам и к линейному виду сводится логарифмированием:
.
Найдем натуральные логарифмы зависимой и независимой переменных, используя функцию «=ln()»:
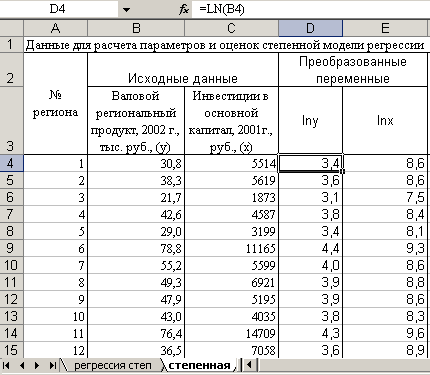

Далее, используя инструмент «Регрессия» найдем параметры преобразованного уравнения, причем в качестве значений Х и У следует дать ссылку на столбцы с логарифмами переменных. В итоге получим следующие результаты:
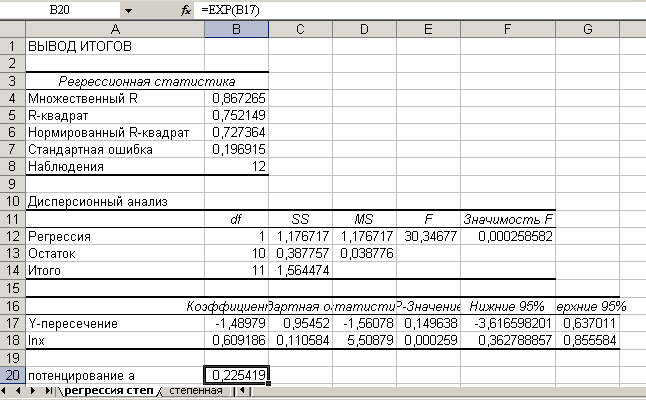

Следует иметь ввиду, что для получения параметра а исходного уравнения нужно провести потенцирование lna=-1,49, для этого используем функцию «exp()», где в скобках сделаем ссылку на lna. Параметр в потенцировать не нужно (b=0,61)
Вывод: В результате
получено уравнение степенной регрессии:
![]() 0,23х0,61.
Коэффициент
чистой регрессии (b=Э)
показывает, что при увеличении уровня
инвестиций на 1%, ВВП на душу населения
возрастет на 0,61%.
0,23х0,61.
Коэффициент
чистой регрессии (b=Э)
показывает, что при увеличении уровня
инвестиций на 1%, ВВП на душу населения
возрастет на 0,61%.
2) Рассчитаем индекс детерминации по формуле: .
Чтобы найти
остаточную дисперсию
![]() определим выравненные по уравнению
значения
определим выравненные по уравнению
значения
![]() ,
затем остатки е
их квадраты:
,
затем остатки е
их квадраты:
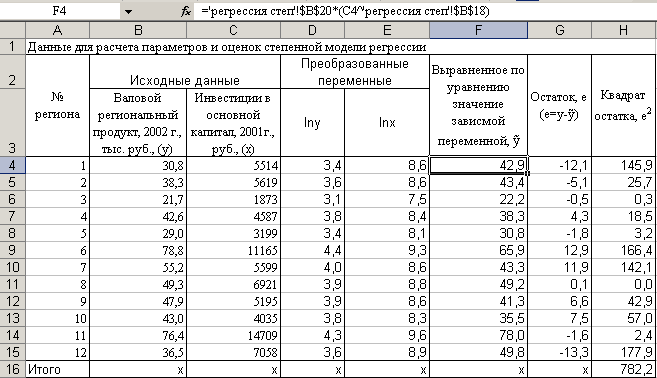

Далее найдем сумму квадратов остатков и определим :
![]() .
.
Дисперсию зависимой
переменной возьмем из предыдущих задач
(в нашем случае![]() ),
тогда:
),
тогда:
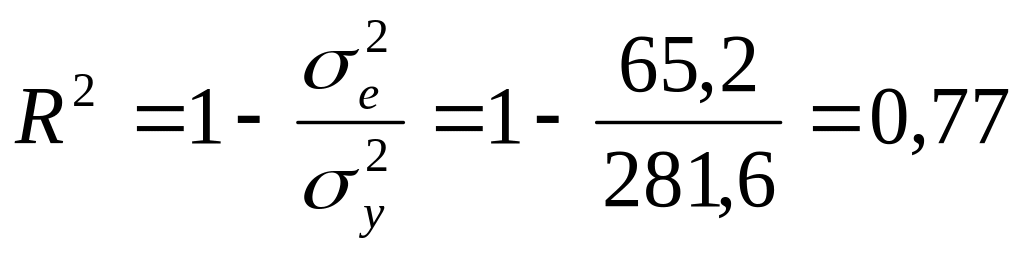 .
.
Корень из индекса детерминации индекс корреляции R=0,88.
Вывод: Теснота связи очень сильная (R=0,88), 77% вариации ВВП объясняется влиянием уровня инвестиций в расчете на душу населения.
3) Оценим значимость модели по F-критерию:
![]()
В данном случае m – это число параметров без условного начала, F критическое найдем с использованием функции «=fраспобр(α;p;n-p)», где p – число параметров, включая условное начало. В нашем случае fраспобр(0,05;2;10) дала результат 4,1. То есть можно сделать заключение о значимости уравнения в целом.
Средняя ошибка
аппроксимации (см. пример расчета в
зад.1) составила
![]() =14.9
%, т.е. она несколько меньше, чем по
линейной.
=14.9
%, т.е. она несколько меньше, чем по
линейной.
Чтобы сделать окончательный вывод о том, какая модель – степенная или линейная – лучше отображает взаимосвязи между переменными, выдвинем нулевую гипотезу о равенстве генеральных дисперсий ( ) и сравним остаточные генеральные дисперсии на основе расчета F-критерия:
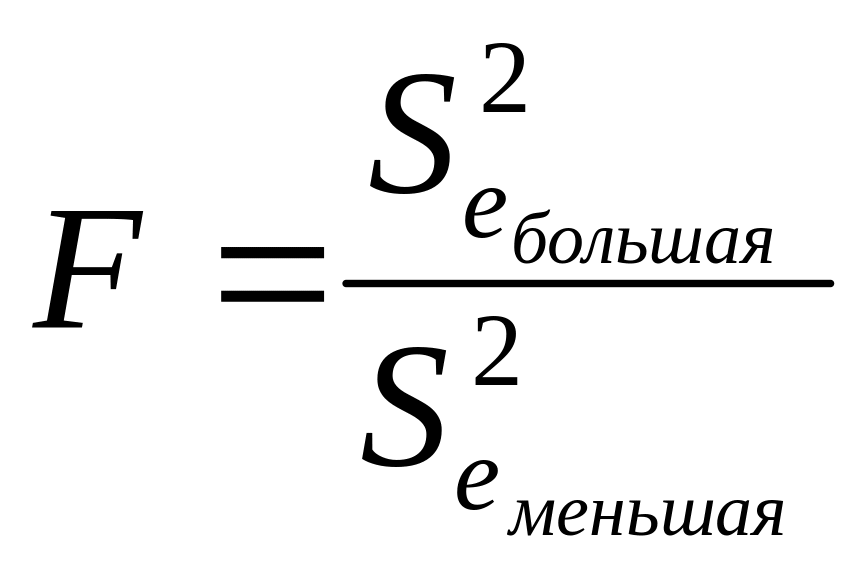 .
.
Расчет критерия необходим, поскольку исходные данные представлены выборкой и различия в остаточных дисперсиях могут находиться в пределах случайной ошибки. Определим несмещенные оценки дисперсий:
для степенной
модели
![]() ;
;
для линейной
модели
![]() =79,5
(см. таблицу с дисперсионным анализом
для линейной модели).
=79,5
(см. таблицу с дисперсионным анализом
для линейной модели).
В нашем случае большей является дисперсия, определенная по линейной регрессии, тогда:
![]() .
Критическое значение находится при
выбранном уровне значимости и остаточном
числе степеней свободы для большей (
)
и меньшей дисперсии (
):
.
Найдем критическое значение, используя
встроенную функцию: FРАСПОБР
.
Критическое значение находится при
выбранном уровне значимости и остаточном
числе степеней свободы для большей (
)
и меньшей дисперсии (
):
.
Найдем критическое значение, используя
встроенную функцию: FРАСПОБР![]() . В нашем случае выполнение
«=FРАСПОБР(0,05;10;10)» дало результат 3,0. То
есть, фактическое значение не превышает
критическое значение критерия – различия
в выборочных дисперсиях носят случайный
характер, и нельзя утверждать, что
степенная модель действительно лучше.
. В нашем случае выполнение
«=FРАСПОБР(0,05;10;10)» дало результат 3,0. То
есть, фактическое значение не превышает
критическое значение критерия – различия
в выборочных дисперсиях носят случайный
характер, и нельзя утверждать, что
степенная модель действительно лучше.
К тому же, различия между коэффициентами детерминации по степенной модели и линейной составили менее 0,1 (0,77-0,76=0,01), что еще раз подтверждает – нельзя утверждать, что степенная модель лучше отображает взаимосвязь. Предпочтение отдадим линейной функции и построим на ее основе прогноз.
5) При выборе прогнозных значений независимой переменной следует помнить, что чем больше отличается предполагаемое значение фактора от его среднего уровня, тем больше ошибка прогноза.
Предположим, что
инвестиции увеличатся на 10% по сравнению
со средним уровнем, т.е. хп=![]() тыс. руб.
на душу населения.
тыс. руб.
на душу населения.
Подставим хп в уравнение регрессии:
![]() тыс. руб., т.е. по
сравнению со средним уровнем (
тыс. руб., т.е. по
сравнению со средним уровнем (![]() тыс. руб.) прирост составит 2,7 тыс. руб.,
или 2,7/45,8∙100=6,0%.
тыс. руб.) прирост составит 2,7 тыс. руб.,
или 2,7/45,8∙100=6,0%.
Проведем точечную и интервальную оценку прогноза, для этого определим среднюю ошибку прогноза:
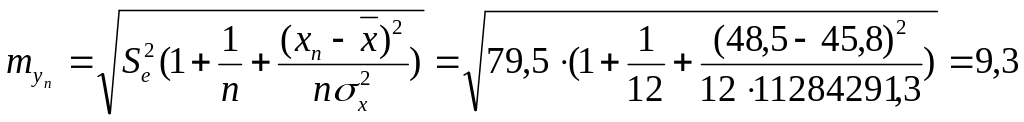 тыс.
руб.
тыс.
руб.
![]() -
остаточную дисперсию возьмем из таблицы
дисперсионного анализа в предыдущей
задаче,
-
остаточную дисперсию возьмем из таблицы
дисперсионного анализа в предыдущей
задаче,
![]() -
дисперсия инвестиций –по переменной
х – также
была определена
ранее.
-
дисперсия инвестиций –по переменной
х – также
была определена
ранее.
Точечная оценка:
прогнозное значение ВВП в генеральной
совокупности (![]() )
равно 48,5 со средней ошибкой 9,3 тыс. руб.
на душу населения.
)
равно 48,5 со средней ошибкой 9,3 тыс. руб.
на душу населения.
Проведем интервальную оценку прогноза в генеральной совокупности:
.
Для определения
критического значения
![]() ,
используется функция: =стьюдраспобр(α;v=n-m),
где n – число наблюдений, m
– число параметров, α – уровень значимости
критерия. В нашем случае расчет
критического уровня был произведен на
уровне значимости 5 % и остаточном числе
степеней свободы v=n-m=12-2=10:
=стьюдраспобр(0,05;10). В итоге
,
используется функция: =стьюдраспобр(α;v=n-m),
где n – число наблюдений, m
– число параметров, α – уровень значимости
критерия. В нашем случае расчет
критического уровня был произведен на
уровне значимости 5 % и остаточном числе
степеней свободы v=n-m=12-2=10:
=стьюдраспобр(0,05;10). В итоге
![]() (см.
предыдущую задачу).
(см.
предыдущую задачу).
Тогда, с уровнем
доверия 95% можно утверждать, что значение
прогноза в генеральной совокупности
заключено в пределах: от 27,8 до 69,2 тыс.
руб. (![]() ),
точность прогноза нельзя признать
удовлетворительной.
),
точность прогноза нельзя признать
удовлетворительной.